

引言:为什么微调正在改变AI应用的游戏规则?
想象一下,你刚刚招聘了一位毕业于顶尖大学的通才助手——他懂文学、会编程、了解历史、还能聊科学。但当你需要他专门处理公司的财务报表时,他却显得有些力不从心。这时你有两个选择:花数年时间从头培养一个财务专家,或者用几个月时间对这位通才进行财务专项培训。显然,后者是更明智的选择。
这正是大模型微调(Fine-tuning)的核心价值所在。在AI领域,我们不再需要为每个特定任务从头训练一个全新的模型,而是可以在已经“通识教育”过的预训练大模型基础上,进行针对性的“专项培训”。这种方法不仅大幅降低了时间和金钱成本,更让中小企业甚至个人开发者都能拥有定制化AI能力。
无论是让ChatGPT学会你的企业文档风格,还是让文生图模型掌握特定的艺术风格,亦或是让语音识别模型适应你的行业术语——微调技术正在让“通用AI”变为“专属AI”,成为当前AI应用落地最热门、最实用的技术路径。
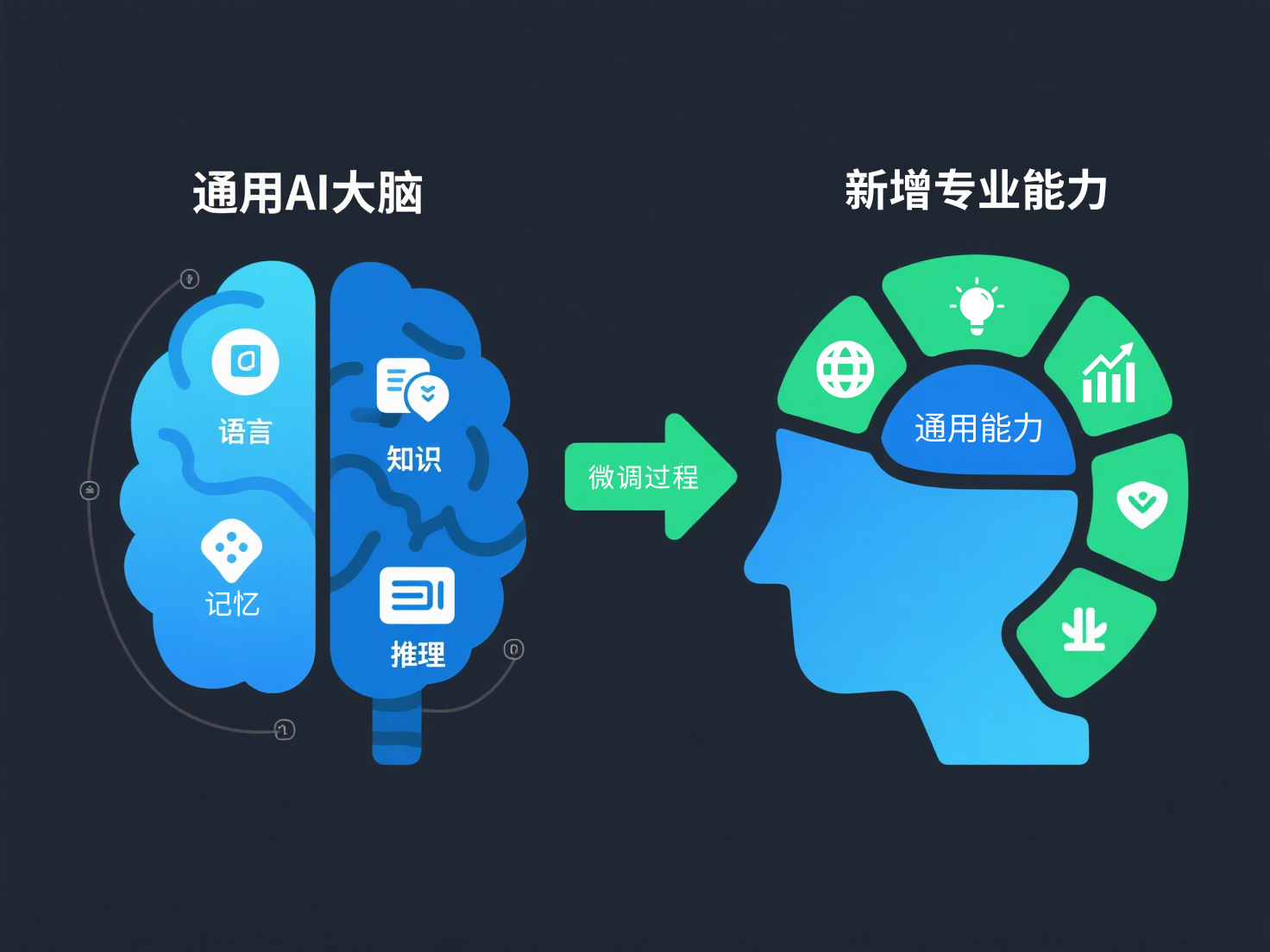
一、技术原理:深入浅出理解微调的本质
1.1 预训练 vs 微调:AI的“通识教育”与“专业深造”
预训练(Pre-training) 就像让AI接受“通识教育”:
- 使用海量互联网数据(数百GB甚至TB级别)
- 学习语言的通用模式、世界知识、推理能力
- 形成“基础智力”,但缺乏专业深度
- 成本极高:GPT-3训练成本约460万美元
微调(Fine-tuning) 则是“专业深造”:
- 使用少量专业数据(通常只需几百到几千条样本)
- 在预训练模型基础上调整参数
- 让模型掌握特定领域的知识和技能
- 成本极低:通常是预训练的1%甚至更少
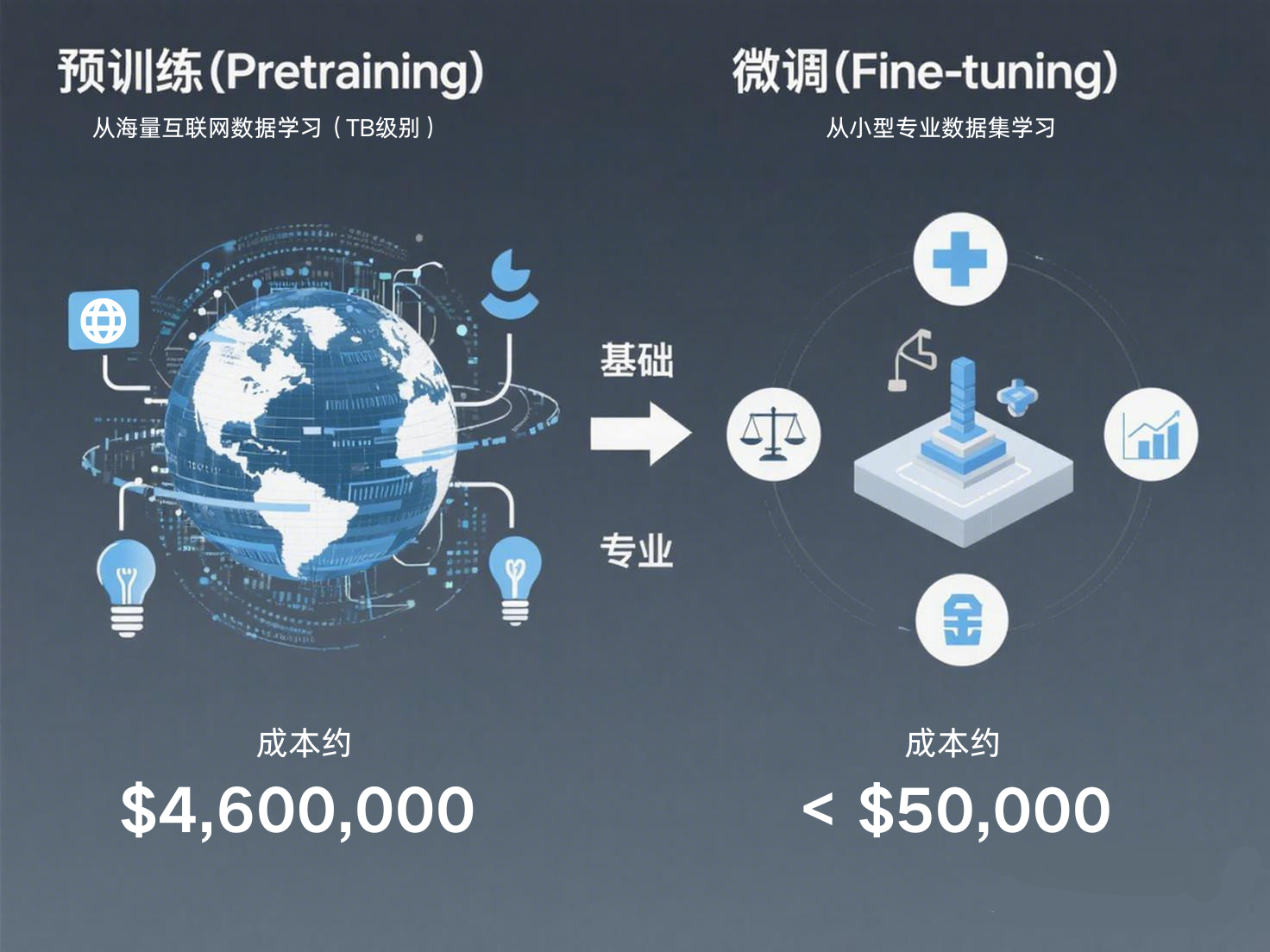
1.2 微调的两种模式:全量微调 vs 高效微调
全量微调(Full Fine-tuning)
- 比喻:转学到更好的学校,重新学习所有课程
- 操作:解冻模型所有权重参数,用新数据重新训练
- 优点:效果通常更好
- 缺点:需要较多计算资源,容易过拟合
高效微调(Parameter-Efficient Fine Tuning, PEFT)
- 比喻:在原学校参加“强化班”,只重点学习部分课程
- 代表技术:LoRA、Adapter、Prefix Tuning等
- 操作:冻结大部分原始参数,只训练少量新增参数
- 优点:节省90%以上显存,训练更快,避免灾难性遗忘
- 缺点:性能可能略低于全量微调
如果你刚接触模型训练,推荐使用像 LLaMA-Factory Online 这类平台,它能可视化训练过程、比较不同配置效果,本质上是在把 GPU 资源、训练流程和模型生态做成“开箱即用”的能力,让用户可以把精力放在数据和思路本身,而不是反复折腾环境配置,是提升微调效率的利器。
1.3 微调的技术本质:参数调整的艺术
微调的核心原理可以用一个简单公式理解:
新模型 = 预训练模型 + Δ参数调整
这里的Δ(增量)就是我们通过新数据对模型做出的改变。神经网络中的每个参数都像是一个“旋钮”,预训练已经把这些旋钮调到了通用任务的合适位置,微调则是根据特定任务进行精细调整。
关键机制:梯度传播与参数冻结
python
# 简单理解:哪些参数“可训练”,哪些“被冻结”
for param in model.parameters():
if "需要调整" in param.name:
param.requires_grad = True # 这个参数可以调整
else:
param.requires_grad = False # 这个参数被冻结
当requires_grad=False时,该参数在训练中不会收到梯度更新,保持不变。这就是部分微调的实现基础。
二、实践步骤:手把手完成你的第一次微调
微调工作流程图一览
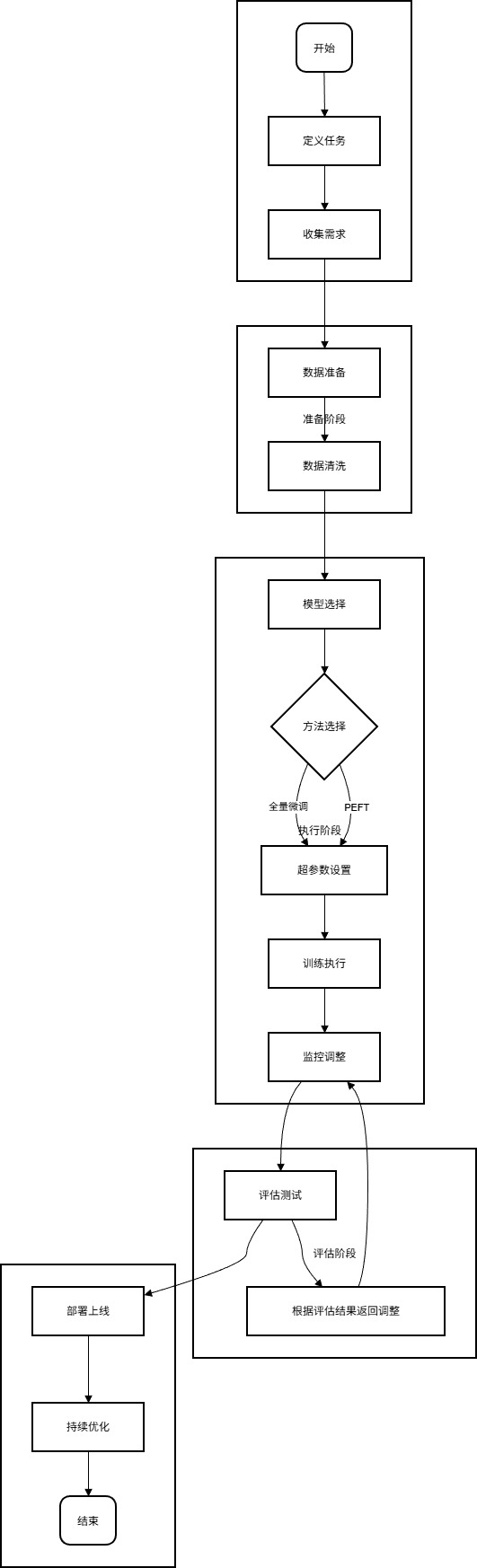
2.1 准备工作:环境与工具
硬件要求:
- 最低配置:8GB显存的GPU(如RTX 3070)
- 推荐配置:24GB+显存(可微调更大模型)
- 云端选择:Google Colab Pro、AWS、AutoDL等
软件栈:
bash
# 核心库安装
pip install torch transformers datasets
pip install peft accelerate # 高效微调库
pip install trl # 强化学习微调
2.2 步骤一:明确目标与数据准备
确定微调目标:
- 任务类型:文本分类、问答、代码生成、对话等
- 领域特性:法律、医疗、金融、电商等
- 数据规模:最少需要100-1000条高质量样本
数据准备指南:
python
# 数据格式示例(对话微调)
dataset = [
{
"instruction": "用专业术语解释量子计算",
"input": "",
"output": "量子计算利用量子比特的叠加态..."
},
{
"instruction": "将以下文本翻译成英文",
"input": "今天天气很好",
"output": "The weather is nice today."
}
]
# 关键原则:
# 1. 多样性:覆盖任务的不同场景
# 2. 质量优先:人工审核确保准确性
# 3. 格式统一:符合模型训练要求
2.3 步骤二:选择与加载基础模型
模型选择策略:
- 通用任务:Llama 2、ChatGLM、Qwen等
- 代码相关:CodeLlama、StarCoder
- 中文优先:Qwen、ChatGLM、Baichuan
模型加载代码:
python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen-7B-Chat" # 以通义千问为例
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16, # 半精度节省显存
device_map="auto" # 自动分配到可用GPU
)
2.4 步骤三:配置微调方法(以LoRA为例)
LoRA(Low-Rank Adaptation)是目前最受欢迎的高效微调方法:
python
from peft import LoraConfig, get_peft_model
# LoRA配置
lora_config = LoraConfig(
r=8, # 低秩矩阵的秩,控制参数数量
lora_alpha=32, # 缩放系数
target_modules=["q_proj", "v_proj"], # 针对注意力层的Q、V矩阵
lora_dropout=0.1,
bias="none",
task_type="CAUSAL_LM"
)
# 应用LoRA
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # 查看可训练参数比例
# 输出:trainable params: 8,388,608 || all params: 6,742,609,920 || 0.12%
2.5 步骤四:训练配置与执行
python
from transformers import TrainingArguments, Trainer
from datasets import load_dataset
# 加载数据
dataset = load_dataset("json", data_files="your_data.json")
# 训练参数配置
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3, # 微调通常3-5轮足够
per_device_train_batch_size=4, # 根据显存调整
gradient_accumulation_steps=8, # 模拟更大batch size
learning_rate=2e-4, # 微调学习率较小
warmup_steps=100,
logging_steps=50,
save_steps=500,
fp16=True, # 混合精度训练节省显存
push_to_hub=False, # 可上传到Hugging Face Hub
)
# 创建训练器
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset["train"],
tokenizer=tokenizer,
data_collator=lambda data: {
"input_ids": torch.stack([f["input_ids"] for f in data]),
"attention_mask": torch.stack([f["attention_mask"] for f in data]),
"labels": torch.stack([f["input_ids"] for f in data]),
}
)
# 开始训练
trainer.train()
# 保存模型
model.save_pretrained("./fine_tuned_model")
tokenizer.save_pretrained("./fine_tuned_model")
2.6 步骤五:模型测试与部署
python
# 加载微调后的模型
from peft import PeftModel
base_model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat")
model = PeftModel.from_pretrained(base_model, "./fine_tuned_model")
# 合并LoRA权重(可选,提高推理速度)
model = model.merge_and_unload()
# 测试推理
inputs = tokenizer("用专业语气回复客户咨询:", return_tensors="pt")
outputs = model.generate(**inputs, max_length=200)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
三、效果评估:如何判断微调是否成功?
3.1 定量评估指标
文本生成任务:
- 困惑度(Perplexity) :越低越好,表示模型对数据更确定
- BLEU/ROUGE分数:与参考文本的相似度
- 任务特定指标:准确率、F1分数等
代码示例:
python
from evaluate import load
# 计算困惑度
perplexity = load("perplexity", module_type="metric")
results = perplexity.compute(
predictions=generated_texts,
model_id="gpt2",
batch_size=4
)
print(f"困惑度: {results['mean_perplexity']:.2f}")
3.2 定性评估方法
人工评估清单:
- 相关性:回答是否切题?
- 专业性:是否使用领域术语?
- 一致性:风格是否符合要求?
- 创造性:能否处理未见过的查询?
AB测试流程:
python
def compare_models(question):
base_response = base_model.generate(question)
tuned_response = tuned_model.generate(question)
print("原始模型:", base_response)
print("微调后:", tuned_response)
# 人工评分或自动评分
3.3 过拟合检测与应对
警告信号:
- 训练损失持续下降,但验证损失上升
- 模型在训练数据上表现完美,但新数据上差
- 生成内容缺乏多样性
应对策略:
- 增加数据多样性
- 使用早停法(Early Stopping)
- 调整学习率或使用学习率调度
- 增加Dropout或权重衰减
四、微调的最佳实践与常见陷阱
4.1 最佳实践清单
✅ 数据质量 > 数据数量:1000条高质量数据 > 10000条噪音数据
✅ 从小开始:先用小规模数据和短时间训练验证流程
✅ 持续评估:每训练一段时间就测试模型表现
✅ 版本控制:保存不同阶段的模型,方便回滚
✅ 文档记录:记录所有超参数和数据变化
4.2 常见问题与解决方案
| 问题 | 可能原因 | 解决方案 |
|---|---|---|
| 训练后模型变笨了 | 灾难性遗忘 | 使用LoRA等PEFT方法;在通用数据上混合训练 |
| 显存不足 | 模型太大/批次太大 | 使用梯度累积;启用量化训练;切换到PEFT |
| 生成内容重复 | 训练数据单一 | 增加数据多样性;调整temperature参数 |
| 收敛太慢 | 学习率不当 | 使用学习率探测器;调整学习率调度 |
五、未来展望:微调技术的演进方向
5.1 技术趋势
更高效的微调方法:
- QLoRA:4位量化的LoRA,进一步降低显存需求
- DoRA:权重分解的低秩适应,效果媲美全量微调
- 自适应微调:根据任务难度动态调整微调强度
自动化微调:
- AutoPEFT:自动选择最优的PEFT配置
- Few-shot微调:仅用几个样本就能有效微调
- 无监督微调:无需标注数据的微调方法
5.2 应用前景
企业级应用:
- 私有知识库+大模型=企业智能客服
- 行业文档+大模型=专业分析助手
- 代码库+大模型=个性化编程搭档
个人开发者机遇:
- 微调特定领域模型,提供API服务
- 创建垂直领域AI应用,解决细分需求
- 开发微调工具和平台,降低技术门槛
总结:从消费者到创造者的转变
微调技术正在 democratize AI——它让AI能力不再是科技巨头的专属,而是每个开发者都能掌握的工具。通过本文,你已经了解了:
- 微调的核心价值:低成本、高效率地定制AI能力
- 技术实现路径:从PEFT到全量微调的多层次选择
- 完整实践流程:从数据准备到模型部署的全链路
- 效果验证方法:确保微调真正产生价值
最令人兴奋的是,微调只是开始。随着工具链的不断完善,未来每个人都能像使用Photoshop调整图片一样,轻松地“调整”AI模型以适应自己的需求。无论你是想创建一个懂你业务的客服助手,还是一个理解你代码风格的编程伙伴,或是掌握你公司知识的知识库专家——微调都是你实现这些目标的最短路径。
现在,你不再只是AI技术的消费者,更是创造者。选择一个问题,准备一些数据,开始你的第一次微调实验吧。那个更懂你的AI,正等待被你创造出来。
行动指南:
- 从Hugging Face选择一个适合的基础模型
- 收集或创建100-200条高质量数据
- 在Google Colab上运行你的第一个微调实验
- 分享你的成果到AI社区,获得反馈
微调的世界已经向你敞开大门,下一步,就是迈出你的第一步。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号