

一、引言:当大模型需要“更懂人心”
你是否曾惊叹于ChatGPT流畅自然的对话能力,或对GPT-4在复杂任务上的精准表现感到好奇?这些看似“智能”的背后,隐藏着一个关键技术环节——大模型与人类偏好的对齐。今天,我们就来深入探讨实现这一目标的核心算法:近端策略优化(PPO) 。
为什么大模型需要“再训练”?
想象一下,你请了一位学识渊博但性格直率的教授来当客服。他知识丰富,但说话可能太专业、不够友好,甚至偶尔冒犯用户。监督微调(SFT)就像教这位教授基本的服务礼仪和话术,让他学会如何说话。但真正的“优秀客服”,还需要懂得察言观色、理解用户隐含需求、在不同情境下调整沟通方式——这就是学会如何说好话。
PPO正是让大模型从“合格”走向“优秀”的关键技术。它通过强化学习,让模型在与环境的交互中不断优化,学习生成更符合人类期望的文本。从ChatGPT到GPT-4,几乎所有顶尖对话模型都离不开PPO的加持。
PPO的应用版图
| 应用场景 | 核心目标 | PPO如何助力 |
|---|---|---|
| 对话系统 | 让回复更自然、相关、有用 | 学习人类对话偏好,优化回复质量 |
| 内容安全 | 降低有害、偏见内容生成概率 | 通过安全奖励模型引导模型“避坑” |
| 专业助手 | 提升代码生成、数据分析等专项能力 | 针对特定任务设计奖励信号 |
| 创意写作 | 平衡创意性与可控性 | 学习风格偏好,保持创意同时符合要求 |
二、技术原理:PPO如何让模型“更懂你”
2.1 核心思想:既要进步,也要稳定
PPO的名字就揭示了其核心思想:
- 近端(Proximal) :每次更新只迈“一小步”,避免训练崩溃
- 策略优化(Policy Optimization) :优化模型生成文本的策略
通俗理解:教练教你打网球时,不会让你完全改变发球动作,而是在现有基础上微调手腕角度、发力时机。这样既能进步,又不会因改变太大而失去原本的优势。
2.2 四重奏:PPO微调的四大角色
PPO微调不是单一模型的训练,而是一个多模型协作系统:
1. Actor Model(演员模型)
- 角色:需要微调的主角,负责生成文本
- 任务:根据用户输入生成回复,并不断优化策略以获得更高奖励
- 类比:网球场上练习的选手,不断尝试新的击球方式
2. Reference Model(参考模型)
- 角色:Actor的“旧版本”,参数被冻结
- 作用:提供稳定性保障,防止模型“跑偏”
- 关键技术:通过KL散度计算,确保新策略不会过度偏离原始能力
- 类比:选手的标准动作录像,作为调整的参照系
3. Reward Model(奖励模型)
- 角色:评判员,学习人类偏好
- 作用:对生成的文本打分,反映其符合人类期望的程度
- 训练方式:通过人类对多个回复的排序数据训练
- 类比:网球裁判,对每个击球动作给出即时评分
4. Critic Model(评论家模型)
- 角色:策略评估专家
- 作用:预测当前状态下的长期价值,计算“优势”
- 价值:提供更稳定、精细的优化信号,减少训练波动
- 类比:经验丰富的教练,能预测选手当前策略的长期效果
![13413357343651950]()
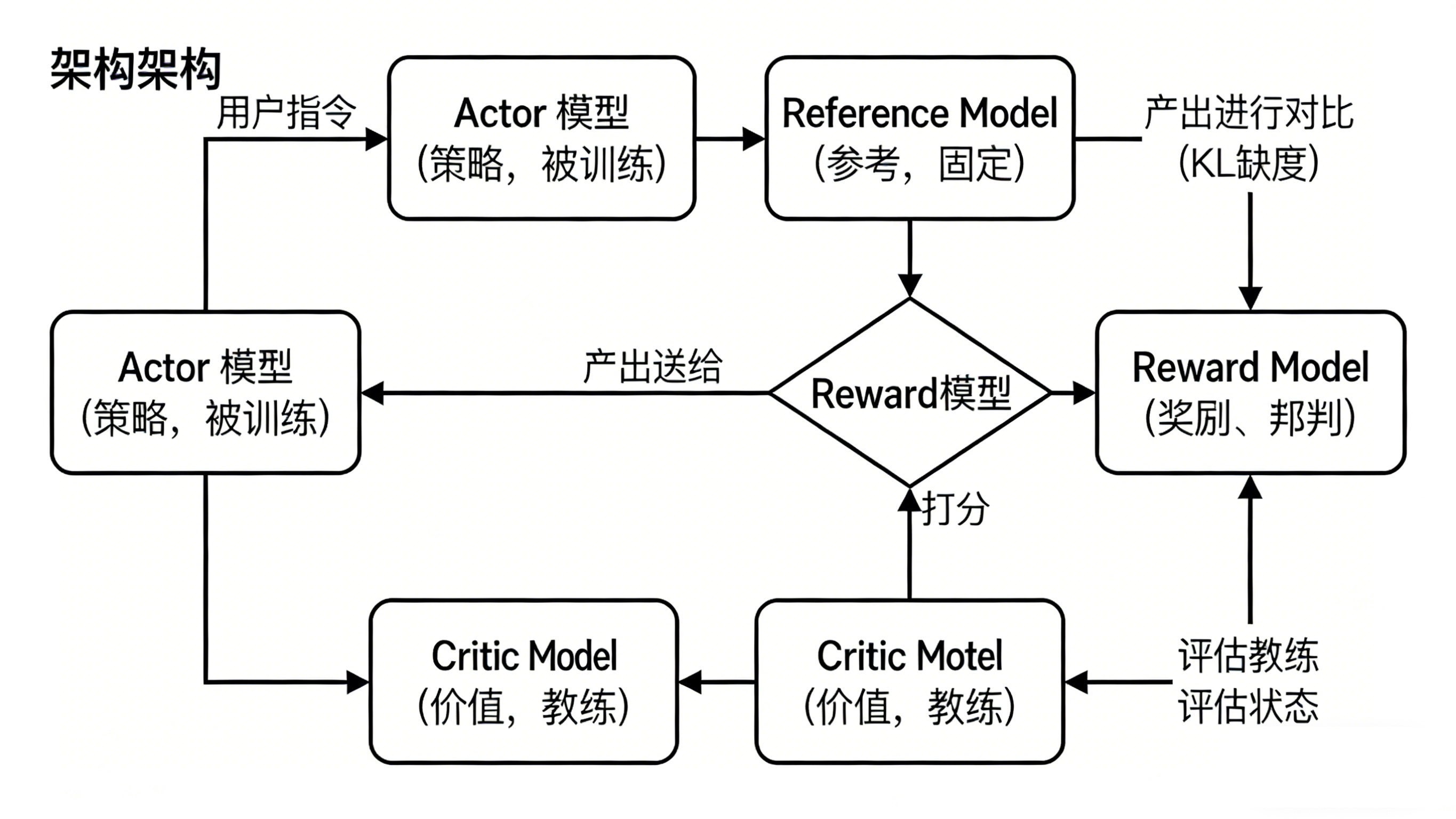
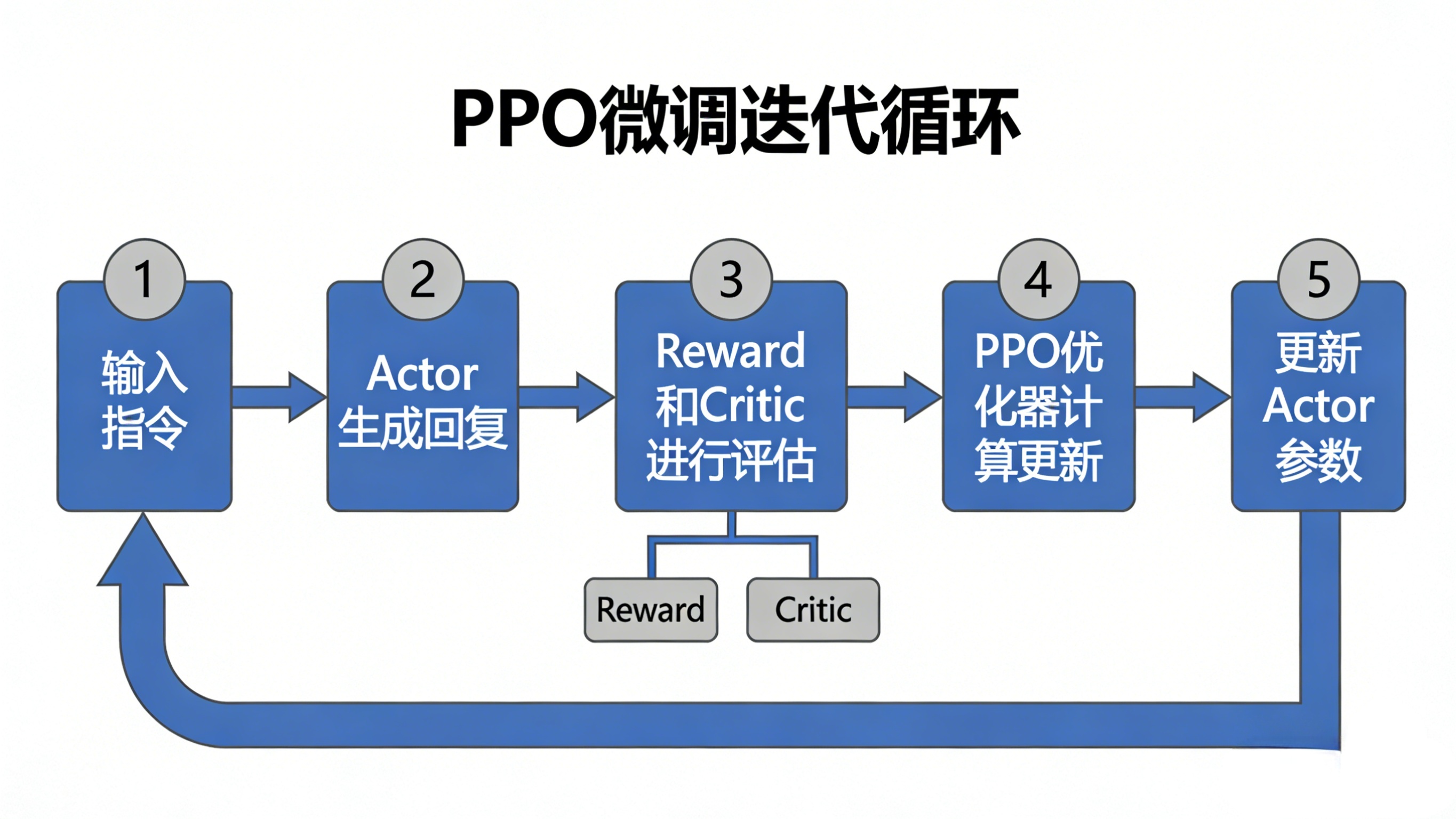
2.3 完整训练流程:一场精密的协作
text
用户输入 → Actor生成回复 → Reward打分 + Critic评估 → 计算优势与KL惩罚 → PPO优化器更新
↑ ↓
←←←←←←←←←←←←←←←←←←←←←←←←←←←←←←←←←←←←←←←←←←←←←
优势计算:A = 即时奖励 + 未来奖励预测 - 当前价值预测
- 正优势:超常发挥,应加强类似策略
- 负优势:表现不佳,应减少类似策略
KL惩罚:确保Actor的输出分布与Reference不会相差太远
三、实践指南:三步完成PPO微调
3.1 准备工作:模型与数据
基座模型选择
text
选择建议:
├── 追求最佳效果:GPT、Claude、Qwen等顶尖闭源/开源模型
├── 资源有限:Llama-7B、Qwen2.5-3B等轻量级模型
└── 中文优化:Baichuan、ChatGLM、Qwen系列
数据准备
python
# 数据格式示例(JSONL)
{
"instruction": "写一首关于春天的诗",
"input": "",
"output": "春风拂面花香浓,...",
"chosen": "这首诗意境优美", # 人类偏好的回复
"rejected": "这首诗比较普通" # 相对较差的回复
}
数据要求:
- 数量:至少1000条高质量对比数据
- 质量:确保标注一致,避免矛盾
- 多样性:覆盖目标场景的各种情况
3.2 三阶段训练流程
第一阶段:监督微调(SFT)
text
目标:让模型掌握基础任务能力
方法:在指令-回复数据上微调
时间:通常1-3个epoch
第二阶段:训练奖励模型(RM)
yaml
# 关键配置
reward_model_type: "full" # 或"lora"
loss_type: "pairwise" # 对比学习
learning_rate: 1e-5
Lora vs Full微调:
- Lora:参数高效,适合资源有限场景
- Full:效果更好,需要更多显存
第三阶段:PPO强化学习
yaml
ppo_config:
learning_rate: 1e-6
batch_size: 32
gradient_accumulation_steps: 4
kl_penalty: "adaptive" # 自适应KL惩罚
clip_range: 0.2 # PPO裁剪范围
3.3 实战操作:以Llama-Factory为例
bash
# 1. 环境准备
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -r requirements.txt
# 2. 数据准备
python scripts/prepare_data.py --data_dir ./data
# 3. 训练奖励模型
python src/train_rm.py \
--model_name_or_path meta-llama/Llama-2-7b-chat \
--dataset your_dataset \
--output_dir ./models/rm_model
# 4. PPO微调
python src/train_ppo.py \
--actor_model ./models/sft_model \
--reward_model ./models/rm_model \
--dataset your_dataset \
--output_dir ./models/ppo_model
觉得命令行操作太复杂? LLaMA-Factory Online 提供了可视化界面,你只需:
- 上传数据集
- 选择基座模型
- 配置训练参数(或使用推荐配置)
- 点击开始训练
- 实时查看训练进度和效果
即使没有任何代码基础,也能在30分钟内启动你的第一个PPO微调任务。
3.4 常见问题与解决方案
Q1:训练过程中reward分数一直下降?
- 可能原因:KL惩罚过强
- 解决方案:降低
kl_coef,或使用自适应KL惩罚
Q2:显存不足怎么办?
-
策略:
- 使用梯度累积(
gradient_accumulation_steps) - 采用Lora微调
- 降低
batch_size - 使用
flash_attention加速
- 使用梯度累积(
Q3:训练不稳定,波动大?
-
检查:
- 学习率是否过高
- 奖励模型是否过拟合
- 数据质量是否一致
四、效果评估:如何验证你的微调成果
4.1 自动评估指标
python
# 常用评估脚本示例
def evaluate_model(model, test_dataset):
metrics = {
"reward_score": [], # 奖励模型打分
"kl_divergence": [], # 与参考模型的KL散度
"length": [], # 生成文本长度
"bleu": [], # 与参考回复的相似度
"diversity": [] # 生成多样性
}
for sample in test_dataset:
output = model.generate(sample["instruction"])
metrics["reward_score"].append(reward_model(output))
# ... 计算其他指标
return metrics
4.2 人工评估维度
| 维度 | 评估标准 | 权重建议 |
|---|---|---|
| 有用性 | 回复是否解决了问题 | 30% |
| 相关性 | 是否紧扣用户问题 | 25% |
| 安全性 | 是否包含有害内容 | 20% |
| 流畅性 | 语言是否自然通顺 | 15% |
| 创造性 | 是否有独特见解 | 10% |
4.3 A/B测试框架
text
对照组:原始SFT模型
实验组:PPO微调后的模型
评估方式:
1. 准备测试集(100-200条)
2. 两组模型分别生成回复
3. 人工标注员盲评(不知道哪个是哪个模型生成的)
4. 统计偏好率:PPO模型胜出的比例
五、进阶技巧与最佳实践
5.1 奖励模型设计的艺术
多维度奖励
python
# 复合奖励函数示例
def composite_reward(text):
safety_score = safety_model(text) * 0.3
helpfulness_score = helpfulness_model(text) * 0.4
fluency_score = fluency_model(text) * 0.2
relevance_score = relevance_model(text) * 0.1
return (safety_score + helpfulness_score +
fluency_score + relevance_score)
奖励塑造(Reward Shaping)
- 即时奖励:当前回复的质量
- 稀疏奖励:任务完成的最终奖励
- 课程学习:从简单任务开始,逐步增加难度
5.2 避免常见陷阱
陷阱1:奖励黑客(Reward Hacking)
- 现象:模型找到奖励函数的漏洞,生成高分但无意义的文本
- 预防:多维度评估、定期人工检查
陷阱2:过度优化
- 现象:KL散度过高,模型失去语言能力
- 预防:监控KL值,设置上限
陷阱3:奖励模型过拟合
- 现象:在训练集上表现好,但泛化差
- 预防:使用验证集早停、数据增强
5.3 资源优化策略
小资源大效果:
- Lora + 8bit量化:将70B模型微调显存需求从280GB降至40GB
- 知识蒸馏:用大模型指导小模型训练
- 参数共享:Actor和Critic共享部分层
六、总结与展望
6.1 核心要点回顾
- PPO不是单一算法,而是一个包含四个模型的协作系统
- 稳定性是关键:通过KL惩罚和裁剪机制避免训练崩溃
- 数据质量决定上限:高质量的人类偏好数据是成功的基础
- 迭代优化:PPO微调需要多次实验和调参
6.2 未来发展方向
技术演进
- 更高效的算法:DPO、RAFT等新方法正在挑战PPO的地位
- 多模态奖励:结合图像、语音等多维度反馈
- 在线学习:让模型在部署后继续从用户反馈中学习
应用扩展
- 个性化模型:为每个用户定制专属助手
- 领域专家:医疗、法律、教育等垂直领域深度优化
- 创意伙伴:与人类协作进行艺术创作、科学研究
6.3 给初学者的建议
学习路径:
text
第一阶段:理解概念(本文+经典论文)
第二阶段:动手实践(从SFT开始,再到PPO)
第三阶段:深入研究(读源码、复现论文)
实践建议:
- 从小开始:先用小模型、小数据跑通流程
- 善用工具:利用LLaMA-Factory等开源框架降低门槛
- 保持耐心:强化学习训练可能需要多次尝试
- 社区交流:加入相关社群,学习他人经验
6.4 最后的思考
PPO微调让大模型从“知识库”进化为“智能体”,从被动回答到主动理解。这项技术正在重塑我们与AI的交互方式,让机器不再是冷冰冰的工具,而是能理解我们、适应我们的伙伴。
无论你是研究者、开发者,还是对AI技术充满好奇的学习者,现在都是进入这个领域的最佳时机。工具已经就位,框架已经成熟,唯一缺少的,就是你的创意和数据。
准备好让你的模型“更懂你”了吗?从今天开始,从第一个微调任务开始,加入这场AI个性化革命吧!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号