

BLIP-2
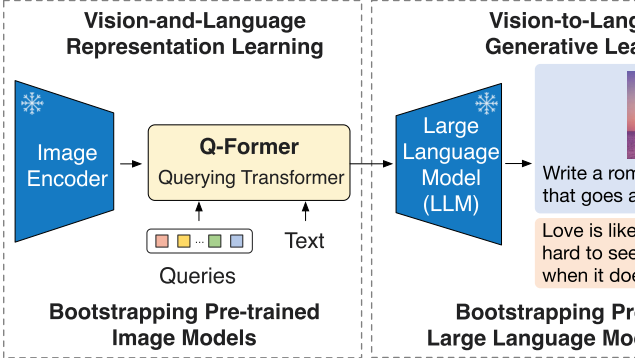 BLIP-2
BLIP-2
BLIP-2
如果模型适应不了任务,就让任务来适应模型
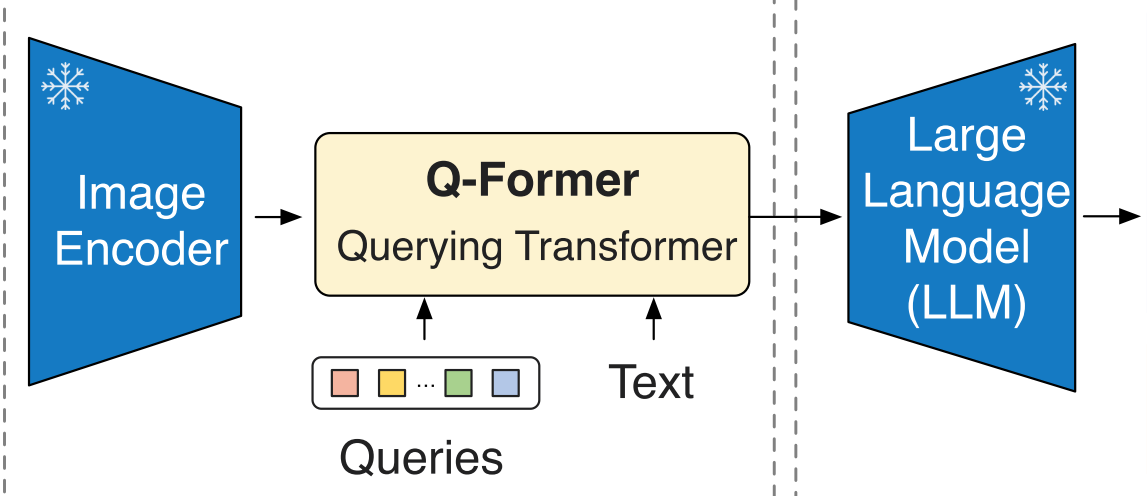
VLP(从ALBEF到BLIP-2)
传统
- 传统的方法难以融合多模态的特征(图像和文本的特征往往不处于同一维度),
- 数据噪声问题
ALBEF
ALign BEfore Fuse(融合前对齐)
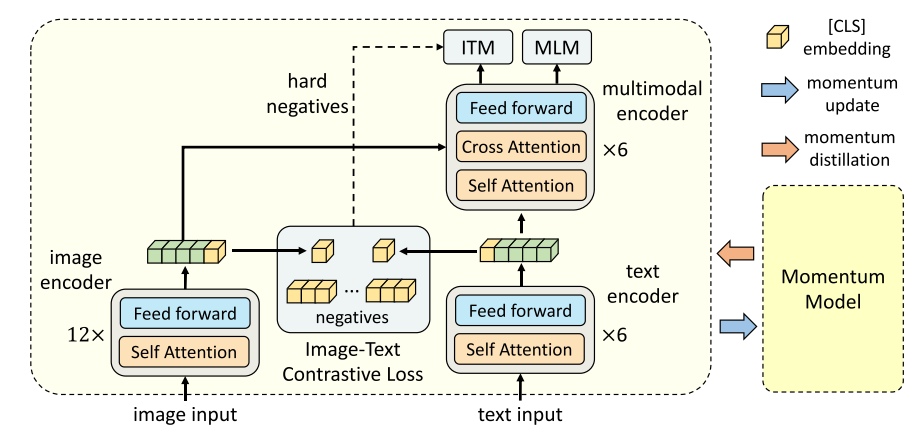
encoder
- 对于图像编码器,使用12-Layer visual transformer, 文本编码器和和多模态编码器均使用了6 layer transformer, 使用\(BERT_{base}\)去初始化,,加速收敛
- 图像的特征通过多模态编码器中的cross attention层与文本特征进行融合
ITC(图文对比学习)
实现ALBEF的核心结构
- 在图像和文本经过编码器转化为embeddings之后,选取其中的 [CLS] token 计算相似度
encode后,[CLS] token 往往可以表示整个文本/图像的特征信息 - Loss表现为图文特征之间的相似度,通过降低\(\mathcal{L}_{itc}\)使得两个encoder产生更加"相似"的embeddings.
- Momentum Distillation部分关系不太暂时略过
- 挖掘hard negatives供给ITM进行训练(增强区分相似样本的能力)
ITM(图文匹配)
相当于传统的融合后进行对齐,还会学习ITC提供的hard negatives
BLIP-2
解决的问题?
- 减少训练成本
- zero-shot(零样本)图生文
BLIP-2
预训练 一阶段:从冻结图像编码器学习引导视觉语言表示(Q-Former)
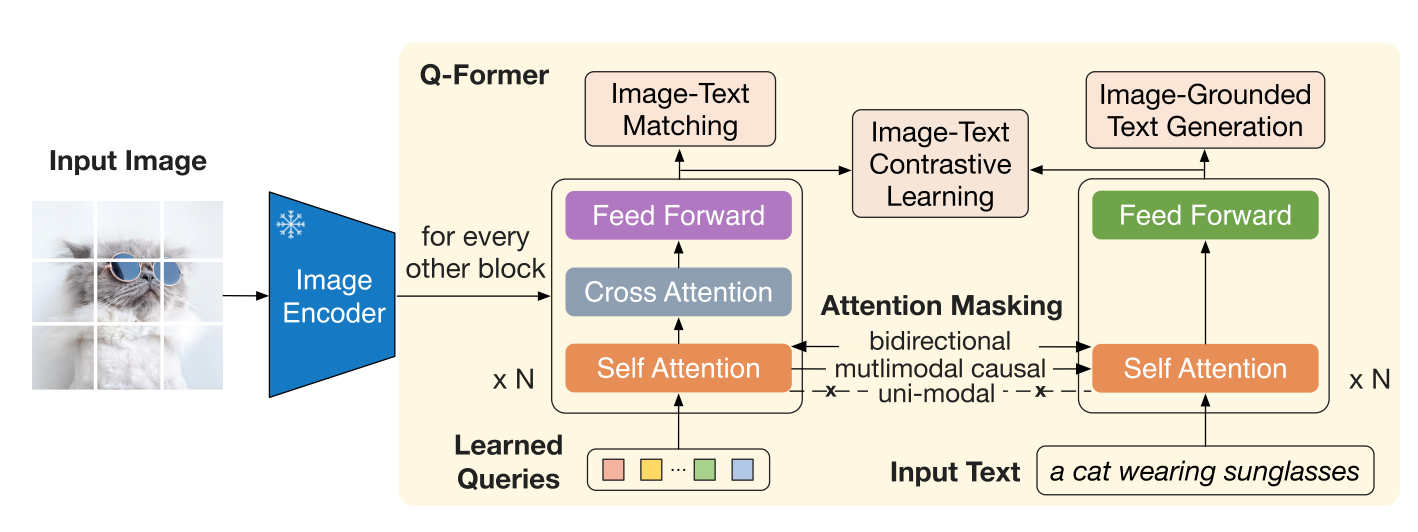
Queries(32 × 768)
32个768维向量,用于提取图文的表征
- 通过cross attention与图像的特征进行交互,self-attention与文本特征进行交互
Masking
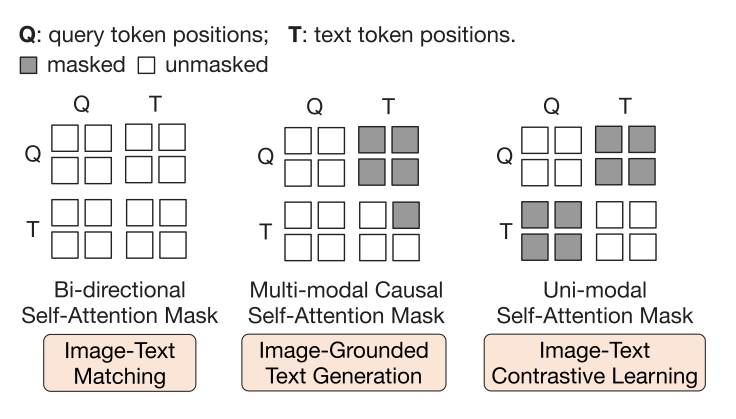
三种不同的掩码策略,控制图像与文本之间信息的交互
三个训练任务
ITC
与ALBEF中的ITC几乎一致,只不过将图像特征换成了Queries,此时对应图中Attention Masking中最下边的uni-modal,
这里Q(query token)与T(Text token)之间均被遮掩,互相不能看见,只能对自身做self-attention, 避免了信息泄露,符合ALBEF以更好地对齐模态
ITM
也与ALBEF中的ITM几乎一致,masking策略为bidirectional,即允许T,Q之间自由交换信息
ITG
由于 Q-Former 的架构不允许Queries和文本之间直接交互,因此这里首先通过Queries提取生成文本所需的图像信息,然后通过self-attention层传递给文本(对应图中的mutlimodal causal).
整个过程使用多模态因果自注意力掩码,具体来讲,Queries只能注意到Queries,文本可以注意到"之前的文本"和查询.
这样为了降低loss,Queries只能捕获有关文本的所有信息的视觉特征
- "Therefore, the queries are forced to extract visual features that capture all the information about the text."
另外需要注意的一点是,在第一阶段的训练中,图像编码器是处于冻结状态的,一来节省训练资源,二来这样相当于图像编码器从未受到过训练数据的影响,之后会提到的强大的泛化能力部分得益于此
预训练 二阶段:从冻结的LLM中引导视觉到语言的生成学习
FC层
用于将Queries投影至与文本embeddings相同的维度,此时Q-former已经具备了提取视觉特征的能力,所以Queries具有包含了文本信息的视觉表征
prepend
将FC层转化之后的向量与文本向量拼接在一起,此时它(Q)可以作为LLM的视觉prompts,
Q-former实际上帮助LLM提取了最重要的视觉信息,并且浓缩为32 × 768的向量,极大的减轻了LLM的负担(相较于传统的直接让LLM提取视觉特征),从而减轻遗忘问题.
相当于将多模态这种LLM做起来很困难的问题转化为LLM适应的问题,以发挥LLM的强大能力
- 这里有一个问题:让LLM提取视觉特征有什么不好?别人的回答有二:
- LLM训练代价很大
- 多模态训练材料不够,训练效果不好
标题就是引导冻结的LLM
对于两种LLM,分别设计了两种训练方式:
- 基于编解码器:语言建模loss
- 基于编码器:前缀语言建模loss
(这个是比较传统的方法了)
值得注意的是,这一过程中LLM也是冻结的,而训练也是通过让Q-former产生更好的视觉特征提示以引导LLM生成更准确、更符合图像内容的文本描述.所以LLM也始终没有接触训练数据,与之前的encoder一起,让BLIP-2具有了强大的泛化能力(训练的是模型提取特征能力本身而有更好的表现而不是直接追求更好的表现,感觉像动量)
注
- embeddings/嵌入 : 意为向量(text),特征(image)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号