

引言:为什么你需要一个“专属”大模型?
想象一下,你有一个知识渊博但“泛而不精”的助手。它能和你聊天气、讲历史、写诗,但一旦问到“如何防范SQL注入攻击?”或“帮我解读这份心血管疾病的最新诊疗指南”,它的回答就显得空洞、笼统,甚至可能出错。
这就是当前通用大语言模型(LLM)的现状。它们由海量、广泛的互联网数据训练而成,是“通才”,却难以成为特定领域的“专家”。而模型微调(Fine-tuning) ,正是将这位“通才”打造成“专家”的关键技术。
微调的核心价值在于:
- 专业化能力:让模型在你关心的领域(如法律、医疗、金融、安全)表现更精准、深入。
- 成本与隐私平衡:无需耗费巨资从头训练一个模型,也避免了将敏感业务数据上传至公有云的风险。
- 任务精准适配:无论是生成特定格式的报告、遵循内部对话流程,还是理解行业黑话,微调都能让模型“更懂你”。
本文将以Web安全领域为例,带你从零开始,无需编写一行代码,使用可视化工具完成一次完整的大模型微调,最终得到一个在安全领域具备专家级推理能力的专属模型。
技术原理:深入浅出理解“微调”到底在调什么
在开始动手前,花几分钟理解核心概念,能让你的微调事半功倍。
1. 微调的本质:不是“重学”,而是“精修”
可以把预训练大模型想象成一个完成了“通识教育”的博士生,知识面极广。微调,则是让他进入你的“实验室”,阅读你提供的领域专著和论文(你的数据集),针对特定研究方向进行“博士后”级别的深化训练。这个过程主要调整的是模型理解问题和组织答案的“思维方式”,而不是颠覆其原有知识。
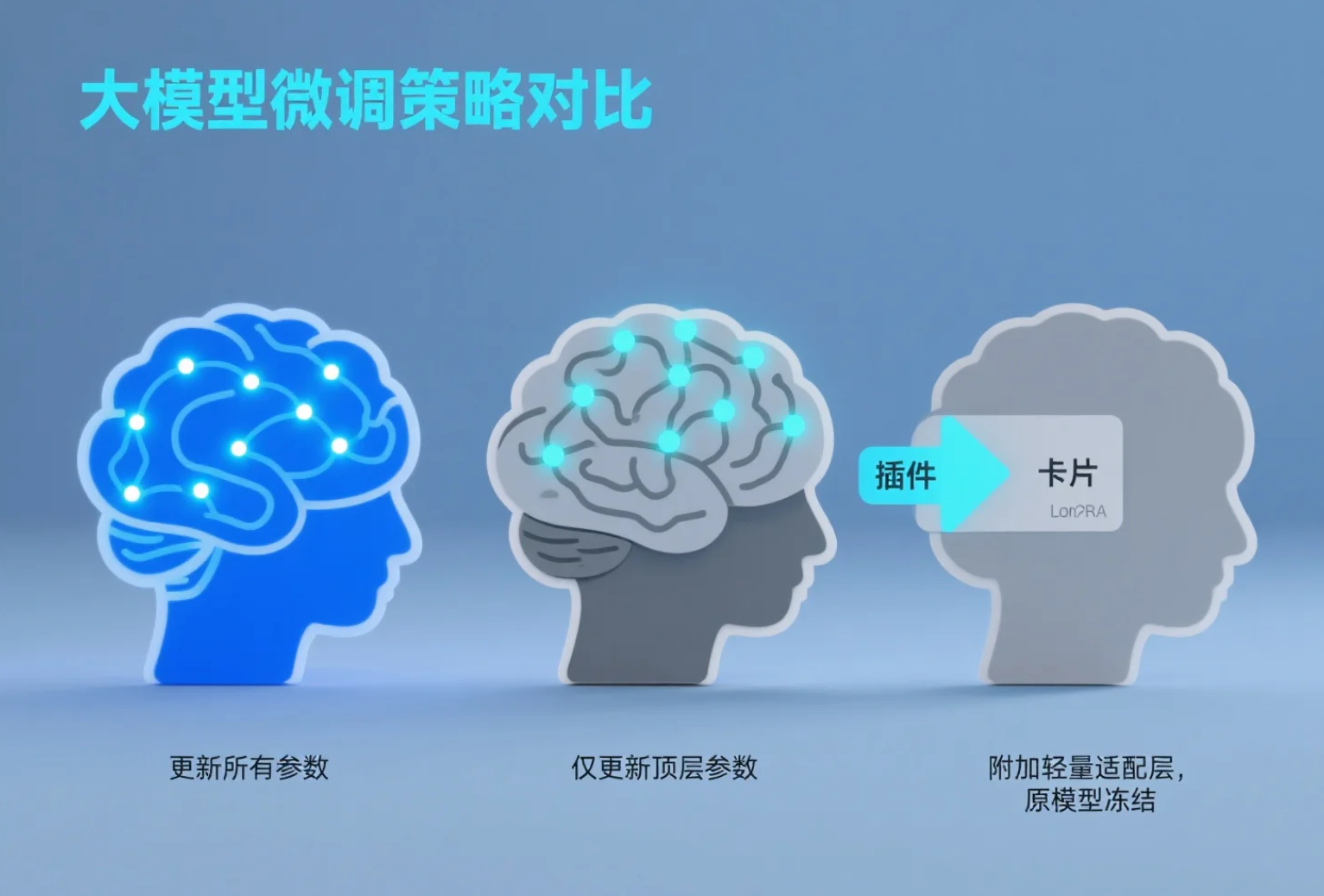
2. 主流微调方法:三种“精修”策略
- 全参数微调(Full Fine-tuning) :让模型的所有“神经元”(参数)都参与学习。效果通常最好,但如同让博士生重学所有基础课,计算成本极高,需要强大的算力。
- 参数冻结微调(Freeze-tuning) :冻结模型的大部分底层参数,只训练顶部的几层。这就像只让博士生学习高级专题课程,效率高,适合任务与模型原有能力比较接近的场景。
- LoRA(Low-Rank Adaptation,低秩适配) :当前最流行且推荐的方法。它不在原模型参数上直接修改,而是为模型附加一组轻量的“适配层”。训练时只更新这组小型适配层。相当于给博士生一本精心编写的“领域速查手册”,他结合原有知识和手册就能完美回答问题。LoRA极大降低了显存消耗和训练时间,且一个基础模型可以搭配多个不同的LoRA“手册”,实现灵活切换。
3. 模型量化:让大模型“瘦身”的技巧
大模型动辄数十亿参数,对显存要求很高。量化技术通过降低模型权重的数值精度(例如,从FP32高精度浮点数转换为INT4整数)来压缩模型体积、加速推理。这类似于将“无损音频”转换为“高质量MP3”,在几乎听不出音质损失的情况下,大幅减少文件大小。QLoRA就是将4位量化与LoRA结合的明星方案,让我们能在消费级显卡上微调大模型。
4. 对话模板:确保模型“听对指令”
不同模型(如ChatGLM、Qwen、LLaMA)对输入格式的要求各不相同。对话模板就像是一个标准化翻译器,无论你用哪种方式提问,它都能把你的问题转换成模型能理解的“内部语言”,同时管理多轮对话的历史记录,确保模型生成连贯、准确的回答。
理解了这些,你就掌握了微调的“道”。接下来,我们进入“术”的环节,开始动手操作。
实践步骤:零代码可视化微调全流程
我们将使用 LLaMA Factory 这个强大的开源工具。它提供了友好的Web界面,让微调像填表单一样简单。
第一步:环境搭建
在浏览器中打开在线大模型微调平台 | LLaMA-Factory Online - 一站式低代码训练服务,进行注册登录,然后你就能看见LLaMA Factory的控制台。

第二步:选择与加载基础模型
在“模型名或路径”中,输入你想微调的基础模型,例如 Qwen/Qwen2.5-7B-Instruct。系统会自动从Hugging Face拉取。如果你在国内,可以配置镜像源加速。
小贴士:对于领域微调,优先选择指令微调过的模型(名字带-Instruct或-Chat),它们更擅长遵循指令。
第三步:配置微调方法与参数(核心)
这是最关键的一步,但UI界面已将其简化:
-
微调方法:选择
LoRA。 -
模型量化(可选) :如果显卡显存小于16GB,建议选择
4-bit量化,并勾选Unsloth加速,可以极大节省显存并提速。 -
对话模板:根据你选的基础模型自动匹配,例如选Qwen模型会自动匹配Qwen模板。
-
设置关键参数:
- 学习率:LoRA微调常用
5e-5或4e-5。这是最重要的参数之一,可以先保持默认。 - 训练轮数:通常
3个Epoch(完整遍历数据集3遍)是个不错的起点。 - LoRA Rank (秩) :控制适配器的“表达能力”。对于7B/13B模型,设为
8或16即可平衡效果与效率。 - 截断长度:根据你的数据长度设定。可先设为
2048。数据更长再调整。
- 学习率:LoRA微调常用
第四步:准备与加载数据集
微调的成功,80%取决于数据。数据需要整理成特定格式(如Alpaca格式:instruction-输入,output-期望输出)。
-
准备数据:将你的领域问答对整理成JSON或JSONL文件。
-
在LLaMA Factory中加载:
- 将数据文件放入项目的
data目录。 - 在WebUI的“数据集”部分,通过简单的配置文件(
dataset_info.json)指向你的数据文件。界面提供了直观的配置方式,只需填写数据集名称和文件路径即可。
- 将数据文件放入项目的
第五步:启动训练与监控
- 在“训练”标签页,点击“预览命令”确认配置无误。
- 点击“开始训练”。训练会在后台启动。
- 你可以在下方的“训练状态”中实时看到损失值(Loss)曲线。曲线平稳下降,说明训练正常。
- 对于更详细的监控(如GPU使用率、更多指标),可以集成 SwanLab 等可视化工具,只需在设置中填入API Key即可。
第六步:验证与使用微调后的模型
训练完成后,你得到了一个LoRA适配器(一组小文件)。
- 在线测试:在LLaMA Factory的“聊天”标签页,加载基础模型和训练好的适配器,即可与微调后的模型直接对话,对比效果。
- 模型合并与导出:为了便于部署,你可以将LoRA适配器与基础模型合并成一个独立的模型文件。
- 本地部署:合并后的模型可以通过 Ollama(简单易用,适合个人)或 vLLM(高性能,适合生产环境)进行部署和API调用。

效果评估:如何判断微调是否成功?
不要只看训练Loss下降,要从多维度评估:
-
领域内问题(见过/没见过的) :
- 数据集内问题:回答应更精确、详尽,能复现数据中的关键知识。
- 数据集外问题:应表现出良好的泛化能力,能运用学到的概念和推理模式解答新问题。
-
知识体系整合:对于复杂问题,模型是否能关联多个知识点,进行系统性、分步骤的推理(例如,不仅回答“如何防范XSS”,还能比较存储型、反射型、DOM型XSS的防范异同)。
-
通用能力保留:微调不应损害模型原有的通用能力。测试一些与领域无关的问题(如写诗、编程、常识问答),确保其能力没有严重退化。
-
人工评估:最终,请领域专家对关键问题的回答质量进行打分,这是最可靠的评估方式。
总结与展望
通过这次旅程,你已经掌握了微调专属大模型的核心流程:从理解微调的价值,到选择合适的方法(特别是LoRA),再到使用LLaMA Factory进行零代码实战,最后评估模型效果。关键在于高质量的数据和合理的参数配置。
未来展望:
- 更高效的微调技术:如GaLore、DoRA等新技术会进一步降低微调门槛。
- 自动化与智能化:自动超参数搜索、自动数据清洗和增强工具将让微调更加“傻瓜式”。
- 多模态与智能体:微调技术将不仅用于文本模型,还能打造专属的图像理解、语音助手乃至能执行复杂工作流的AI智能体。
微调不是终点,而是起点。当你拥有了自己的专属模型后,下一步就是将其融入实际业务流。无论是将其部署为内部知识库助手,还是集成到客户服务系统中,选择一个稳定、高效的部署平台至关重要。对于企业级应用,可以考虑专业的模型部署与服务平台,它们提供从模型托管、版本管理、流量监控到弹性伸缩的一整套解决方案,让你能专注于业务本身,而非底层基础设施的维护。
大模型民主化的时代已经到来。微调这把“金钥匙”,正使得每个企业、每个团队乃至个人,都有机会打造最能理解自己、服务自己的AI伙伴。现在,就从准备你的第一份领域数据开始吧!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号