告别样本不平衡噩梦:Focal Loss 让你的模型学会“划重点”
1. 引言:由于“太聪明”而导致的失败
你是否遇到过这种令人抓狂的场景?
你在训练一个癌症检测模型,数据集中 99% 都是健康样本(负样本),只有 1% 是患病样本(正样本)。你满怀期待地跑完训练,发现模型的准确率(Accuracy)高达 99%!
你兴奋地打开预测结果一看,心凉了半截:模型把所有样本都预测成了“健康”。
它学会了一个“作弊技巧”:既然健康样本那么多,我只要无脑猜“健康”,由于基数大,总损失(Loss)依然很低。但在目标检测(Object Detection)中,这更是灾难——图片中绝大部分是背景(天空、马路),真正的物体(车、行人)少之又少。
传统的 交叉熵损失(Cross Entropy Loss, CE) 在这里失效了,因为它对待所有样本太“公平”了。
解决方案:我们要介绍的主角 Focal Loss(出自何恺明大神的 RetinaNet 论文),它的出现就是为了解决这种**极端的正负样本不平衡(Class Imbalance)**问题。它强迫模型停止在简单的背景上浪费时间,转而关注那些难以分类的物体。
2. 概念拆解:刷题策略的博弈
生活化类比:学霸的刷题法
想象你是一个准备高考的学生(模型),你的时间(计算资源/梯度更新)是有限的。你手里有一本包含 1000 道题的练习册(数据集):
-
900 道是“1+1=?”(简单样本 / 背景):这类题你闭着眼都能做对。
-
100 道是“微积分大题”(困难样本 / 前景):这类题很难,你经常做错。
传统 Cross Entropy (CE) 的策略:
不管题目难易,每做一道题,老师都按同样的标准计分。虽然做对一道“1+1”贡献的分数很少,但因为有 900 道,它们加起来的“总分权重”依然碾压了那 100 道微积分。结果就是:你为了维持总分不掉,整天都在重复做“1+1”,根本没精力去攻克微积分。
Focal Loss 的策略:
老师换了一种计分方式——“划重点”。
-
如果你对某道题非常有把握(比如置信度
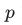 > 0.9),老师说:“这题你已经会了,它的分值权重降为几乎为 0。”
> 0.9),老师说:“这题你已经会了,它的分值权重降为几乎为 0。” -
如果你对某道题很没底(做错,或者置信度低),老师说:“这题权重保持不变,甚至相对变大。”
结果:那 900 道简单题的总权重被疯狂打折(Down-weight),你的注意力被迫转移到了那 100 道微积分上。
核心原理图解
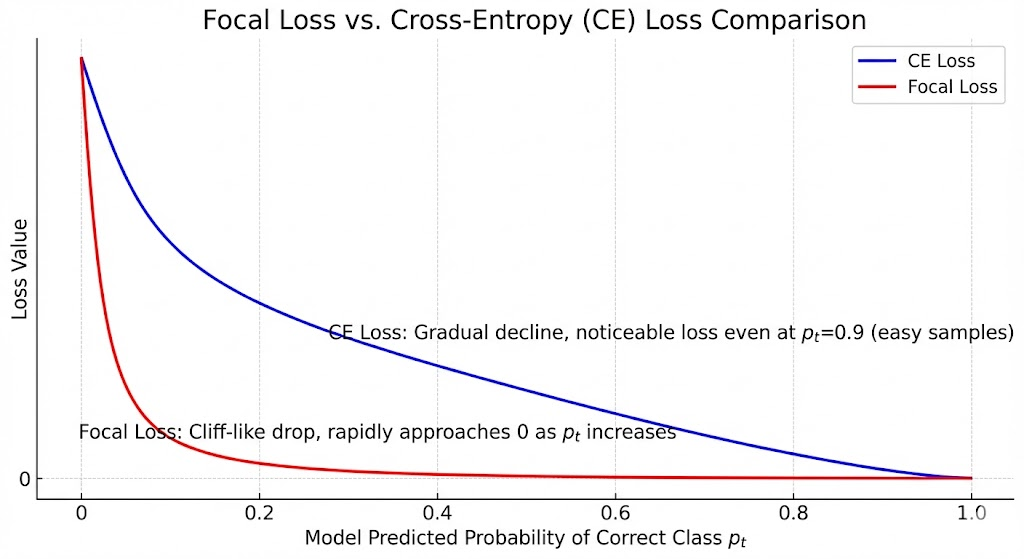
这张经典的对比图:
-
横轴是模型预测正确类别的概率
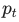 (从 0 到 1)。
(从 0 到 1)。 -
纵轴是 Loss 值。
-
蓝色线(CE Loss):随着
接近 1(模型很自信),Loss 缓慢下降,但即使是=0.9$ 这种简单样本,依然会有一定的 Loss 值。 -
红色线(Focal Loss):当
变大时,Loss 断崖式下跌,迅速趋近于 0。这意味着,只要模型稍微有点自信,这个样本就不再产生 Loss,不再贡献梯度。
3. 动手实战:PyTorch 实现
Focal Loss 的公式看起来有点吓人,但其实只有两个核心参数。
公式原型:
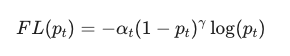
-
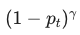 :调节因子(Modulating Factor)。这是灵魂!如果样本很简单( 大),这个因子就趋近于 0;如果样本很难(小),这个因子就接近 1。 控制打折的力度。
:调节因子(Modulating Factor)。这是灵魂!如果样本很简单( 大),这个因子就趋近于 0;如果样本很难(小),这个因子就接近 1。 控制打折的力度。 -
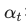 :平衡变体。用来处理正负样本本身的比例问题。
:平衡变体。用来处理正负样本本身的比例问题。
Hello World 代码
要在 PyTorch 中实现它,我们通常结合 BCEWithLogitsLoss 以保证数值稳定性。
import torch
import torch.nn as nn
import torch.nn.functional as F
class FocalLoss(nn.Module):
def __init__(self, alpha=0.25, gamma=2.0, reduction='mean'):
"""
初始化 Focal Loss
Args:
alpha (float): 平衡正负样本权重的因子 (通常取 0.25)
gamma (float): 聚焦参数,控制对简单样本的降权程度 (通常取 2.0)
reduction (str): 输出模式 'none', 'mean', 'sum'
"""
super(FocalLoss, self).__init__()
self.alpha = alpha
self.gamma = gamma
self.reduction = reduction
def forward(self, inputs, targets):
# 1. 计算二分类交叉熵 (BCE)
# 使用 BCEWithLogitsLoss 自带 Sigmoid,数值更稳定
bce_loss = F.binary_cross_entropy_with_logits(inputs, targets, reduction='none')
# 2. 获取预测概率 pt
# inputs 是 logits,需要手动 sigmoid 得到概率
pt = torch.exp(-bce_loss)
# 3. 计算调节因子 (1 - pt)^gamma
focal_weight = (1 - pt) ** self.gamma
# 4. 加入 Alpha 平衡因子
# 如果 target是1,用 alpha;如果 target是0,用 (1-alpha)
if self.alpha is not None:
alpha_weight = torch.where(targets == 1, self.alpha, 1 - self.alpha)
focal_loss = alpha_weight * focal_weight * bce_loss
else:
focal_loss = focal_weight * bce_loss
# 5. 输出结果
if self.reduction == 'mean':
return focal_loss.mean()
elif self.reduction == 'sum':
return focal_loss.sum()
else:
return focal_loss
# --- 测试运行 ---
# 假设模型输出 Logits (未经过 Sigmoid)
inputs = torch.randn(10, requires_grad=True)
# 假设真实标签 (0 或 1)
targets = torch.empty(10).random_(2)
criterion = FocalLoss(alpha=0.25, gamma=2)
loss = criterion(inputs, targets)
print(f"Calculated Focal Loss: {loss.item()}")代码解析:为什么这么写?
-
binary_cross_entropy_with_logits: 我们不直接输入概率,而是输入 Logits。这是为了利用 Log-Sum-Exp 技巧防止梯度爆炸或消失,比手动写log(sigmoid(x))更安全。 -
pt = torch.exp(-bce_loss): 这是一个数学小技巧。因为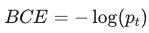 ,所以
,所以 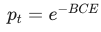 。这样我们就拿到了模型对当前真实类别的预测概率。
。这样我们就拿到了模型对当前真实类别的预测概率。 -
alpha_weight: 这是一个静态权重的分配。通常负样本(背景)太多,我们会把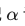 设小一点(比如 0.25),稍微降低负样本的整体权重,同时结合 Focal Term 动态调整难度权重。
设小一点(比如 0.25),稍微降低负样本的整体权重,同时结合 Focal Term 动态调整难度权重。
4. 进阶深潜:陷阱与最佳实践
常见陷阱
-
盲目使用:如果你的数据集是平衡的(例如 CIFAR-10 分类),使用 Focal Loss 可能反而导致模型无法收敛,或者效果不如 Cross Entropy。它不是万金油,它是特效药。
-
初始化地雷:在使用 Focal Loss 训练目标检测网络的初期,背景样本极多。如果输出层的 bias 初始化为 0(即预测概率为 0.5),会有巨大的 Loss 导致训练不稳定。
-
Tip: 将最后一层分类层的 bias 初始化为
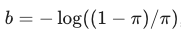 ,其中
,其中 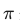 是先验概率(如 0.01)。这让模型一开始就倾向于预测“背景”,从而稳定初期 Loss。
是先验概率(如 0.01)。这让模型一开始就倾向于预测“背景”,从而稳定初期 Loss。
-
最佳参数配置
虽然论文中通过实验得出:
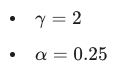
是针对 COCO 数据集的最佳组合,但实际业务中:
-
如果你发现简单样本实在太多(极度不平衡),尝试增大
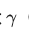 (如
(如 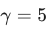 ),更狠地抑制简单样本。
),更狠地抑制简单样本。 -
如果正样本非常非常稀缺,尝试增大
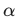 给正样本更多“关注度”。
给正样本更多“关注度”。
5. 总结与延伸
一句话总结
Focal Loss 通过降低“简单且分类正确”样本的权重,迫使模型将注意力集中在“稀缺且难以分类”的样本上,从而解决了严重的类别不平衡问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号