Hadoop综合大作业
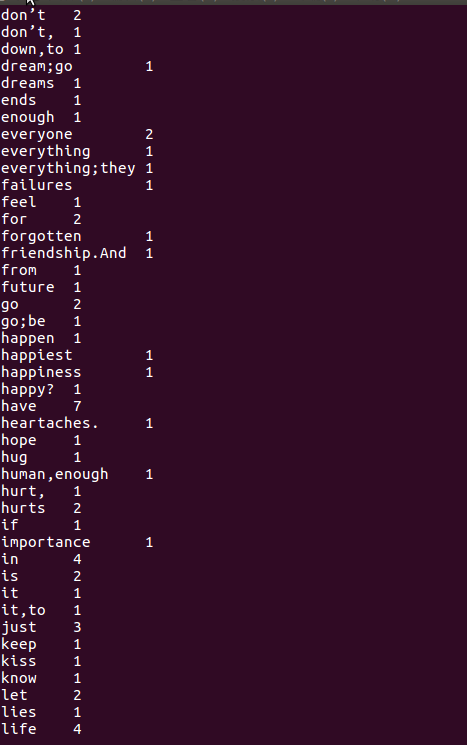
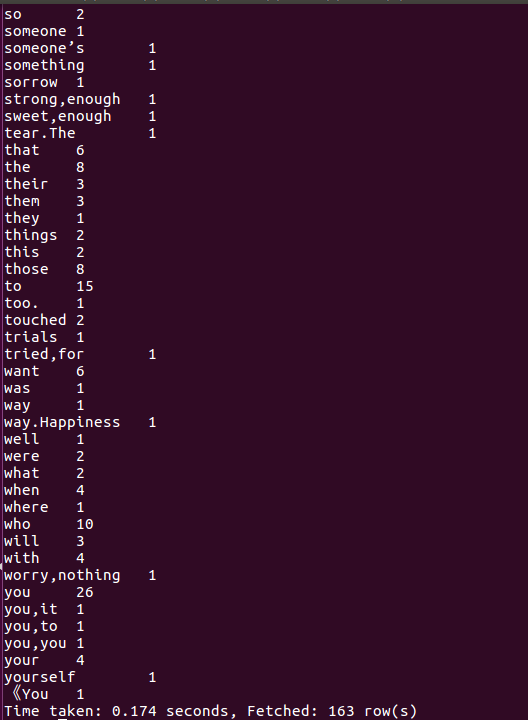
1.1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)词频统计。
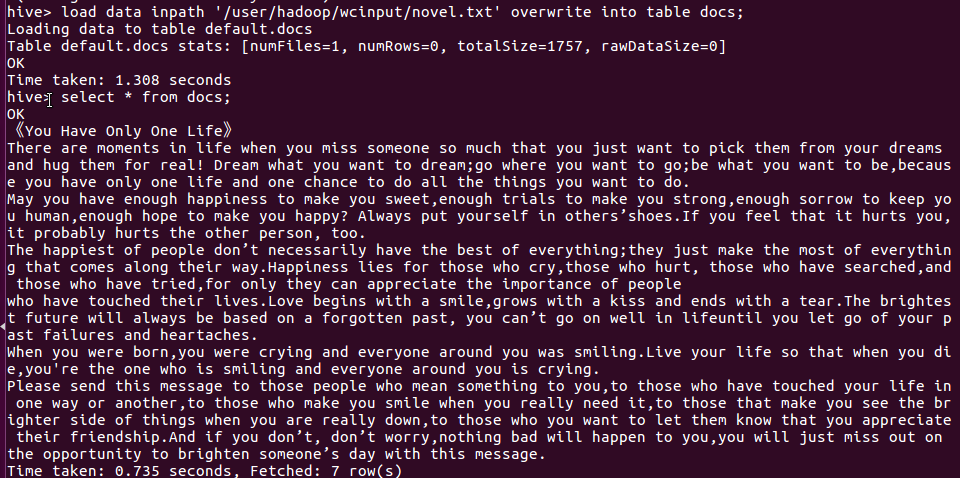
因为大数据爬出来的数据不太适合进行词频统计,所以我换了一篇简易的英文文章,其次因为英文长篇小说实在是太长,词频统计出来截图截不完。



2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。
在做的过程中遇到个问题,因为用python导出来的csv有乱码,我是先尝试用xsxl文件格式导出然后再转到csv,在Excel里无乱码,但用txt打开的话好像是乱码。其次是我优化了一下导出来的数据,便于尝试用来进行数据分析。
为了解决乱码的问题,我是现在window7把数据的.txt另存为的时候编码改为UTF-8这样才能使文字在Linux里不会变成乱码。
查看数据集
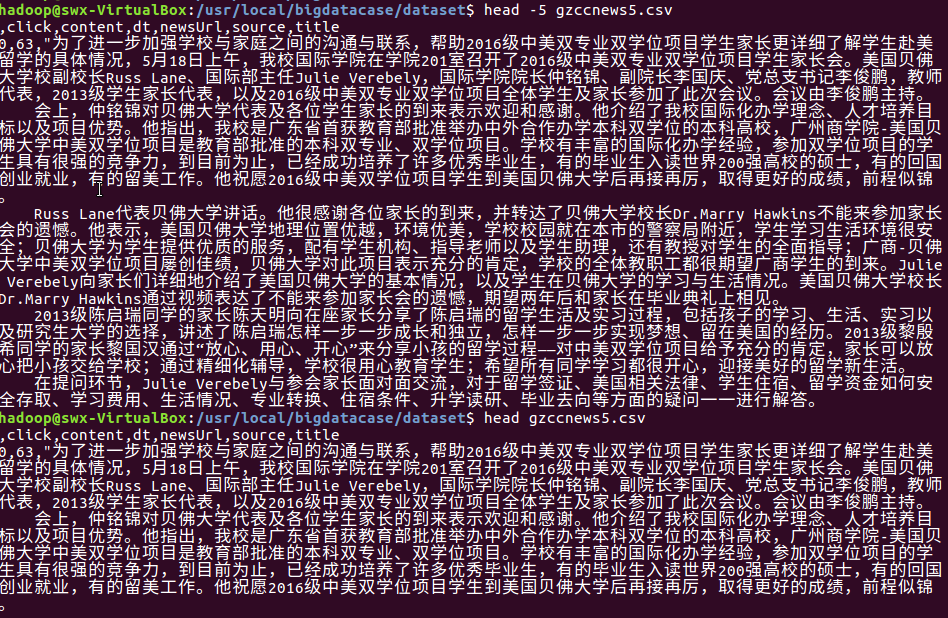
而此处我已经将数据进行了预处理,并且查看

把data.txt导入HDFS中


在这里我想进行查询可是行数显示为0,那么说明数据导入失败,然后我进行了很多次尝试都无法导入,因为水平时间有限,而我的数据量还较小,所以我只能打出语句然后再Excel里模拟查询后的效果。

查询点击量前3
select top 3 from bigdata order by click desc

因为数据量样本数量没那么多,因此我也不是很好能够得出较为有代表的信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号