别再只会算直线距离了!用“马氏距离”揪出那个伪装的数据“卧底”
1. 引言:当你手中的尺子“撒谎”时
做数据分析或机器学习时,我们经常需要回答一个问题:“这个数据点离中心有多远?”
通常,你的第一反应是拿出“欧氏距离”(Euclidean Distance)这把尺子:连接两点,勾股定理一算,完事。
但在现实世界的高维数据中,这把尺子经常撒谎。
痛点场景:
假设你在分析某精英社区的居民数据:身高和体重。绝大多数人身高越高,体重越重(正相关)。
现在来了两个人:
A:身高 190cm,体重 40kg(瘦得像根竹竿,极度异常)。
B:身高 160cm,体重 80kg(偏胖,但在人群中还算常见)。
如果你只看几何上的“绝对距离”,A 可能比 B 离人群中心(平均身高体重)更近(因为数值差异可能被量纲掩盖)。由于欧氏距离无视了数据的分布规律(相关性),它会告诉你 A 很正常,而 B 是异常值。
但这显然违背直觉!A 才是那个极度离谱的“数据卧底”。
解决方案:
你需要一把能“看穿”数据内部关系的新尺子——马氏距离。它不仅看距离,还看“队形”。
2. 概念拆解:在“椭圆”里找朋友
为了理解马氏距离,我们先抛开矩阵公式,去一个生活场景里看看。
生活化类比:拥挤的地铁与空旷的广场
想象你在早高峰的地铁站(数据分布):
-
场景一(圆形分布):
大家站得很散乱,毫无规律。你在圆心,如果你要判断谁离你“更远”,只需拉一根绳子(欧氏距离)量一下即可。因为各个方向的拥挤程度是一样的。
-
场景二(椭圆分布):
大家都在排队进站,人流形成了一个长条形的队伍(正相关)。
-
张三:站在队伍的侧面,虽然离你只有 1 米,但他脱离了队伍,显得格格不入。
-
李四:站在队伍的前后方向,虽然离你 3 米,但他仍在队伍里,显得很自然。
-
核心逻辑:
在场景二中,顺着队伍方向(相关性方向)的距离“不值钱”,而逆着队伍方向的距离“很值钱”。
-
欧氏距离是个愣头青,它觉得李四(3米)比张三(1米)远,所以李四是异类。
-
马氏距离是个老江湖,它看出了队伍的趋势,它认为张三才是那个“破坏队形”的异常值。
图解逻辑
-
欧氏距离认为数据的“势力范围”是一个正圆。
-
马氏距离通过计算数据的协方差矩阵,描绘出了数据的真实形状(通常是一个椭圆),并把这个椭圆作为“标尺”。
简而言之:马氏距离 = 修正了坐标轴(消除量纲)+ 考虑了相关性后的欧氏距离。
3. 动手实战:Python 里的“数据侦探”
光说不练假把式。我们用 Python 来模拟刚才的身高体重场景,看看欧氏距离是怎么被骗的,马氏距离又是怎么破案的。
准备工作
假设你已经安装了 numpy, scipy, matplotlib。
MVP 代码 (Minimum Viable Product)
import numpy as np
from scipy.spatial import distance
import matplotlib.pyplot as plt
# 1. 制造一些“甚至有些极端”的相关数据
# 设想:X是身高,Y是体重,两者高度正相关
np.random.seed(42)
# 均值 [身高, 体重]
mean = [170, 65]
# 协方差矩阵 [[方差X, 协方差], [协方差, 方差Y]]
# 协方差很大,说明相关性很强
cov = [[30, 25],
[25, 30]]
# 生成 500 个正常人的数据
data = np.random.multivariate_normal(mean, cov, 500)
# 2. 定义两个测试点
# 点 A:顺着趋势远去(比如 NBA 球员:很高很壮)- 几何距离远,但统计上合理
point_A = [185, 80]
# 点 B:逆着趋势(瘦高个)- 几何距离近,但统计上极不合理
point_B = [172, 60]
# 计算数据集的中心
center = np.mean(data, axis=0)
# 3. 欧氏距离 (Euclidean) - 愣头青
# 也就是简单的计算两点间直线长度
dist_euc_A = distance.euclidean(point_A, center)
dist_euc_B = distance.euclidean(point_B, center)
# 4. 马氏距离 (Mahalanobis) - 老江湖
# 公式需要用到协方差矩阵的逆
inv_cov = np.linalg.inv(np.cov(data.T))
dist_mah_A = distance.mahalanobis(point_A, center, inv_cov)
dist_mah_B = distance.mahalanobis(point_B, center, inv_cov)
# 5. 揭晓结果
print(f"【欧氏距离】 觉得谁更远?")
print(f"点A (高壮): {dist_euc_A:.2f}")
print(f"点B (瘦高): {dist_euc_B:.2f}")
print(f"结论:欧氏距离认为 点A 更异常。\n")
print(f"【马氏距离】 觉得谁更远?")
print(f"点A (高壮): {dist_mah_A:.2f}")
print(f"点B (瘦高): {dist_mah_B:.2f}")
print(f"结论:马氏距离认为 点B 更异常(因为它偏离了数据的相关性趋势)!")代码解析:为什么这么写?
-
协方差矩阵 (
cov):这是马氏距离的灵魂。[25, 25]这一项表示 X 和 Y 是一起变大变小的。如果这里是 0,马氏距离就会退化成欧氏距离。 -
np.linalg.inv:马氏距离的公式里有一个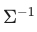 (协方差矩阵的逆)。这就好比把那个拉伸的“椭圆”数据强行压缩回“正圆”,从而让不同方向的单位统一。
(协方差矩阵的逆)。这就好比把那个拉伸的“椭圆”数据强行压缩回“正圆”,从而让不同方向的单位统一。 -
结果对比:运行代码你会发现,欧氏距离觉得
185cm/80kg的人离谱(因为离中心远),但马氏距离觉得172cm/60kg的人更离谱(因为他的比例不符合大众规律)。
4. 进阶深潜:底层逻辑与陷阱
数学本质:换个角度看世界
马氏距离的数学公式是:
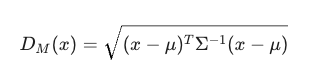
如果不看中间的 ,这就是欧氏距离。
的作用其实就是**“归一化”**。它做了两件事:
-
旋转坐标轴:通过主成分分析(PCA)的思想,把由于相关性而倾斜的数据轴转正。
-
缩放坐标轴:把扁长的椭圆拉伸或压缩成标准圆。
常见陷阱
-
样本量不足:计算马氏距离需要计算协方差矩阵。如果你的样本量比维度还少(比如 3 个样本,5 个特征),协方差矩阵是不可逆的(Singular Matrix),代码会直接报错。
-
非线性分布:马氏距离假设数据大体服从高斯分布(正态分布),即形状是椭圆的。如果你的数据分布像个“香蕉”或者“甜甜圈”,马氏距离就失效了。
-
对异常值敏感:计算协方差矩阵时,如果数据集中本身就已经混入了极端的异常值,它们会把“椭圆”拉歪,导致后续的距离计算不准。
最佳实践
-
应用场景:异常检测(信用卡欺诈、工业设备故障)、分类问题(LDA算法基础)、推荐系统(计算用户相似度)。
-
优化:在使用前,先对数据进行清洗,或者使用稳健协方差估计(Robust Covariance Estimation)(如 scikit-learn 中的
EllipticEnvelope)来减少异常值对“尺子”本身的干扰。
5. 总结与延伸
一句话总结:
欧氏距离只看物理距离,而马氏距离结合了统计规律,它能识别出那些**“虽然离得近,但是没站对队”**的隐形异常值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号