MYSQL5.5/5.7优化摘要
- 视频地址:https://www.bilibili.com/video/av29072634/?p=1,http://www.icoolxue.com/album/show/80
https://blog.csdn.net/weixin_38003389/article/details/83746223
字段请使用utf8mb4字符集

3.对mysql优化时一个综合性的技术,主要包括(硬件、配置、设计、执行、规模)
SQL级
a: 表的设计合理化(符合3NF)
b: 添加适当索引(index) [四种: 普通索引、主键索引、唯一索引unique、全文索引]
e: 存储过程 [模块化编程,预编译,可以提高速度]
服务器级
c: 分库分表(水平分割、垂直分割)
d: 主从复制,读写分离 [写: update/delete/add]
f: 对mysql配置优化 [配置最大并发数my.ini, 调整缓存大小,默认为100,max_connection=1000 ]
部分数据库连接池会与mysql保持长连接不放,所以分布式/集群时注意保证数据库有充足的链接
g: mysql服务器硬件升级
h: 定时的去清除不需要的数据,定时进行碎片整理(MyISAM)
I: 将历史数据转移
4. 3NF
1NF: 即表的列的具有原子性,不可再分解
2NF: 表中的记录是唯一的, 就满足2NF
3NF: 即表中不要有冗余数据
反3NF : 但是,没有冗余的数据库未必是最好的数据库,有时为了提高运行效率,就必须降低范式标准,适当保留冗余数据,减少多表关联。
5 show status/variables like 'name' 检查配置
show status like 'uptime' ; (mysql数据库启动了多长时间)
show stauts like 'com_select' show stauts like 'com_insert' ...类推 update delete(显示数据库的查询,更新,添加,删除的次数)
show [session|global] status like .... 如果你不写 [session|global] 默认是session 会话,指取出当前窗口的执行,如果你想看所有(从mysql 启动到现在,则应该 global)
show status like 'connections';//显示到mysql数据库的连接数
show status like 'slow_queries';//显示慢查询次数 默认10s以上是慢查询 推荐缩小
show global variables like 'long_query_time'; //可以显示当前慢查询时间
set global slow_query_log='ON' //(临时开启慢查询日志,mysql重启时失效)
set long_query_time=1 ;//可以修改慢查询时间s(重启失效)
set global max_connections=500 ;//修改最大链接数
show variables like 'slow_query%' :slow_query_log是否开启慢查询日志,1表示开启,0表示关闭。
slow-query-log-file:新版(5.6及以上版本)MySQL数据库慢查询日志存储路径。可以不设置该参数,系统则会默认给一个缺省的文件host_name-slow.log
log-slow-queries :旧版(5.6以下版本)MySQL数据库慢查询日志存储路径。可以不设置该参数,系统则会默认给一个缺省的文件host_name-slow.log
log_queries_not_using_indexes:未使用索引的查询也被记录到慢查询日志中(可选项)。
log_output:日志存储方式。log_output='FILE'表示将日志存入文件,默认值是'FILE'。log_output='TABLE'表示将日志存入数据库,这样日志信息就会被写入到mysql.slow_log表中。MySQL数据<br>库支持同时两种日志存储方式,配置的时候以逗号隔开即可,如:log_output='FILE,TABLE'。日志记录到系统的专用日志表中,要比记录到文件耗费更多的系统资源,因此对于需要启用慢查询日志,又需要能够获得更高的系统性能,那么建议优先记录到文件。
6 慢查询日志
记录超过long_query_time时间的sql语句
在默认情况下,我们的mysql不会记录慢查询,需启动mysql时候,指定记录慢查询日志 启动指令 bin\mysqld.exe - -safe-mode - -slow-query-log [mysql5.5 可以在my.ini指定](安全模式启动,数据库将操作写入日志,以备恢复);bin\mysqld.exe –log-slow-queries=d:/abc.log [低版本mysql5.0可以在my.ini指定]
推荐临时开启:set global slow_query_log =1 (mysql重启时失效)
先关闭mysql服务,再启动, 如果启用了慢查询日志,默认把这个文件放在my.ini 文件中记录的位置
#Path to the database root
datadir="C:/Documents and Settings/All Users/Application Data/MySQL/MySQL Server 5.5/Data/"
mysqldumpslow 慢日志分析工具
命令:
-s 按照那种方式排序
c:访问计数
l:锁定时间
r:返回记录
al:平均锁定时间
ar:平均访问记录数
at:平均查询时间
-t 是top n的意思,返回多少条数据。
-g 可以跟上正则匹配模式,大小写不敏感。举例:
得到返回记录最多的20个sql::mysqldumpslow -s r -t 20 /database/mysql/mysql_slow.log(日志路径)
得到平均访问次数最多的20条sql:mysqldumpslow -s ar -t 20 sqlslow.log
得到平均访问次数最多,并且里面含有ttt字符的20条sql:mysqldumpslow -s ar -t 20 -g "ttt" sqldlow.log
https://blog.csdn.net/sunyuhua_keyboard/article/details/81204020
https://www.cnblogs.com/moss_tan_jun/p/8025517.html(包含win/linux下使用)
执行结果格式
命令解析:排序(-s)按执行次数(c)倒序(-a)
C:\Program Files\MySQL\MySQL Server 5.5\bin>perl mysqldumpslow.pl -s c -a c:\mysql\log\mysqlslowquery.log
Reading mysql slow query log from c:\mysql\log\mysqlslowquery.log
执行次数 Count: 3 执行时间Time=0.27s (0s) 锁定时间Lock=1.67s (1s) 发送行数Rows=1.0 (1), 执行地址root[root]@localhost
内容:select count(*) from lm_d_plan
Count: 1 Time=0.00s (0s) Lock=0.00s (0s) Rows=0.0 (0), 0users@0hosts
C:\Program Files\MySQL\MySQL Server 5.5\bin\mysqld, Version: 5.5.22-log (MySQL Community Server (GPL)). started with:
TCP Port: 3306, Named Pipe: (null)
SQL解析顺序
影响索引的最左命中。一定是解析顺序在前的字段,排在索引左边。
解析顺序 : from..on..join..where..group by..having..seletc distinct..order by limit
https://blog.csdn.net/qq_27529917/article/details/78447882
解析过程简述:
1、确定主驱动表
有A,B,C三个表做join查询。Mysql先要通过where条件推断结果集,没有条件则按照全表计算,从小到大依次解析表。
假设推断后,A=10行,B=5行,C=15行 ,中间MySQL还会有一些缓存或join顺序优化,同行数的看where能否命中索引等。
假定优化后解析顺序 :B>A>C。确定主驱动表=B。
2、开始解析执行,索引生效
B:作为最小驱动表,执行where条件取得结果集1。此时where条件判定索引命中。
A:与结果集1执行join on生成临时表(判定索引),where条件过滤取得结果集2。
C:与A相同,与结果集2执行join on生成临时表,where条件过滤取得结果集3。
可以看到索引顺序,除主驱动表外都是先on再where。下面会有具体测试案例。
7 索引 (主键索引/唯一索引/全文索引/普通索引)
primary key 有两个作用,一是约束作用(constraint),用来规范一个存储主键和唯一性,但同时也在此key上建立了一个主键索引;
PRIMARY KEY 约束:唯一标识数据库表中的每条记录;主键必须包含唯一的值;主键列不能包含 NULL 值;每个表都应该有一个主键,并且每个表只能有一个主键。(PRIMARY KEY 拥有自动定义的 UNIQUE 约束)
primary key(name,age) #复合主键
unique key 也有两个作用,一是约束作用(constraint),规范数据的唯一性,但同时也在这个key上建立了一个唯一索引;
UNIQUE 约束:唯一标识数据库表中的每条记录。UNIQUE 和 PRIMARY KEY 约束均为列或列集合提供了唯一性的保证。(每个表可以有多个 UNIQUE 约束,但是每个表只能有一个 PRIMARY KEY 约束)
unique index(`userId` ,`taskId`,`date`) #复合唯一索引
唯一索引注意 null 是可以重复的。例如:unique index(`userId` ,`phone`),可以重复插入不报错:('A00001',null)。
因此在创建属于唯一索引的列时,最好指定字段值不能为空,在已有值为NULL的情况下,创建的字段不允许为空,且默认值为空字符。如果已经创建了默认值为NULL的字段,则先将其update为空字符,然后再修改为NOT NULL DEFAULT ‘’。
foreign key也有两个作用,一是约束作用(constraint),规范数据的引用完整性,但同时也在这个key上建立了一个index;
索引的代价:占用磁盘空间,dml操作变慢
适合建索引列:
a:字段在where,on,order,group经常使用
b: 该字段的内容多样化,唯一性高(容易缩小范围)
c: 字段内容不是频繁变化.
使用索引的注意事项:
a.单表查询一次只能命中一个索引。影响:查找,排序
多表查询时通过EXPLAN可以看到各个表的子查询命中的索引情况和执行顺序
b.unique字段可以为NULL,并可以有多NULL, 但是如果是具体内容,则不能重复
c.复合索引从左边按顺序开始匹配,注意sql解析顺序,避免跨列引起索引失效。
把可能索引失效的列尽可能放在KEY最后
使用最频繁、唯一性高的,解析顺序靠前的字段 放在最左。
创建key(a,b,c)后,不用再创建(a,b),(a)索引
d.BTREE全覆盖索引,查询时不用回表
i. join on 条件字段索引,= 左右哪个字段循环频率高,建立索引 。
定位驱动表: 左外联左表驱动,右外联右表驱动,内联自动小表驱动。内联可以通过表自身大小和EXPLAN解析select扫描的行数来判断那个表为驱动表。
一般情况:被驱动表on条件一定要加索引(条件允许也可两表都建立索引)。因为被驱动表一般是主表循环的内嵌套循环,执行频率高。
且where条件中尽量能够过滤一些行将驱动表变得小一点
l.主键自带索引,会自动加到复合索引的最右侧
J.TEXT,长字符串,若需要查询则可以建立前缀索引。建立前先观察不同长度前缀的区分度,确定前缀长度
索引失效总结: 命中不连续,类型转换,列计算,null值判断,负向(否)条件,in/or,like ‘%a’,范围查询右边key(自身也可能失效)。某些情况是概率事件,不一定百分百触发。
e.对于使用like的查询,查询如果是 ‘%aaa’ 不会使用到索引 (索引失效)
f.某列是范围查询,其索引右边列无法使用索引。(索引失效,多范围条件注意)
例如:key(a,b,c) => where a=1 and b>0 and c<0 => 只会用到key(a,b)或key(a) 有不确定性
g.如果条件中有or,要求or包含的所有字段都必须建立索引,其中一个有索引也无效 (索引失效)
h.避免在where条件中进行 null值判断、in、负向条件(!=、<>、not in、not like、not exists ) 这会使索引失效,所以把这些列放在复合索引最后位置,或是优化为其他形式(例如:用left join + id=null 代替not in )
j.不要在索引字段做操作(计算,函数,类型转换等),会引起索引失效。例如:where a+1=1
k.显式/隐式类型转换,会引起索引失效 例如:where name=1
H.可以使用全覆盖索引挽救索引失效
例如:select * from user where name like '%a%',其必然索引失效。
可以建立key(name,id),改变SQL为: select name,id from user where name like '%a%' 这样虽然索引失效,但是可以挽救为use index。
8.sql语句的优化
避免索引失效
select:
a.可以使用关联来替代子查询。因为使用join,MySQL不需要在内存中创建临时表。(5.5及以下)
b.确保关联查询 on/using 条件命中索引,内联顺序的第二个表建索引,左外联建左表,右外联建右表
c.left join 尽可能小表在左驱动大表,join相当于for循环嵌套,次数少的循环放在最外层。inner join mysql会自动优化。也可以尝试用straight join 代替inner join,强制驱动表。
条件 “=” 小表字段在左边
d.避免使用select *,减少IO负担。(测试字段多时,时间消耗有可能成倍增长)
e.发现扫描行数远大于结果,则考虑优化查询:使用覆盖索引/修改表结构/复杂查询分割多个小查询
f.尽可能使用索引覆盖扫描select
g.select ..from table where in/exists (子查询),主查询结果ROW大用IN反之用exist
h.left join where id != null 可以代替 not in () 。或是先插入临时表再delete
join、between 可以代替 in ()。in中元素不要太多,否则必须被代替。
i.合理运用临时表,比如有一张全年表,现在只需要一个月数据,且这个数据后边要反复查询/处理,则先插入临时表,以后就不用处理全年表啦
j.避免使用过多的join 关联表。于Mysql来说,是存在关联缓存的,缓存的大小可以由join_buffer_size参数进行设置
在Mysql中,对于同一个SQL多关联(join)一个表,就会多分配一个关联缓存,如果在一个SQL中关联的表越多,
所占用的内存也就越大。如果程序中大量的使用了多表关联的操作,同时join_buffer_size设置的也不合理的情况下,就容易造成服务器内存溢出的情况,就会影响到服务器数据库性能的稳定性同时对于关联操作来说,会产生临时表操作,影响查询效率
Mysql最多允许关联61个表,建议不超过5个
k.拆分大sql变为小sql。大SQL:逻辑上比较复杂,需要占用大量CPU进行计算的SQL。MySQL 一个SQL只能使用一个CPU进行计算。SQL拆分后可以通过并行执行来提高处理效率
L.不会有重复值时使用UNION ALL 。UNION 会把两个结果集的所有数据放到临时表中后再进行去重操作, UNION ALL 不会再对结果集进行去重操作
group:
a.在使用group by 分组查询是默认分组后,还会排序,可能会降低速度。
在group by 后面增加 order by null 就可以防止排序.
b.group by/order by 只涉及一个表的字段,才能使用索引。group by 可以拆分成子查询,从而使其只涉及一个表。
c.用join关联条件做group by条件,效率更高
limit:
a.尽可能使用索引覆盖扫描select
b.order by 命中索引
c.当只需要一条结果时手动limit 1,可以有效减少扫描量。
d.大表分页优化。例如:表有主键ID自增,每页有10条数据,想显示第二页数据,传统思路limit 11,10。优化思路 where id>10 limit 10。
order by :
a.避免使用select *
b.选择单路(4之后默认)/双路排序方法,设置max_length_for_sort_data扩大排序缓冲区
c.复合索引,按照解析顺序不要跨列
d,排序字段,同升同降 order by a desc,b desc
优化举例:
例1:
order by 举例对比:有索引 key(a,b,c,d)
where +order by 从左命中不要跨列
select a,b,c,d from table where a=1 and d=1 and c=1 and b=1
(using index全覆盖查询, 实际用到 key(a,b,c,d))
select a,b,c,d from table where a=1 and b=1 and d=1 order by c
(using index,using where 回表查询 ,因为从左命中d跨列导致d无法用到索引 ,实际使用 key(a,b))
select a,b,c,d from table where a=1 and d=1 order by c
(using index,using where,using fliesort 回表查询+文件排序:因为从左命中orderby跨列 key(a))
select a,b,c,d from table where a=1 and d=1 order by b,c
(using index,using where :对比上个例子没有using fliesort,因为where +orderby没有索引跨列,但是由key_len可知道,实际使用只有 key(a),只是避免了文件排序)
例2:
Sql解析顺序影响索引命中,in()可能出现索引失效
select b from table where a=1 and c in (1,2) order by ckey(a,c,b) 效果最好,受Sql解析顺序影响,b放在where条件之后
索引中将c放在a之后,即使c in ()索引失效, a 索引还是有效
例3:
多表JOIN 解析对比索引命中。请先阅读上面的"sql解析顺序"
表user_zhw: 列( userid,zhwid,beizhu ) union_key(userid,zhwid) 当前 7 rows
表zhwdoc: 列(id ,name) KEY(id) 当前 3 rows
select * from user_zhw
join zhwdoc on zhwdoc.id=user_zhw.zhwid
where zhwdoc.name ='prouser'
and user_zhw.userid=1只执行前两行:解析

同ID由上至下执行,sql解析顺序规则(见上面),先锁定结果可能最少的表,因为只执行前两行无where,但是zhwdoc总行数少所以其为主驱动表。zhwdoc先执行where过滤因为没where所有ALL扫描。之后on条件关联user_zhw表没有命中索引ALL扫描。扫描行数3+7。
执行前三句:解析

同ID由上至下执行。通过where条件确定zhwdoc结果集较小作为主驱动表。
zhwdoc先执行where过滤,没有命中索引ALL扫描。之后on条件关联user_zhw表没有命中索引ALL扫描。扫描行数3+7。
全部执行:解析

同ID由上至下执行。 通过where条件确定user_zhw命中索引其结果集较小作为主驱动表。
user_zhw先执行where过滤且命中部分索引(len)。之后on条件关联zhwdoc表索引命中。扫描行数1+1。
例4: 误区
表user_zhw: 列( userid,zhwid,beizhu ) union_key(userid,zhwid) 当前 7 rows
select userid,zhwid from user_zhw where zhwid=1 
上面where条件应该无法命中索引,但是解释结果命中了全部索引union_key长度,但是看扫描行数为全表扫描。 此处命中的索引是因为Using index,既索引全覆盖,select字段不用回表查询。where条件并没有命中,所以还是全表扫描。多表join时也要特别注意,不要只看key列,一定要以rows为准。但是也说明在where无法命中情况下 ,全覆盖索引能稍微弥补
9.EXPLAN
a.EXPLAN是近似结果,可能与真相相差甚远,且只能解释select
b.id,type,key,row,extra几个字段比较关键
id:表示执行顺序,由大到小执行,id相同时由上到下执行
type:ALL/index/range/ref/eq_ref/const/system/null 效率由低到高,一般以range/ref为目标
ALL:按行顺序全表扫描。一般百万以上出现ALL则必须优化
index:按索引顺序全表扫描,避免了排序。缺点是承担按索引顺序读取的开销
range:范围扫描。有范围的索引扫描。(between,><,in,or 且命中索引)
ref:索引访问/查找。返回所有匹配当个索引列的结果。
例如:select name from T where name="a" (name命中索引)
key:实际使用索引(where\on\select),只能命中一个。5.0后有索引合并
多表查询时通过EXPLAN (id)可以看到各个表的子查询命中的索引情况和执行顺序
key_len:判断使用索引前几个字段,例如 KEY(A,B,C) 使用到(A,B,C)和(A,B)长度不同
row:预估扫描的行数(直观检验)
extra:
using index :使用覆盖索引(不回表)
using where :可能部分受益于索引(需回表)
using temporary :需优化,排序使用临时表(group by 未命中索引)
using fliesort :需优化,文件排序 IO消耗(order by 未命中索引,where +orderby 从左命中不要跨列)
using join buffer : 需优化。
10 存储引擎
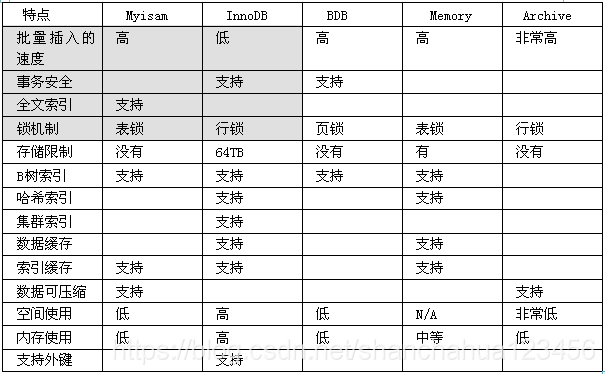
myisam,请一定记住要定时进行碎片整理
innoDB vs myisam:
InnoDB 支持事物+行级锁+支持外键+支持MVCC,不支持全文索引
11 锁
1 加行锁(命中索引):互斥锁X,其他线程不能再在此行上任何锁,其他线程可读不可写,直到当前线程提交事务。insert /update /select ...for update
共享锁S,所有可读不可写,共享锁可以叠加,之前的所有共享锁都解锁才能上互斥锁。select ...lock in share mode
commit 时解除锁
无论通过哪个索引命中此行,只要此行被锁住,其他线程都不能更新此行
2 没有命中索引,行锁会转为表锁
坑1:update table set name='sw' where name=1 ,假设有KEY(name),但是name=1发生类型转换,导致索引失效,执 行update产生表锁
表锁要等待所有行锁+表锁解锁
3 间隙锁:mysql为范围内不存在的行加锁
例如:update table set name='hh' where id<=3; 有key(id)。即使当前表中还没有id=2的行,mysql也会锁住id in (1,2,3) 三行内容。在update未提交之前,读/写/插入id=3的数据,就会阻塞
4 乐观锁(版本号 or 时间戳 or 临界条件)
提高数据库并发能力,避免超买超减等问题。本质上是CAS,要保证比较和赋值是原子性操作
比如: 在事务A中使用 update spkc set shl=shl-1 where id=1 and shl>0,判断受影响rows决定是否扣减成功是否向下执行。事务A执行update会上锁(注意命中索引,否则会上表锁),其他事务需要等待事务A提交再执行update。
https://blog.csdn.net/shanchahua123456/article/details/86571038
5 避免死锁,加速事务提交
https://www.cnblogs.com/LBSer/p/5183300.html
https://825635381.iteye.com/blog/2339434
5.1 以固定的顺序访问表和行,这样就避免了交叉等待锁的情形
5.2 大事务拆小、缩短事务提交时间、避免事务中有复杂逻辑/远程调用。
一定要保证事务方法不要无休止的不提交事务。比如方法中等待http/远程响应,或复杂逻辑等情况导致不能提交。
5.3 在同一个事务中,尽可能做到一次锁定所需要的所有资源。
5.4 为表添加合理的索引,命中索引上行锁。避免表锁,不容易死锁
5.5 避免gap锁
5.6 并发插入出现duplicate key重复键异常时,当前事务会默认加上S锁。这时当前事务再去申请X锁,就会死锁。
可以查看死锁日志
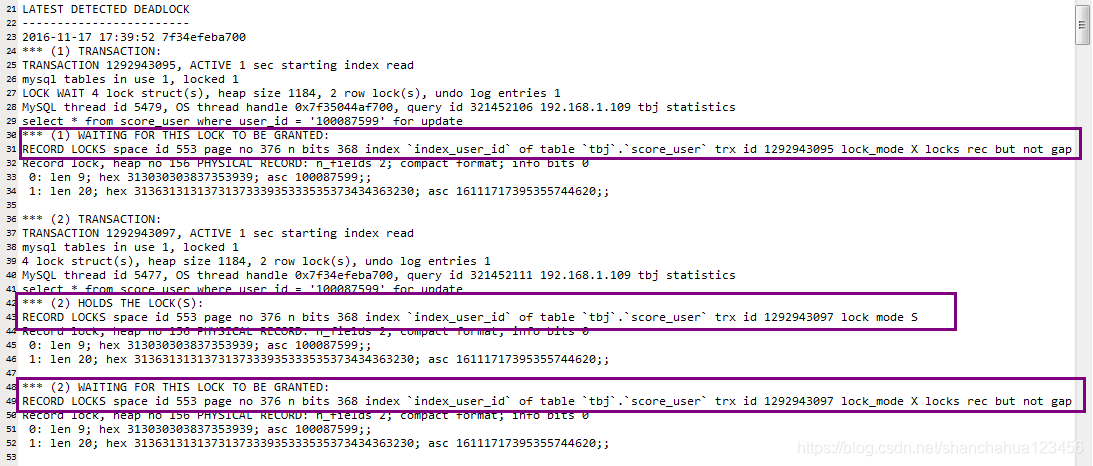

查看锁表
方法一 慢查询日志
方法二 MYSQL中执行
https://blog.csdn.net/miyatang/article/details/78227344
-- 查看那些表锁到了
show OPEN TABLES where In_use > 0;
--In_use列表示有多少线程正在使用某张表,Name_locked表示表名是否被锁
-- 查看进程号
show processlist;
--删除进程
kill 1085850;
--查看正在锁的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCKS;
--查看等待锁的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCK_WAITS; 12 日志
mysql日志的种类,一般来说,日志有五种,分别为:
错误日志:-log-err (记录启动,运行,停止mysql时出现的信息)
二进制日志:-log-bin (记录所有更改数据的语句,还用于复制,同步,恢复数据库用)
查询日志:-log (全部记录建立的客户端连接和执行的语句,量大,不建议生产中使用)
慢查询日志: -log-slow-queries (记录所有执行超过long_query_time秒的所有查询)
查询当前日志记录的状况:
mysql>show variables like 'log_%';(是否启用了日志)
mysql> show master status;(怎样知道当前的日志)
mysql> show master logs;(显示二进制日志的数目)
binlog
https://blog.csdn.net/a1010256340/article/details/80306952
https://www.cnblogs.com/xhyan/p/6530861.html
show variables like 'log_%'; (查看日志开启和保存路径)
show binary logs;(现有的binlog名字)
show global variables like "binlog%";(查看模式)
通过上边指令锁定日志文件路径
在linux中mysql执行(解析时间较长,注意缩短datetime)
docker需要进入运行的mysql容器执行
mysqlbinlog --start-datetime='2019-01-01 00:00:00' --stop-datetime='2019-06-18 23:01:01' -d 库名 /var/lib/mysql/binlog.000003
若打印的SQL语句为乱码,则需要base64解析 --base64-output=decode-rows
mysqlbinlog --base64-output=decode-rows -v --start-datetime='2019-01-01 00:00:00' --stop-datetime='2019-06-18 23:01:01' -d 库名 /var/lib/mysql/binlog.000003
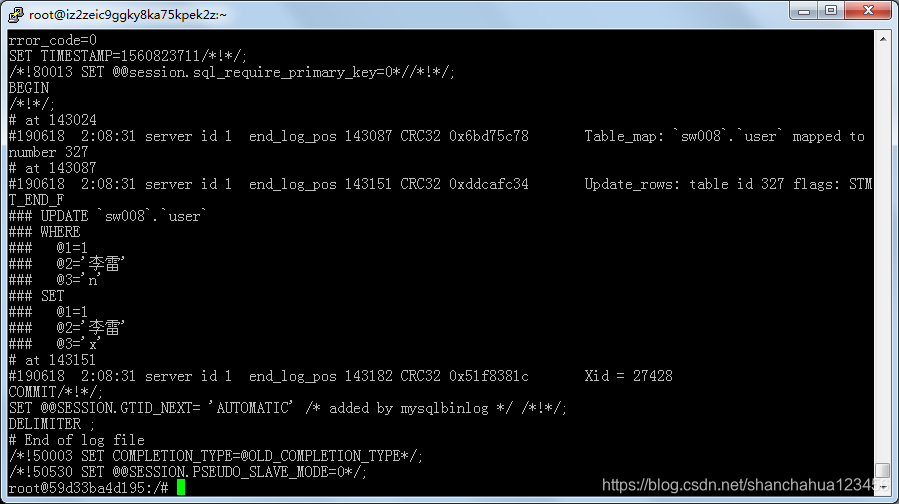
执行SQL:update user set beactive='n' where id=1 (user 表有三个字段)
可以看到update-log显示了所有字段的新旧状态。
13 安全
1 防止sql注入,所以最好使用预编译SQL执行 #{}
例如:注入 "or 1=1 " 作为条件欺骗
2 字符尽量使用单引号。尤其是sql_mode='ANSI_QUOTES'时,双引号会当识别符处理,引起条件丢失/赋值错误
14 大量数据操作
过大数据的(100万)批量写操作要分批多次操作
1.大批量操作可能会导致严重的主从延迟
2. binlog日志为row格式时会产生大量的日志
大批量写操作会产生大量日志,特别是对于row格式二进制数据而言,由于在row格式中会记录每一行数据的修改,我们一次修改的数据越多,
产生的日志量也就会越多,日志的传输和恢复所需要的时间也就越长,这也是造成主从延迟的一个原因
3. 避免产生大事务操作
大批量修改数据,一定是在一个事务中进行的,这就会造成表中大批量数据进行锁定,从而导致大量的阻塞,阻塞会对MySQL的性能产生非常大的影响
特别是长时间的阻塞会占满所有数据库的可用连接,这会使生产环境中的其他应用无法连接到数据库,因此一定要注意大批量写操作要进行分批
4.对于大表的修改使用pt-online-schema-change
1.原理: 会在原表的结构上建造一个新表 复制数据
2.避免延迟,修改时锁表
5.禁止super权限滥用
6.数据账号连接最小15 mysql缓存机制
https://blog.csdn.net/qzqanzc/article/details/80418125
mysql自身也有缓存机制,可以很大提高重复查询的执行效率
表碎片整理
https://www.cnblogs.com/wt645631686/p/8065099.html
OPTIMIZE TABLE table_name 会锁住整张表进行整理,且时间可能很长
 浙公网安备 33010602011771号
浙公网安备 33010602011771号