

引言:为什么我们需要向量数据库?
在人工智能高速发展的今天,我们每天都在与各种非结构化数据打交道:一段对话、一张图片、一首歌曲、一篇文档。传统数据库擅长处理“你是你,我是我”的精确匹配——比如通过ISBN号找书,但面对“找一本和《三体》风格相似的科幻小说”这类需求时,就显得力不从心。
这正是向量数据库大显身手的舞台。简单来说,向量数据库是专为“相似性”搜索而设计的数据库。它能让AI模型“理解”数据的深层含义,并根据语义或特征快速找到相似的内容。从智能客服、推荐系统,到当下火热的RAG(检索增强生成)应用,向量数据库都是背后不可或缺的技术基石。今天,我们就来彻底搞懂它。
一、技术原理:深入浅出看透向量数据库
1. 什么是向量?—— 数据的“数学指纹”
你可以把向量理解为一串数字构成的“指纹”。任何数据(文本、图片、语音)经过特定的AI模型(如BERT、CLIP)处理,都会被转换成一串数字,也就是向量或Embedding。
- 示例:句子“我爱人工智能”可能被转换为
[0.12, -0.45, 0.78, ..., 0.93]这样的数组。这串数字在高维空间中代表了这个句子的语义特征。
2. 核心工作流:从存到查的三步曲
向量数据库的核心流程非常直观:
- 编码入库:将你的原始数据(文档、图片)通过Embedding模型转化为向量,存入数据库。
- 构建索引:为海量向量建立高效的“导航地图”(索引),以便快速查找,而不是一个个比对。
- 相似检索:当用户输入查询(如一个问题)时,将查询也转化为向量,然后在“导航地图”中快速找出最相似的向量,并返回对应的原始数据。
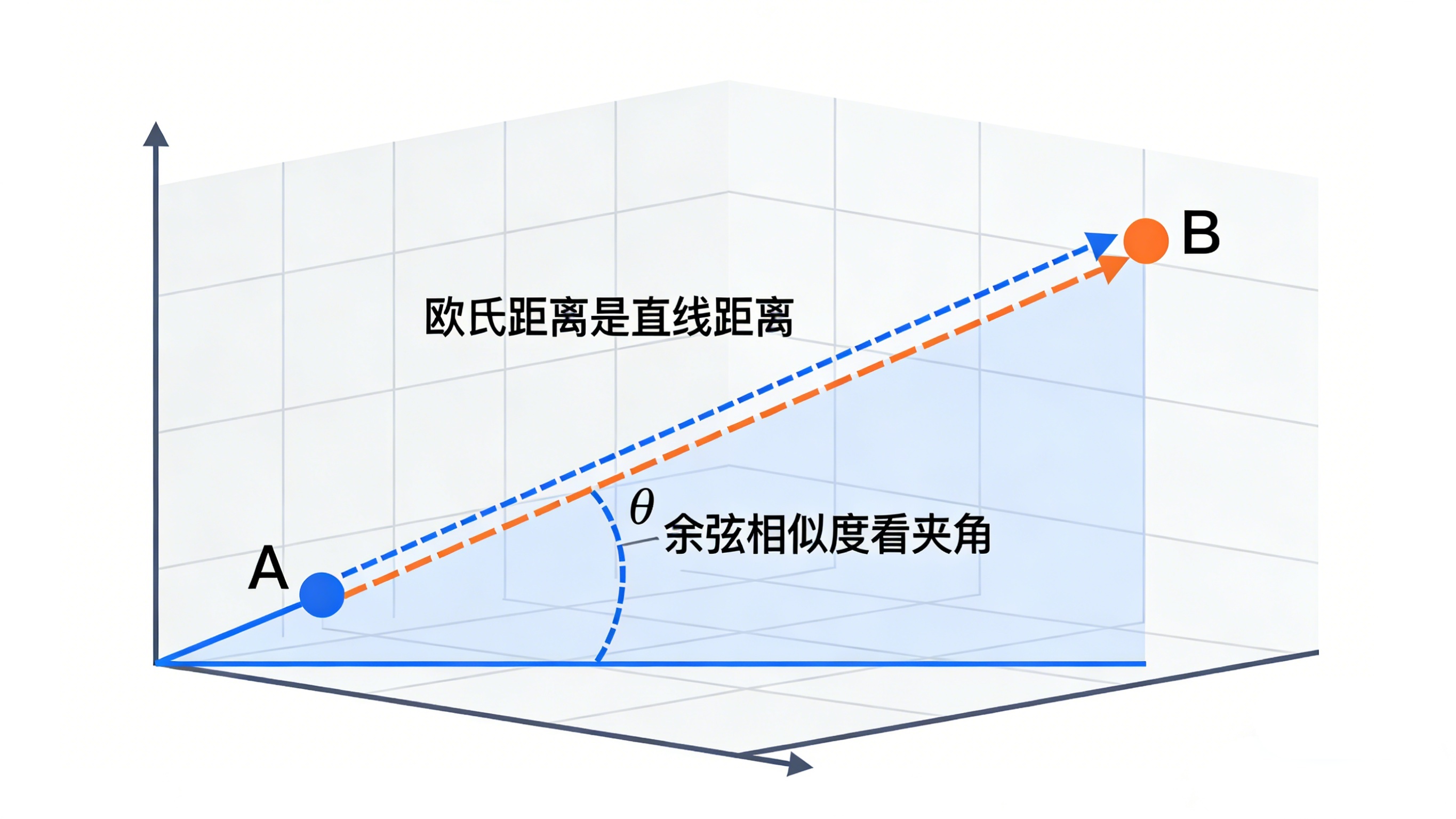
3. 如何衡量“相似”?—— 三大关键指标
判断两个向量是否相似,本质是计算它们在空间中的“距离”。最常用的三种方法是:
- 余弦相似度:最常用!只看方向,不看长度。特别适合比较文本语义。值从-1到1,1代表完全相同。
- 欧氏距离:经典的“直线距离”。既看方向,也看长度。适用于需要考虑绝对值的场景,如图像像素比较。
- 点积相似度:计算简单,但对向量长度敏感。通常在使用前会对向量进行归一化处理,使其效果接近余弦相似度。
![13413361041664947]()
4. 索引技术的智慧:如何在亿级数据中瞬间找到它?
在海量向量中精确比对每个向量是不现实的。因此,向量数据库采用“近似最近邻”搜索,用精度轻微损失换取巨大速度提升。主流索引技术有:
- HNSW(分层导航小世界) :当前综合性能最佳的明星算法。它像构建一个多层次的高速公路网,顶层是“国道”(快速定位大致区域),底层是“省道乡道”(精细搜索目标),实现了速度与精度的绝佳平衡。
- IVF(倒排文件索引) :采用“分而治之”思想。先用K-Means等算法把所有向量分成多个“簇”。搜索时,先找到离查询向量最近的几个簇,只在这几个簇内部精细搜索,大大缩小范围。
- PQ(乘积量化) :“有损压缩”大师。它将高维向量切分成子段并分别压缩,极大减少存储占用和计算量,适合对内存和速度要求极高的场景。
- LSH(局部敏感哈希) :核心思想是“让相似的向量拥有相同的哈希值”。它通过特殊的哈希函数,让相似的数据以高概率落入同一个“桶”中,搜索时只需比对同一个桶内的少量数据即可。
二、实践步骤:从零开始构建你的向量检索系统
理解了原理,我们来看看如何动手实践。一个完整的流程通常包括以下步骤:
步骤1:环境与工具准备
首先,你需要选择一款向量数据库。市面上有多种选择,从开源到云服务:
- 开源自建:Milvus、Qdrant、Weaviate等,功能强大,但对运维有要求。
- 云托管服务:Pinecone等,开箱即用,但可能有成本。
- 传统数据库扩展:使用PostgreSQL的
pgvector插件或Redis的搜索模块,适合已有技术栈且数据量不大的场景。
步骤2:数据准备与向量化
- 收集数据:整理你的非结构化数据,如PDF文档、产品描述、图片库。
- 选择Embedding模型:根据数据类型选择,文本常用
text-embedding-ada-002、BGE;图像可用CLIP。模型的选取直接影响后续检索质量。 - 生成向量:使用模型将每条数据转化为向量。例如,一段文本“Python是一种编程语言”会变成一个768维或1536维的向量。
步骤3:构建与加载向量索引
- 选择索引类型:根据你的数据规模(百万级?十亿级?)和性能要求(延迟?精度?)选择,如HNSW或IVF_PQ。
- 配置参数:如HNSW的
ef_construction(构建精度)、M(连接数),这些参数需要在构建速度和检索精度间权衡。 - 加载数据:将向量及其对应的原始文本/ID一同灌入数据库。
步骤4:实现查询与过滤
-
纯向量查询:将用户问题转化为向量,执行相似性搜索,返回Top K个结果。
-
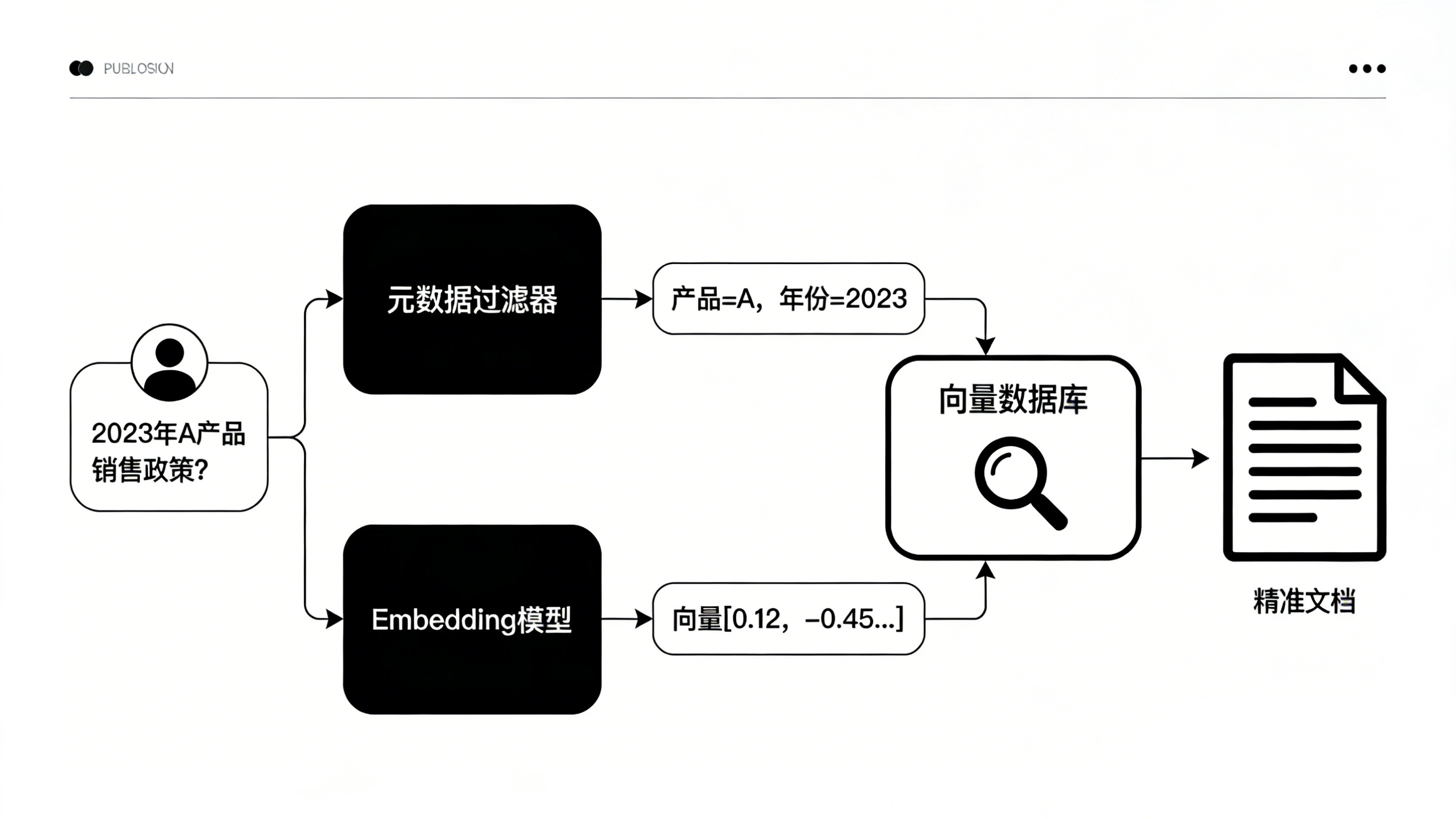
混合查询(关键!) :这是工业级应用的核心。结合元数据过滤进行检索,能大幅提升准确性。
- 示例:在企业知识库中,当用户问“2023年A产品的销售政策是什么?”时,系统应先在“产品名=A产品”且“年份=2023”的文档范围内做向量搜索,而不是全库搜索。这能有效避免语义相似但主题无关的干扰。
- 技术实现:向量数据库通常支持在查询时添加
where条件,进行预过滤或后过滤。
三、效果评估:如何验证你的向量检索系统?
搭建好系统后,如何判断它是否“聪明”?
-
定性评估(快速验证) :
- 输入一些典型问题,人工检查返回的结果是否相关、准确。
- 尝试“边界案例”,例如查询专业术语或含有歧义的问题,观察系统表现。
-
定量评估(核心指标) :
- 召回率:在所有应该被检索出的相关项目中,系统实际找出了多少?比例越高越好。
- 准确率:在系统返回的结果中,真正相关的有多少?比例越高越好。
- 响应延迟:从发起查询到得到结果所需的时间,直接影响用户体验。
- 吞吐量:系统每秒能处理的查询数量。
-
A/B测试:
- 在生产环境中,对比新系统与旧系统(或不同参数配置)的效果,用真实的用户点击率、满意度等数据来评判优劣。
四、总结与展望
总结一下:向量数据库通过将数据转化为“数学指纹”(向量),并利用高效的索引技术,实现了基于语义的毫秒级相似性检索。它弥补了传统数据库在处理非结构化数据时的短板,是构建智能应用(如RAG、推荐系统、内容去重)的必备组件。
未来展望:
- 多模态融合:未来的向量数据库将能更好地统一处理文本、图像、音频、视频的跨模态检索,实现“用文字搜图片”或“用图片找文档”。
- 智能化升级:索引参数可能实现自适应调整,数据库能根据查询模式自动优化。
- 深度集成:与AI训练、微调流程结合得更紧密,形成从数据处理、模型优化到智能检索的完整闭环。例如,你可以利用自己的业务数据微调一个专属的Embedding模型,生成更贴合业务场景的向量,再存入向量数据库,从而获得远超通用模型的检索精度。这正是LLaMA-Factory Online这类平台所致力于解决的问题:让没有代码基础的用户也能通过低门槛的方式,将自己的数据真正“喂”进模型,生产出属于自己的专属模型,在实践中理解如何让AI“更像你想要的样子” 。
给初学者的建议:不要被纷繁的算法细节吓倒。先从理解核心概念(向量、相似度、索引)开始,然后选择一个易上手的工具(无论是开源数据库还是在线平台),用一个小型项目(如个人知识库问答)入手,亲自走完从数据准备、向量化、检索到评估的全流程。实践,是理解这项技术最好的方式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号