
别光“调戏”ChatGPT了!亲手微调一个专属大模型,你需要知道这些
引言:为什么你需要了解这些?
想象一下,你面前有两个医生:
- 医生A:熟读全球所有医学教科书,掌握海量人体生理、病理知识。
- 医生B:不仅拥有医生A的全部知识,还在顶级三甲医院的心外科,跟着专家团队进行了上万台手术的专项训练。
当你只是普通感冒时,两位医生都能给出正确建议。但当你面临一个复杂的心脏瓣膜手术时,你会毫不犹豫地选择医生B。
大模型的“训练-微调-推理”过程,本质上就是培养出“医生B”的过程。
- 训练,是让模型“博览群书”,具备通用知识和逻辑能力。
- 微调,是让这个通才在特定领域(法律、医疗、客服、代码)进行“专项进修”,成为专才。
- 推理,则是这位专才真正为你“坐诊”,解决具体问题的过程。
理解这三步,你不仅能明白大模型能力的来源,更能掌握将前沿AI能力“私有化”、“专业化”的钥匙,无论是优化业务还是创造新产品,都至关重要。
第一章:技术原理 - 三步打造一个AI专家
1. 大模型训练:建造一座“全人类知识图书馆”
你可以把大模型想象成一个容量惊人的空书架。训练,就是往这个书架上系统地填充海量书籍(数据),并教会模型理解书籍之间内在联系的过程。
- 预训练(Pre-training) :这是最基础、最耗资源的阶段。模型(如DeepSeek-V3-Base)在数万亿计的、无标注的通用文本(网页、书籍、代码等)上进行学习。它像一个聪明的婴儿,通过“完形填空”(预测被遮住的词)、“下一句预测”等自监督任务,纯粹从文本结构中学到语法、事实、常识和逻辑推理能力。结果是:一个“通才”模型诞生了。
- 后训练(Post-training) :预训练模型虽然知识渊博,但“性格”和行为可能不稳定,回答可能冗长或不安全。后训练由模型开发者进行,通过监督微调(SFT) 和人类反馈强化学习(RLHF) 等方式,用高质量的人类示范和偏好数据“雕琢”模型,使其输出更符合人类习惯、更安全、更有帮助。结果是:一个“可用”且“行为良好”的通用模型,如ChatGPT、DeepSeek-R1。
2. 大模型微调:把“通才”培养成“专科医生”
微调其实是后训练的一种,但主角变成了我们使用者。当我们拿到一个像DeepSeek-R1这样优秀的通用模型后,如何让它精通我们的内部知识库,或具备专业的客服话术呢?这就是微调的价值。
-
核心思想:在保留模型99%通用能力(医学基础、问诊技巧)的基础上,用你特定领域(心外科病历)的少量数据,对模型进行“精修”,使其在该领域表现突飞猛进。
-
微调方法百花齐放:根据计算资源和目标的不同,我们有多种“精修”策略:
-
全量微调(Full Fine-Tuning) :相当于让医生重新学习所有知识,但重点是心外科资料。效果好,但“学习成本”(计算资源)极高,容易“学偏”(过拟合)。
-
参数高效微调(PEFT) :这才是目前的主流和推荐做法!我们只让模型“选修”几门新课程,大部分核心知识不动。既高效又安全。
- LoRA(明星方法) :给模型的“思维网络”加上一些轻量化的“补丁层”,只训练这些新加的“补丁”。资源消耗极小,效果接近全量微调。
- QLoRA(LoRA的增强版) :在LoRA的基础上,还把原模型的知识进行了“压缩”(量化),进一步降低对显存的要求。在消费级显卡上微调大模型成为可能!
-
3. 大模型推理:专家开始“坐诊”解题
推理就是模型利用所学知识,回答你问题的应用过程。当你向模型提问时:
- 解析问题:模型将你的问题转化为内部能理解的“思维向量”。
- 激活知识:在它庞大的“知识图书馆”中,快速检索与问题相关的“书架”(激活相关神经元和参数)。
- 逐步推理:像解一道数学题一样,结合检索到的知识,一步步推导(即Transformer架构的层层前向计算),生成下一个最可能的词,直至形成完整答案。
简单类比:训练=上大学读本科;微调=读硕士/博士,选定研究方向;推理=毕业后用所学知识解决工作难题。
第二章:实践步骤 - 亲手微调你的第一个大模型
理论懂了,我们来看如何动手。这里,我将以使用 LoRA 方法,在一台配备24G显存的消费级显卡(如RTX 4090)上,微调一个7B参数的模型为例,讲解核心步骤。
在实际实践中,如果只是停留在“了解大模型原理”,其实很难真正感受到模型能力的差异。我个人比较推荐直接上手做一次微调,比如用 LLaMA-Factory Online 这种低门槛大模型微调平台,把自己的数据真正“喂”进模型里,生产出属于自己的专属模型。即使没有代码基础,也能轻松跑完微调流程,在实践中理解怎么让模型“更像你想要的样子”。
步骤一:环境与数据准备
-
选择基础模型:从Hugging Face等平台下载一个开源的、适合你任务的基础模型,如
Qwen2.5-7B-Instruct或Llama-3.2-7B-Instruct。 -
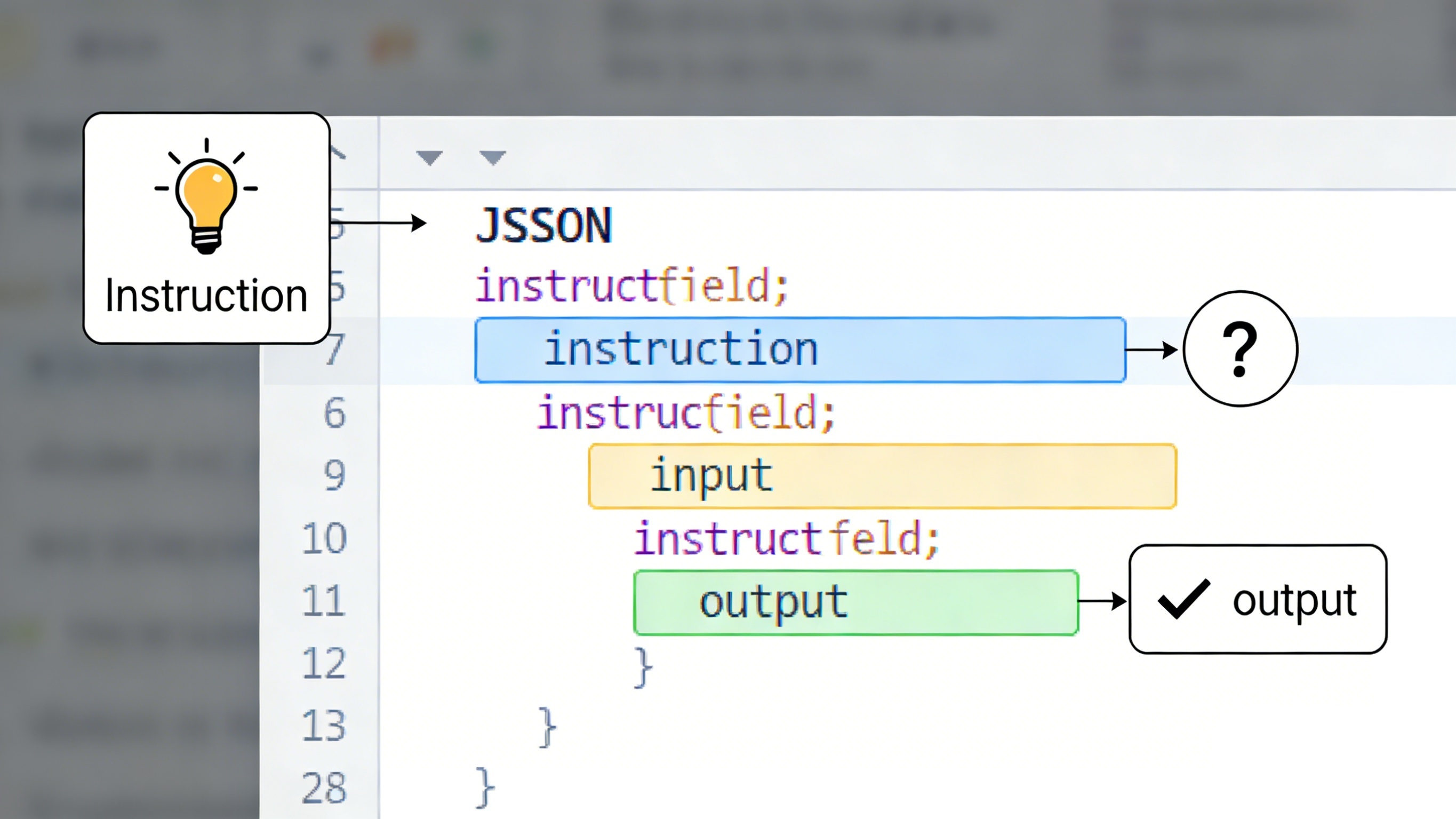
准备微调数据:这是最关键的一步!你需要将专业知识整理成 对话格式(Instruction-Input-Output) 的JSON文件。例如:
json
[ { "instruction": "请扮演一位专业的心理咨询师。", "input": "我感觉最近工作压力很大,经常失眠。", "output": "听起来你最近承受了不小的压力。失眠是身体在提醒我们需要关注自己的情绪。我们可以尝试先从建立规律的睡前放松习惯开始,比如睡前半小时远离手机,做一些轻柔的拉伸或听一些舒缓的音乐。你愿意和我多聊聊具体的工作情境吗?" } // ... 更多类似的数据样本,通常几百到几千条高质量数据就有效果 ]
- 搭建环境:安装Python、PyTorch,以及微调框架(如
PEFT,Transformers,trl)。
步骤二:配置与启动微调
- 选择PEFT方法:在代码中,我们主要配置LoRA参数,如设定
r=8(补丁层的秩)、lora_alpha=32等。这些参数控制新学知识的“容量”和“强度”。 - 设置训练参数:定义学习率(通常很小,如2e-4)、训练轮数(epoch)、批处理大小(batch size,根据显存调整)。
- 启动训练:运行训练脚本。你会看到损失值(loss)逐渐下降,这表示模型正在从你的数据中学习。
步骤三:模型合并与测试
- 保存与合并:训练完成后,你会得到一小部分LoRA权重文件(通常只有几十MB)。需要将这个“补丁”与原模型合并,生成一个完整的、可直接用于推理的新模型文件。
- 效果测试:用一些训练时没见过的、但属于同一领域的问题来测试你的模型,看它是否输出了符合你预期的专业回答。
第三章:效果评估 - 你的模型“学”得怎么样?
微调后,不能光凭感觉,需要科学评估:
-
人工评测:这是黄金标准。邀请领域专家或目标用户,对微调前后的模型回答进行盲测打分,评估其专业性、准确性和流畅度。
-
自动指标:
- 任务特定指标:如果是分类任务,看准确率、F1值;如果是生成任务,可以用 BLEU/ROUGE 分数(衡量与标准答案的文本重叠度)。
- 损失函数值:在预留的验证集上,模型计算的损失值越低,通常表示拟合得越好。
-
能力保留测试:用一些通用问题(如“解释牛顿第一定律”)测试模型,确保它在变得专业的同时,没有忘记原来的通用知识(即没有发生“灾难性遗忘”)。
第四章:GPU选择指南 - 如何配置你的“算力发动机”?
不同的阶段对GPU的需求不同,核心看显存(Memory) 和计算能力(TFLOPS) 。
| 任务阶段 | 核心需求 | 推荐GPU型号(NVIDIA) | 说明 |
|---|---|---|---|
| 训练/全量微调 | 海量显存、极致算力 | H200/B200/H100/A100 | 动辄需要数百GB甚至TB级显存,是科技公司和大研究机构的“重武器”。【产品推荐位】对于大多数开发者和中小企业,直接从 Lab4AI 等云GPU平台租用 H800/H100集群 是按需训练大模型最具性价比的方式。它们提供高速互联(NVLink/IB),支持FP8高效训练,实验秒级启动,闲时更有折扣,远比自己购置和维护硬件划算。 |
| PEFT微调(如LoRA) | 大显存、高性价比 | RTX 4090(24G)、RTX 3090(24G) | 消费级卡王!得益于QLoRA等技术,24G显存已足够微调 7B-13B 参数的模型,是个人研究者和中小团队的绝佳选择。 |
| 大模型推理 | 显存带宽、能效比 | L40S(48G)、RTX A6000(48G) | 推理需要快速将模型参数从显存调入计算单元,因此高内存带宽是关键。这些卡显存大,适合部署中等规模的模型(如70B以下)。 |
| 轻量级推理/开发 | 入门成本、足够显存 | RTX 4060 Ti 16G、消费级16G+显存卡 | 用于本地运行、测试7B以下的量化版模型(如Qwen2.5-1.5B/3B),进行原型验证和小规模应用。 |
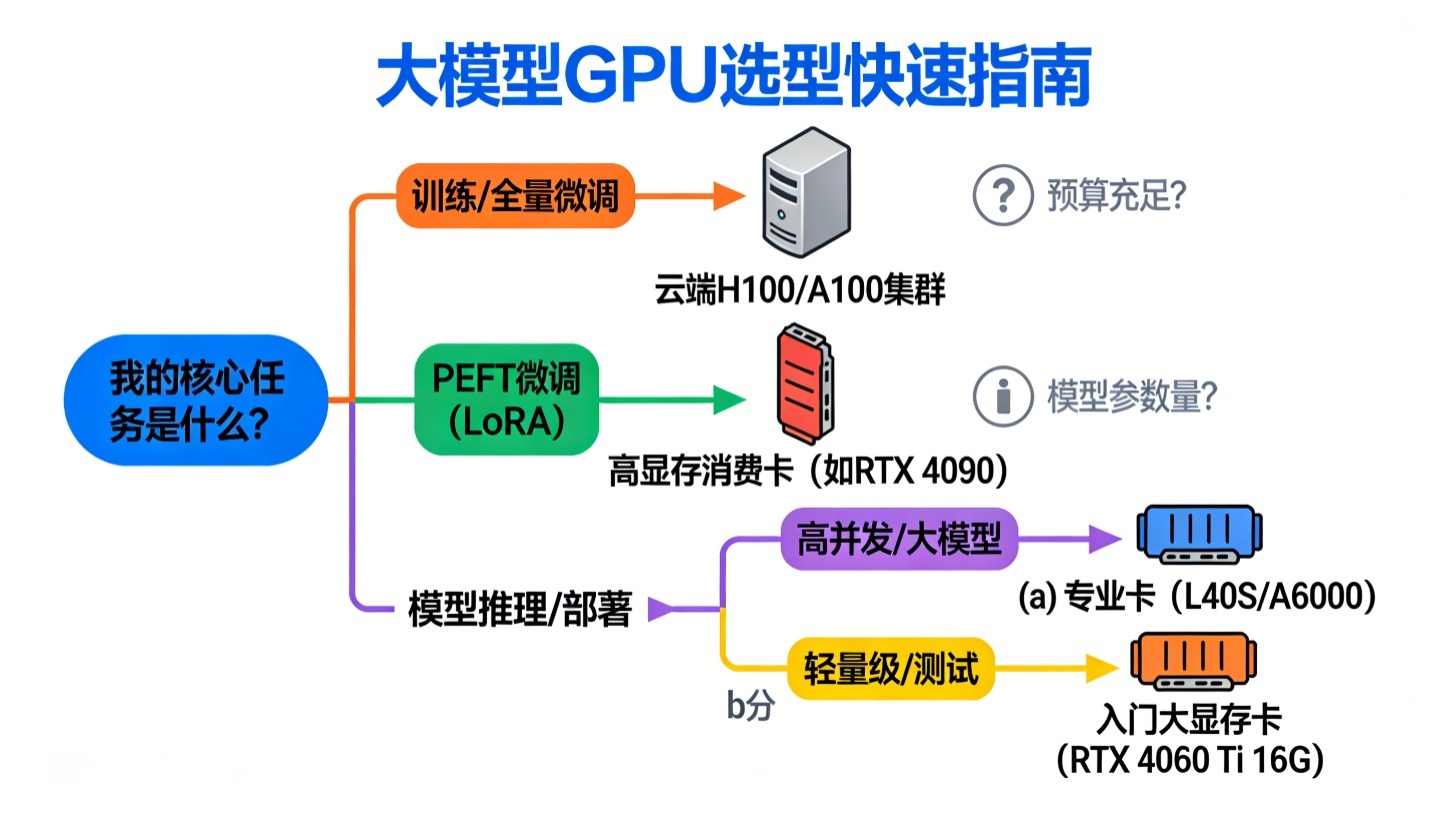
核心原则:对于绝大多数应用, “微调用大显存卡,推理看带宽和成本” 。先明确你的模型规模、使用场景和预算,再对照上表做选择。国产GPU(如华为昇腾)在推理端也已成熟,是合规和降本的重要选项。
总结与展望
-
总结:
- 训练赋予模型“通识”,微调塑造其“专长”,推理是其“价值输出”。
- 对于企业和个人开发者,基于强大开源模型进行PEFT微调(尤其是LoRA/QLoRA) ,是构建垂直领域AI应用最高效、最主流的路径。
- GPU选择需量体裁衣,云GPU服务为训练和大规模推理提供了弹性与便利。
-
展望:
- 更高效的微调技术:未来的研究将继续降低微调的成本和门槛,让“个性化大模型”像制作PPT一样普及。
- 推理极致优化:模型压缩、量化、推理框架优化(如vLLM, TensorRT-LLM)将持续降低部署成本,让大模型跑在手机和边缘设备上成为可能。
- 一体化平台兴起:从数据准备、自动化微调、到评估和部署的一站式平台(如前面提到的LLaMA-Factory)将极大加速AI应用落地。
希望这篇长文能为你拨开迷雾,不仅理解了大模型的核心工作流程,更获得了动手实践的路线图。AI的世界不再遥不可及,从一次亲手微调开始,去创造属于你自己的智能吧!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号