
每天进步一点点-Tesseract 文字识别
Tesseract 文字识别
是github上的开源文字识别软件
| 下载与安装 | https://github.com/tesseract-ocr/tesseract/wiki | |
|---|---|---|
| 下载 | https://github.com/UB-Mannheim/tesseract/wiki | |
| 数据文件下载 | https://github.com/tesseract-ocr/tesseract/wiki/Data-Files | |
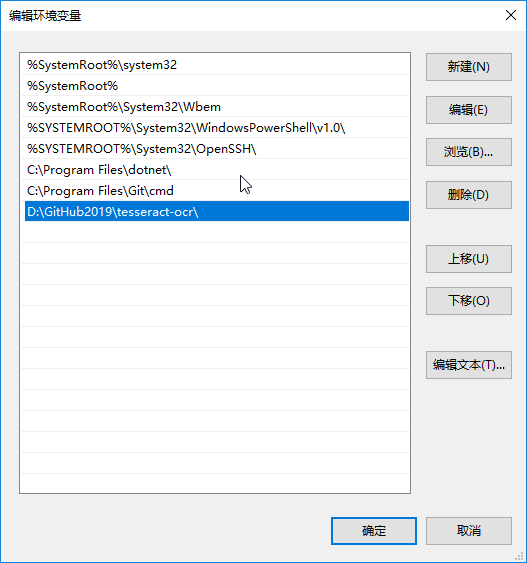
| 需要添加环境变量 | D:\GitHub2019\tesseract-ocr\ | |
| 返回的out.txt默认字符 | utf8 | |
| 训练字库下载 | https://github.com/tesseract-ocr/tesseract/wiki/TrainingTesseract-4.00 | |
| 命令语法 | https://github.com/tesseract-ocr/tesseract/blob/master/doc/tesseract.1.asc |
前提条件:
1 在上面的地址下载安装tesseract
2 添加安装路径到windows环境变量
3 下载自己需要的语言库(官方已经训练好)到tessdata目录下



简单使用:
简单使用:
tesseract [imagepath] [outputPath] -l [Language] [optional]
例如:tesseract C:\Users\ZR644\Desktop\tesseract-ocr\myscan.png C:\Users\ZR644\Desktop\tesseract-ocr\out -l chi_sim --psm 7
其中:
1 outputPath输出是不需要加后缀的,只是文件名称,这点有点奇怪
2 output格式是用utf8,有点编码起默认是别的,造成识别失败的假象
3 一开始识别不出不要紧,请按照图片调整参数
4 有一个图片文本占得很满,查了资料说图片要有一圈留白,仅供参考.
5 更多命令请参考本文一开始给出的命令语法页面
c#调用
在Nuget上有封装的tessercat,但是看了一下他的最新版本是用于tesseract-ocr 3.05.02的.NET包装器,而目前最新的版本都4多了,所以不打算用了.
像上面一样通过命令行的方式进行调用,然后读取out.txt文件识别的内容就好了.
简单例子:
做了一个不同psm参数识别同一张图片的具体对比:

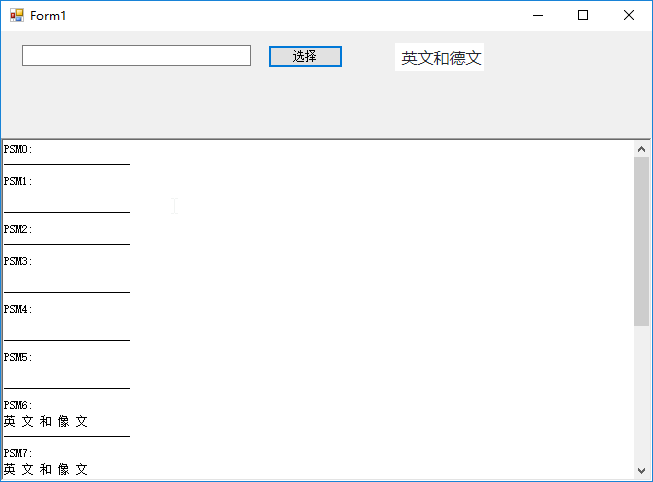
下载地址:https://github.com/tiancai4652/IdentifyImageByTesseract
使用前请先安装好,设置好环境变量,下载语言包到其目录下

 浙公网安备 33010602011771号
浙公网安备 33010602011771号