

团队项目-将py界面嵌入到vue中
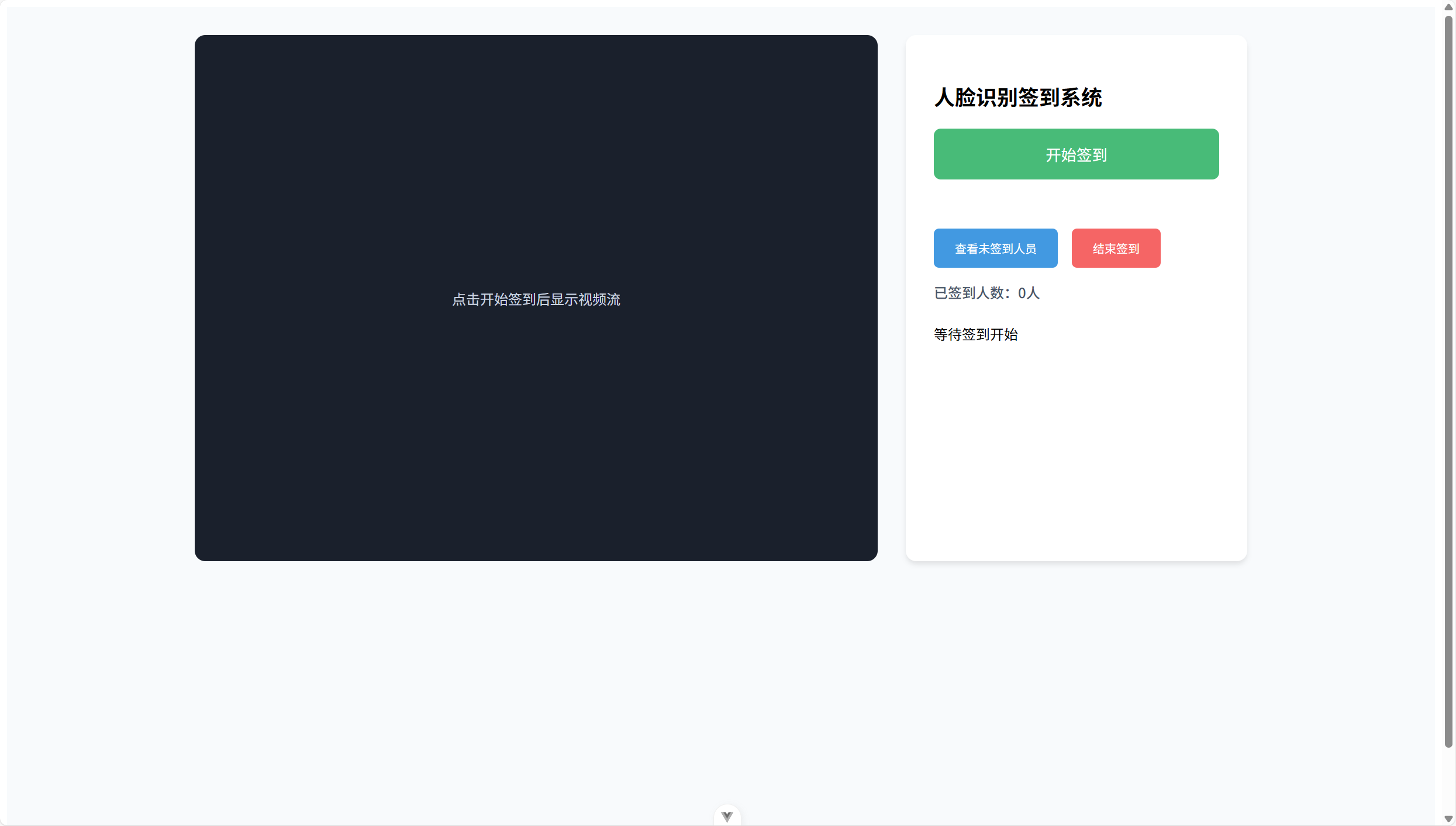
通过将原有的py代码进行修改,删除了tkinter界面化工具,改用视频流的形式,将视频流通过端口传输到前端,虽然会导致有延迟卡顿,但相比于白花花的界面更加美观。
import os
import dlib
import numpy as np
import cv2
import logging
import time
import pandas as pd
# Dlib 初始化
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor('data/data_dlib/shape_predictor_68_face_landmarks.dat')
face_reco_model = dlib.face_recognition_model_v1("data/data_dlib/dlib_face_recognition_resnet_model_v1.dat")
class Face_Recognizer:
def __init__(self):
self.font = cv2.FONT_ITALIC
self.frame_time = 0
self.frame_start_time = 0
self.fps = 0
self.fps_show = 0
self.start_time = time.time()
self.frame_cnt = 0
# 人脸数据库相关
self.face_features_known_list = []
self.face_name_known_list = []
self.signed_in_names = [] # 仅保留内存中的签到名单
self.all_names = []
# 视频流相关
self.cap = cv2.VideoCapture(0)
self.get_face_database()
logging.info("Face Recognizer initialized without GUI")
def get_face_database(self):
path_features_known_csv = r"D:\github\facecsv\features_all.csv"
if os.path.exists(path_features_known_csv):
csv_rd = pd.read_csv(path_features_known_csv, header=None)
for i in range(csv_rd.shape[0]):
features_someone_arr = []
name = csv_rd.iloc[i][0]
self.face_name_known_list.append(name)
self.all_names.append(name)
for j in range(1, 129):
features_someone_arr.append(float(csv_rd.iloc[i][j]))
self.face_features_known_list.append(features_someone_arr)
logging.info(f"Loaded {len(self.face_features_known_list)} faces from database")
else:
logging.error("'features_all.csv' not found!")
def sign_in(self, name):
# 直接标记为已签到(不再检查重复)
if name not in self.signed_in_names:
self.signed_in_names.append(name)
logging.info(f"{name} signed in")
return True
return False
@staticmethod
def return_euclidean_distance(feature_1, feature_2):
feature_1 = np.array(feature_1)
feature_2 = np.array(feature_2)
return np.sqrt(np.sum(np.square(feature_1 - feature_2)))
def process_frame(self, img_rd):
self.frame_cnt += 1
faces = detector(img_rd, 0)
if len(faces) > 0:
for i, face in enumerate(faces):
shape = predictor(img_rd, face)
face_descriptor = face_reco_model.compute_face_descriptor(img_rd, shape)
face_feature = [float(x) for x in face_descriptor]
distances = []
for known_feature in self.face_features_known_list:
distance = self.return_euclidean_distance(face_feature, known_feature)
distances.append(distance)
min_distance = min(distances)
min_index = distances.index(min_distance)
if min_distance < 0.4:
name = self.face_name_known_list[min_index]
self.sign_in(name) # 仅更新内存中的签到状态
cv2.putText(img_rd, name, (face.left(), face.top() - 10),
self.font, 0.8, (0, 255, 0), 2)
else:
cv2.putText(img_rd, "Unknown", (face.left(), face.top() - 10),
self.font, 0.8, (0, 0, 255), 2)
cv2.rectangle(img_rd, (face.left(), face.top()),
(face.right(), face.bottom()), (0, 255, 0), 2)
self.update_fps()
cv2.putText(img_rd, f"FPS: {self.fps_show:.2f}", (10, 30),
self.font, 0.8, (0, 255, 0), 2)
return img_rd
def update_fps(self):
now = time.time()
if int(now) != int(self.start_time):
self.fps_show = self.fps
self.frame_time = now - self.frame_start_time
self.fps = 1.0 / self.frame_time
self.frame_start_time = now
def generate_frames(self):
try:
while self.cap.isOpened():
ret, frame = self.cap.read()
if not ret:
break
processed_frame = self.process_frame(frame)
ret, buffer = cv2.imencode('.jpg', processed_frame)
frame = buffer.tobytes()
yield (b'--frame\r\n'
b'Content-Type: image/jpeg\r\n\r\n' + frame + b'\r\n')
except Exception as e:
logging.error(f"Video stream error: {e}")
finally:
self.__del__()
def __del__(self):
if self.cap.isOpened():
self.cap.release()
cv2.destroyAllWindows() # 新增窗口资源释放
logging.info("Camera resource released")
from flask import Flask, jsonify, Response
from flask_cors import CORS
import threading
import subprocess
import pandas as pd
from datetime import datetime
from face_reco_from_camera_ot import Face_Recognizer
from threading import Lock
app = Flask(__name__)
CORS(app, resources={r"/*": {"origins": "*"}}) # 启用跨域支持
# 全局变量和锁
face_recognizer = None
current_csv = ""
camera_lock = Lock() # 防止摄像头资源冲突
# -------------------- 签到功能路由 --------------------
@app.route('/start-recognition', methods=['POST'])
def start_recognition():
global face_recognizer, current_csv
try:
with camera_lock:
# 释放已有摄像头资源
if face_recognizer is not None:
face_recognizer.__del__()
# 初始化新实例
face_recognizer = Face_Recognizer()
current_csv = "" # 移除了对不存在属性的引用
return jsonify({
"status": "started",
"message": "人脸识别已启动"
})
except Exception as e:
return jsonify({
"status": "error",
"message": str(e)
}), 500
@app.route('/video_feed')
def video_feed():
global face_recognizer
if face_recognizer is None:
return Response("人脸识别未初始化", status=503)
return Response(
face_recognizer.generate_frames(),
mimetype='multipart/x-mixed-replace; boundary=frame'
)
@app.route('/sign-in-status', methods=['GET'])
def get_sign_in_status():
global face_recognizer
try:
if face_recognizer is not None:
return jsonify({"signed": face_recognizer.signed_in_names})
else:
return jsonify({"signed": []})
except Exception as e:
return jsonify({"signed": [], "error": str(e)}), 500
# -------------------- 人脸注册功能路由 --------------------
def run_face_register():
subprocess.Popen(['python', 'get_faces_from_camera_tkinter.py'])
@app.route('/start-face-registration', methods=['POST'])
def start_face_registration():
thread = threading.Thread(target=run_face_register)
thread.start()
return jsonify({
'status': 'started',
'message': '人脸录入窗口已启动'
})
# -------------------- 特征提取路由 --------------------
def run_face_reco_standalone():
subprocess.Popen(['python', 'features_extraction_to_csv.py'])
@app.route('/start-face-recognition', methods=['POST'])
def start_face_recognition():
thread = threading.Thread(target=run_face_reco_standalone)
thread.start()
return jsonify({
'status': 'started',
'message': '人脸特征正在导入数据库'
})
if __name__ == '__main__':
app.run(port=5000, debug=True, threaded=True)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号