深入JVM内存区域管理,值得你收藏
JDK和JRE和JVM的关系
JDK(Java Development Kit)是程序开发者用来来编译、调试java程序用的开发工具包
JRE(JavaRuntimeEnvironment,Java运行环境),也就是Java平台。所有的Java 程序都要在JRE下才能运行。普通用户只需要运行已开发好的java程序,安装JRE即可
JVM(JavaVirtualMachine,Java虚拟机)是JRE的一部分。它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。JVM有自己完善的硬件架构,如处理器、堆栈、寄存器等,还具有相应的指令系统
JVM内存区域
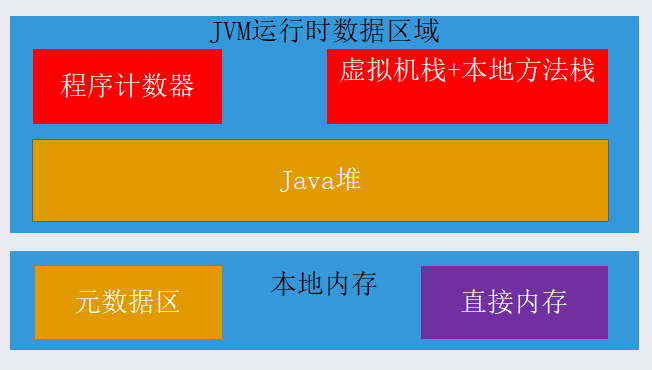
本文的讲解都从这个图一一开始,你脑海里先试着回忆一下这个几个区域的概念,是独享的还是共享的?每个区域都存储了什么?哪些区域会被垃圾回收?哪些区域会抛出OOM?哪些区域会抛出SOF?如何避免
什么是JVM运行时数据区域?
Java虚拟机定义了在程序执行期间使用的各种运行时数据区域。其中一些数据区域是在Java虚拟机启动时创建的,仅在Java虚拟机退出时才被销毁。其他数据区域是每个线程的。创建线程时创建每个线程的数据区域,并在线程退出时销毁每个数据区域。
堆内存
堆内存中存储的是所有类实例和数组的内存,在虚拟机启动时创建,虚拟机结束时销毁,归还给操作系统,堆内存中对象的销毁都JVM自行管理(垃圾收集器),当程序创建对象的越来越多时并且这些对象都无法被回收时,这个区域会抛出OOM异常,并且堆内存是所有线程共享的,所以当多个线程操作堆内存的数据时会有并发问题,要加锁。
栈内存
栈分为虚拟机栈和本地方法栈,首先栈是线程安全的,栈内存随线程创建而创建,随线程销毁而销毁,栈内存是不需要垃圾回收器进行回收的。线程栈的大小可以是在虚拟机启动时指定固定大小,也可以是自行计算动态扩容的。当指定大小时,线程栈的内存随着使用而不足时JVM抛出StackOverFlowError,当不指定大小时,线程栈动态扩容时如果没有足够的内存不足,JVM将会抛出OOM错误。
虚拟机栈描述的是Java方法执行的内存模型,每个方法在执行时会创建一个栈帧用于存储放法局部变量表,操作数栈,动态链接,出口信息,如下图,整个栈帧是先入后出。

局部变量表存放了编译器可知的各种基本数据类型,对象引用(不包含成员变量)每个局部变量表占用32位(4个字节),所以long和double会占用两个局部变量表,其它类型占用一个,哪怕byte虽然只有8位,也占用一个局部变量表,局部变量表所需的内存在编译期就已经确定了也就是进入这个方法时就已经确定了,运行期间不会更改.
操作数栈则存储方法内一些进行了运算操作后的结果.
动态链接,在方法内调用接口,通过字面量链接到具体的实现类,实现Java的动态特性.
出口地址(返回地址),return或者发生Exception等。
本地方法栈虚拟机栈相似,都是线程私有的,安全的,区别就是虚拟机为虚拟机栈执行Java服务(字节码服务),而本地方法栈为虚拟机使用到的Native方法服务,本地方法栈中使用的语言,使用方式,数据结构没有强制要求。
程序计数器
Java程序是多线程执行的,当一个线程执行字节码时,突然CPU切换到另一个线程,那么上一个线程执行的上下文信息怎么保存呢?等到下次再切换到这个线程,从哪里开始执行呢?这些信息都需要在线程切换时记录,这就是程序计数器的职责,是每个线程私有的,线程安全的,因线程创建而创建,因线程销毁而销毁,程序计数器其实就是一小块内存。
程序计数器指向当前线程所执行的字节码所在的行号,记录着当前程序运行到哪了字节码解释器的工作就是通过改变这个计数器的值来选取下一条需要执行的字节码指令。分支,循环,跳转,异常处理,线程回复等都需要依赖这个计数器来完成
如果一个线程执行一个Java方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址;如果正在执行的是一个本地方法,这个计数器的值则为undefine,此内存区域是唯一一个在Java的虚拟机规范中没有规定任何OutOfMemoryError异常情况的区域
元数据区
默认情况下,类元数据只受可用的本地内存限制。新参数(MaxMetaspaceSize)用于限制本地内存分配给类元数据的大小。如果没有指定这个参数,元空间会在运行时根据需要动态调整,
这个区域也是会发生GC的,垃圾回收将在元数据使用达到“MaxMetaspaceSize”参数的设定值时进行,适时地监控和调整元空间对于减小垃圾回收频率和减少延时是很有必要的。如果的元空间持续的发生GC说明可能存在类、类加载器导致的内存泄漏或是大小设置不合适,如果这个空间使用达到了MaxMetaspaceSize,但GC无法回收(所有的类信息都是有用的,所以无法回收),也会发生OOM错误。
String常量池已经从方法区(jdk8以前的叫法)中的运行时常量池分离到堆中了,不在元数据中。
Metaspace由两部分组成:Klass MetaSpace 和 NoKlass MetaSpace,Klass代表的是
class文件在jvm中运行时的数据结构,NoKlass专门用来存储Klass相关的其它数据,比如Method和ConstantPool。
回答刚开始的问题
用一段代码分析JVM内存的存储
new Thread(new Runnable() {
@Override
public void run() {
test();
}
public void test(){
Object obj = new Object();
}
}).start();
上面这段代码很简单,启动了一个线程,线程的run方法中调用了test方法,test方法中创建一个Objet对象,一起来看一下这段代码涉及的JVM内存哪些区域,分别存储了什么。
首先创建了一个线程,那么这个线程对应的私有的虚拟机栈内存肯定被分配,这个线程的代码执行中对应的程序计数器内存肯定被分配,因为没有涉及到本地方法,所有本地栈内存不会分配,而且虚拟机栈内存是在编译器就确定的。
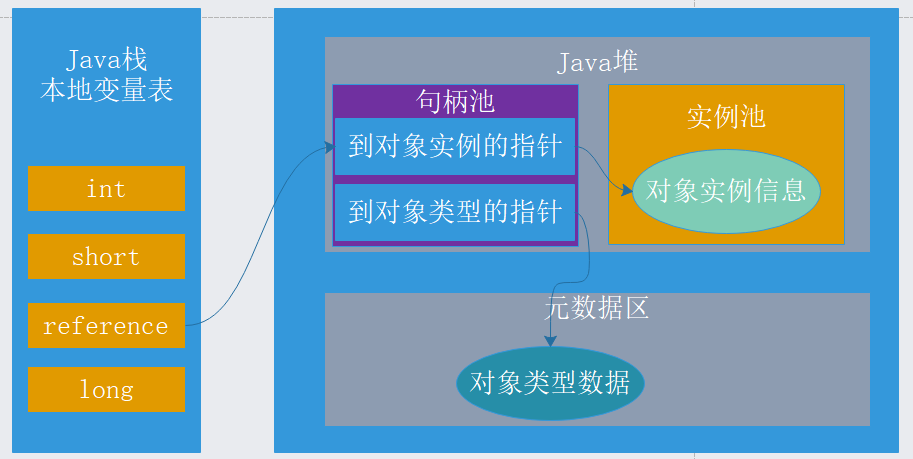
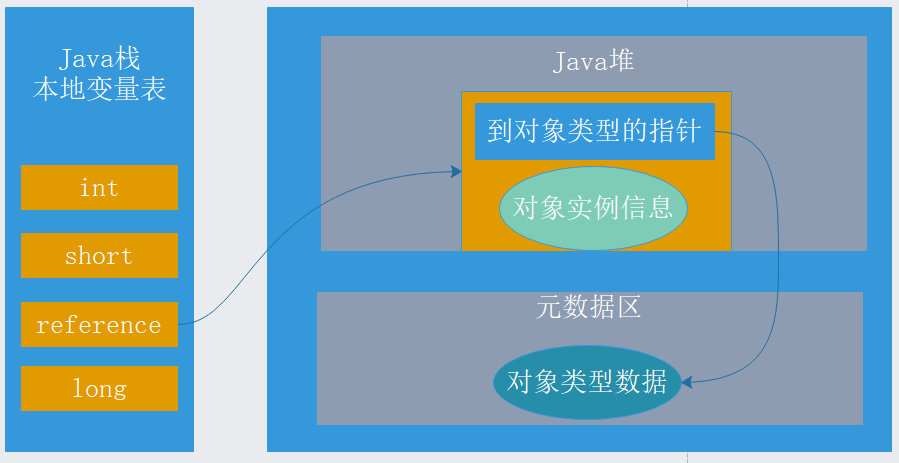
Test方法执行时,创建一个Object对象,我们知道obj是一个引用(reference)类型,所以obj保存在Java栈的本地变量表中,而在Java堆中会保存该引用的实例化对象,Java堆中还必须包含能查找到此对象类型数据的地址信息(如对象类型、父类、实现的接口,方法等)这些类型数据则保存在元数据区域中。一般对象引用到对象实例和对象类型指向有两种方法,一种是句柄池方式,一种是直接指针方式。这两种对象的访问方式各有优势,使用句柄访问方式的最大好处就是reference中存放的是稳定的句柄地址,在对象的移动(垃圾收集时移动对象是非常普遍的行为)时只会改变句柄中的实例数据指针,而reference本身不需要修改。使用直接指针访问方式的最大好处是速度快,它节省了一次指针定位的时间开销。目前Java默认使用的HotSpot虚拟机采用的便是是第二种方式进行对象访问的,下面用两张图来表述一下这两种方式。
这张图是句柄池方式
这张图是直接指针方式
关于基本数据类型和引用类型的分配
基本数据类型包括 int short long bolean等,引用类型就是我们常见的对象,那么这两种数据类型内存中是怎么分配的呢?这个得区别看待,我们根据下面代码来分析
class Dog {
private int age;
}
class Test{
public void test(){
Dog dog = new Dog();
dog.age = 2;
int age = 1;
Integer age = new Integer(3);
}
}
在Test类中的test方法中,我们创建了一个Dog对象,这个对象实例是分配在堆上的,dog这个引用是在栈上的,dog中的age在哪里呢?因为Dog对象实例是在堆上的,所有他的成员变量也是在堆上的。 int age这个变量是栈上的,因为它是局部变量,并且是基本数据类型,Integer age实例是在堆上的,引用是在栈上的,根据这个例子,可以总结下面两条基本黄金法则
- 引用类型总是被分配到“堆”上。
- 值类型总是分配到它声明的地方:
a. 作为引用类型的成员变量分配到“堆”上
b. 作为方法的局部变量时分配到“栈”上
总结
本文详细介绍了JVM内存区域的各个情况,也就是JVM内存模型,也解答了一些常见的面试题和内存分配相关的一些问题,希望能够帮助到读者更好的了解到JVM,可能会有人有些疑问,为什么不说堆内存的分代(年轻代,年老代)问题呢?我认为这个属于JVM垃圾回收的方位,分代思想只是解决垃圾收回问题的一种方法,同理,Java8中G1的region也是一样,都是为了解决垃圾回收效率和性能问题,会放在JVM垃圾回收一文来说。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号