
图书管理系统
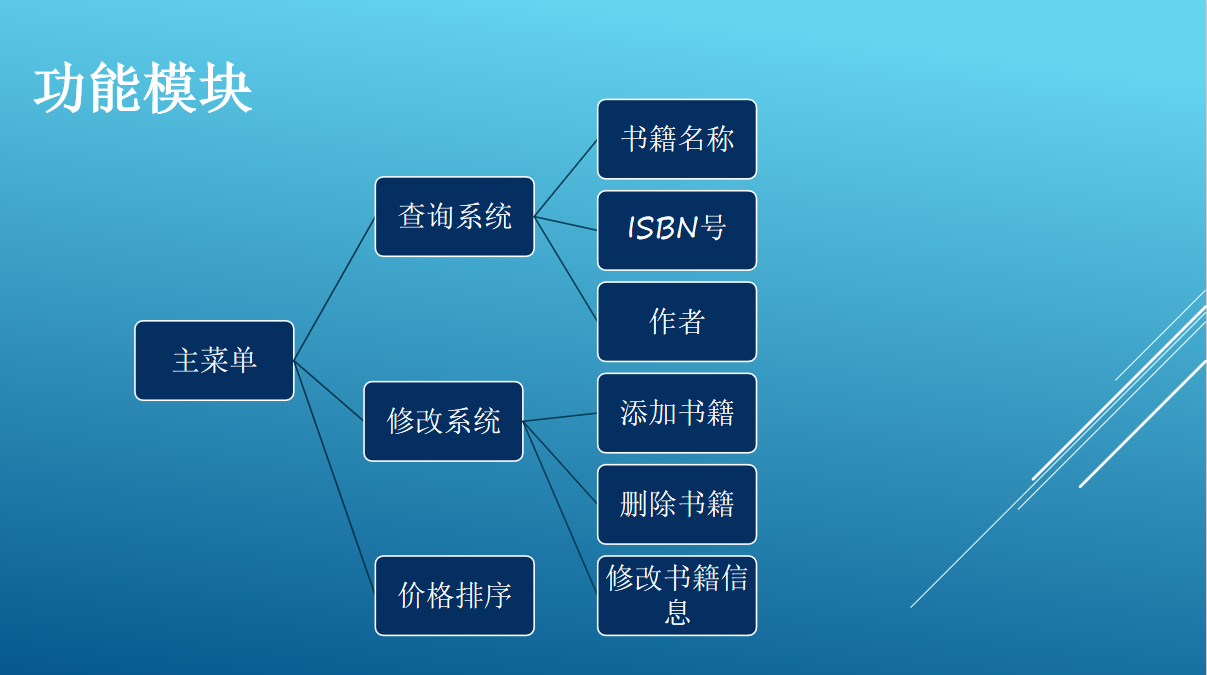
一.数据结构
结构体代码:
struct Book
{
int number;//书籍编号要求大小不超过 int 类型上限,要不然就用字符串存取
char name[30];// 名称上限为15个中文或30个英文
char author[20];//作者姓名上限为10个中文或20个英文
int price;//价钱要换带小数的就改double
};
struct Booklist
{
struct Book BOOK;
struct Booklist* next;
};
typedef Booklist *BookList,*BookNode;//BookNode代表链表中的结点
为什么要选择这样的数据结构?
1.为了更帅 为了使程序逻辑条理显得更加清晰
2.由于该系统有频繁的删除,插入,增加操作,如果使用顺序存储结构,那么会导致删除和插入两个操作极其不方便,所以本次使用了链式结构。
当然如果系统的查找操作占据了绝大部分,而且在保证内存浪费较小的情况下,顺序存储就会是我们的一个很好的选择。
为什么不直接在Book里面放上指针域而要用再定义一个新的结构体呢?
🌙 从我个人的理解来说,如果将指针域直接放在Book结构里面,虽然程序的代码写起来比这个要更方便的(字数上),但是Book函数从命名和逻辑上应该是
一个单纯包含了书本信息的结构体,在写代码的过程中,变量的命名也是十分重要的一环。
⭐ 那么如果Book结构单纯只包括书籍信息,由Booklist结构来放置next指针域,一个最大的好处就是让代码的逻辑和各自的功能更加清晰,当别人看到这个结
构体的时候,一下子就能明白过来:啊这个Book结构体是存放信息用的,这个Booklist结构体是链式存储用的,让代码更好理解。
二.关键代码部分
1.生成/保存书籍链表
int ListBook(BookList &L)//传入的是一个只有头结点的单链表
{
ifstream fp ("book.txt");
BookNode p,temp;
int n=0;
if(!fp.is_open())
{
cout<<"open error!"<<endl;
exit(1);
}
if(fp.get()==EOF) return 0;//如果这个文件里面什么都没有,那么直接返回,如果没有这一条语句,
//文件为空时会导致读取错误,产生错误链表
fp.close();//如果文件里面有东西,但是前面的get已经读取了一个字符了,这里如果不重新开关文件或者将文件指针光标
fp.open("book.txt");//返回到开头处,会导致读取错误。
while(1)
{
p=new struct Booklist;
fp>>p->BOOK.number>>p->BOOK.name>>p->BOOK.author>>p->BOOK.price;
n++;
if(L->next==NULL)
{
L->next=p;
p->next=NULL;
}
else
{
temp->next=p;
}
temp=p;
temp->next=NULL;
if(fp.eof())
{
cout<<"从库中导入数据成功"<<endl;
break;
}
}
fp.close();
return n;
}
/*-------------------------------------------------------------------------------------------*/
void SaveBook(BookList L)//传入的是完整的一个链表L
{
ofstream fp("book.txt");
BookNode p=L->next;
while(p)
{
fp<<p->BOOK.number<<'\t'<<p->BOOK.name<<'\t'<<p->BOOK.author<<'\t'<<p->BOOK.price;
if(p->next) fp<<endl;//末尾不要输出空白字符,否则会导致读取文件时产生错误
p=p->next;
}//依次将信息保存到txt文件中
fp.close();
}
2.Find类函数
BookNode FindBookByISBN(BookList L,int number)
{
BookNode p;
p=L->next;
while(p)
{
if(p->BOOK.number==number)
{
return p;
}
p=p->next;
}
return p;
}
/*-------------------------------------------------------------------------------------------*/
BookNode FindPrebookByISBN(BookList L,int number)
{
BookNode p;
p=L->next;
while(p->next)
{
if(p->next->BOOK.number==number)
{
return p;
}
p=p->next;
}
return p;
}
/*-------------------------------------------------------------------------------------------*/
BookNode FindBookByName(BookList L,char *Name)
{
BookNode p;
p=L->next;
while(p)
{
if(strcmp(p->BOOK.name,Name)==0)
{
return p;
}
p=p->next;
}
return NULL;
}
/*-------------------------------------------------------------------------------------------*/
BookList FindBookByAuthor(BookList L,char *Author)
{
BookNode p;
p=L->next;
while(p)
{
if(strcmp(p->BOOK.author,Author)==0)
{
return p;
}
p=p->next;
}
return NULL;
}
/*-------------------------------------------------------------------------------------------*/
void FindBookSum(BookList L)
{
int choose;
BookNode p;
cout<<"1.按ISBN号查询"<<endl<<"2.按书籍名称查询"<<endl<<"3.按书籍作者查询"<<endl<<"0.退出查询"<<endl;
cout<<"请输入操作项:";
cin>>choose;
int flag=1,number;
switch(choose)
{
case 1: int number;
cout<<"请输入要查询的ISBN号:";
cin>>number;
p=FindBookByISBN(L,number);
if(p)
PrintBook(p);
else cout<<"没有找到相对应的书籍。"<<endl;
break;
case 2: char Name[20];
cout<<"请输入要查询的书籍名称:"<<endl;
cin>>Name;
while(1)
{
p=FindBookByName(p,Name);
if(p)
{
PrintBook(p);
flag=0;
}
else
{
if(flag) cout<<"没有找到相关书籍"<<endl;
break;
}
}
break;
case 3: char Author[30];
cout<<"请输入要查询的书籍作者:";
cin>>Author;
while(1)
{
p=FindBookByAuthor(p,Author);
if(p)
{
PrintBook(p);
flag=0;
}
else
{
if(flag) cout<<"没有找到相关书籍";
break;
}
}
break;
case 0: return ;
}
}
划个重点解释一下: 这里有两个十分类似的函数:FindBookByISBN和FindPrebookByISBN,作用分别是返回找到的对应结点和返回对应结点的前一个结点。
为什么要有返回前一个结点的函数呢?
Δ为了更方便地进行删除操作。因为我们创建的是单向链表,单向链表一个巨大的缺陷就是它没有办法回头去找它的上一个结点。如果我们返回的
是查找到的结点,那么在删除时我们就必须要重新遍历一遍链表,找到被删除结点的上一个结点,才能顺利完成删除操作,这样显然很蠢,所以
增添了一个FindPrebookByISBN的小函数。
3.添加类函数
void AddBookMenu(BookList &L)//菜单类函数,作为添加的操作界面,传入的是整个链表L
{
struct Book Add;//定义一个结构体Book,用来保存要添加的书籍的信息
cout<<"请输入新的书籍ISBN号:";
cin>>Add.number;
cout<<endl<<"请输入新的书籍名称:";
cin>>Add.name;
cout<<endl<<"请输入新的书籍作者:";
cin>>Add.author;
cout<<endl<<"请输入新的书籍价格:";
cin>>Add.price;
if(!AddBook(L,Add))//函数细节在下面,为bool类型,返回false代表添加失败,返回true代表添加成功
{
cout<<"ISBN号重复,添加失败!"<<endl;
}
else
{
cout<<"添加成功!"<<endl;
}
}
/*-------------------------------------------------------------------------------------------*/
bool AddBook(BookList &L,struct Book Add)//传入的是链表L和要添加的书籍信息,用Book结构体储存
{
BookNode p;
p=FindBookByISBN(L,Add.number);
if(p) return false;//如果找到了对应的ISBN号,说明要添加的ISBN号重复了,那么不可以添加。
p=new struct Booklist;
p->BOOK=Add;
p->next=L->next;
L->next=p;
return true;
}
4.删除类函数
void DeleteMenu(BookList &L,int *n)//菜单类函数,用于
{
BookNode pre;
int number,choose;
cout<<"请输入要删除的书籍ISBN号:";
cin>>number;
pre=FindPrebookByISBN(L,number);//这里的pre是查找到的
if(!pre->next)
{
cout<<"没有找到相对应的书籍。"<<endl;
return ;//如果没有找到要删除的书籍的话,这个函数就可以直接结束了
}
PrintBook(pre->next);
cout<<"确认要删除该书籍吗?"<<endl;
cout<<"1.确认删除 0.取消删除"<<endl;
cout<<"请输入操作项:";
cin>>choose;
if(!choose) break;
DeleteBook(L,pre);//进入真正有删除作用的删除函数,细节下表
cout<<"删除成功!"<<endl;
(*n)--;//删除后书籍-1
}
/*-------------------------------------------------------------------------------------------*/
void DeleteBook(BookList &L,BookNode pre)//传入的是链表L和要删除的结点的前一个结点pre
{
BookNode del=pre->next;//del就是要被删除的结点,是pre的下一个结点
pre->next=del->next;
delete del;
}
5.修改功能(非业务函数)
void ReviseMenu(BookList &L)//传入的是链表L
{
BookNode p;
int number;
cout<<"请输入要修改的书籍的ISBN号:";
cin>>number;
p=FindBookByISBN(L,number);
if(!p)
{
cout<<"没有找到相对应的书籍。"<<endl;
return ;//如果没有找到要修改的,直接结束函数
}
PrintBook(p);//找到以后将书籍信息再打印一遍
int choose;
cout<<"1.修改书籍ISBN号"<<endl<<"2.修改书籍名称"<<endl<<"3.修改书籍作者"<<endl<<"4.修改书籍价格"<<endl<<"其他任意键退出该操作"<<endl;
cout<<"请输入操作项:";
cin>>choose;
switch(choose)
{
case 1: cout<<"请输入修改后的ISBN号:";
cin>>p->BOOK.number;
break;
case 2: cout<<"请输入修改后的书籍名称:";
cin>>p->BOOK.name;
break;
case 3: cout<<"请输入修改后的书籍作者:";
cin>>p->BOOK.author;
break;
case 4: cout<<"请输入修改后的书籍价格:";
cin>>p->BOOK.price;
break;
default: return;
}
}
这里没有写成业务函数,因为要修改结点内容只要找到对应改的结点就好了,个人觉得修改依靠的主体还是查找函数,所以直接是以菜单类函数的形式出现
6.排序功能
void SortBook(BookList &L,int n)
{
int i,j;
BookList p,last,q;
for(i=0;i<n-1;i++)//类似冒泡排序
{
last=L;
p=L->next;
for(j=0;j<n-1-i;j++)
{
if(p->BOOK.price>p->next->BOOK.price)
{
q=p->next;
p->next=q->next;
q->next=p;
last->next=q;
last=last->next;
}
else
{
p=p->next;
last=last->next;
}
}
}
}
实际上对链表的排序我也没有什么太好的头绪,所以就简单的用类似冒泡排序的写法写了一下。
如果使用STL中自带的list的话,有自带的sort()函数可以帮助我们直接完成链表的排序功能。
以上就是该图书管理系统的关键代码了,还有一些基础的函数和main函数没有放上来,如果想要看下其他代码的话,可以私聊找我
三.需要提高及改进的地方
将界面代码和业务逻辑代码分离
Δ 在修改的过程中,老师一直在强调关于这一点的问题,函数之间要减少它们的依赖性。在思考过后,我目前的理解是功能函数要足够纯粹。
也就是一个功能函数,除了实现它想要的功能,不需要去做一些多余的工作。
举个栗子:这个是我修改以前的删除函数
void DeleteBook(BookList &L)
{
BookNode pre;
int number;
cout<<"请输入要删除的书籍ISBN号:";
cin>>number;
pre=FindBookISBN(L,number);
if(!pre->next)
{
cout<<"没有找到相对应的书籍。"<<endl;
return ;
}
PrintBook(pre->next);
cout<<"确认要删除该书籍吗?"<<endl;
cout<<"1.确认删除 0.取消删除"<<endl;
cout<<"请输入操作项:";
int choose;
cin>>choose;
if(choose)
{
BookList del=pre->next;
pre->next=del->next;
delete del;
cout<<"删除成功!"<<endl;
}
}
ლ(´ڡ`ლ) 相比较之下,原来的代码就是上文中删除类函数的合体版本,那为什么我们要把它分成DeleteMenu和DeleteBook两个函数呢?
划个重点:如果没有分成两个函数,在我们想要调用删除这个操作的时候,就必须要进行输入输出的操作,诚然,在这个程序中这么使用确实没有问题,
但是如果换到其他的地方,这个操作函数就必须要进行改写,并不能算是“通用”。
那分成菜单类函数(DeleteMenu)和业务函数(DeleteBook)有什么好处呢?:分成两个函数后,无论我们要在哪里使用它,都不会被它的输入输出条件所限制,
如果要对输入输出进行修改,只需要对菜单类函数进行修改即可,而如果是其他的函数中想要调用业务函数(DeleteBook),就可以随心所欲的使用,因为这个
业务函数就只有单纯的删除这一功能。
再来一个栗子:像STL中的堆栈,队列一样,每一个函数都是实现很纯粹的功能,甚至堆栈中的删除和返回栈顶元素分化成了top和pop两个函数。
优化查找效率
Δ 对于查找效率,目前我也只是有一些自己的思路,但是觉得这个思路有些许的繁琐,但是存在实现的可能。
想法中的数据结构伪代码:
struct Booklist
{
struct Book BOOK;
struct Booklist* next;
struct Booklist* A~Z;
};
其中的A~Z用于存放字典序A到Z的第一本书籍的指针,这样在查找的时候只需要根据书籍的字典序位置,进行查找,效率绝对是比遍历要快的
四.体会
1.“对一个东西做精,就能沉淀到我们的思维当中”,我十分赞同这句话,在对程序修改和思考的过程中,可以体会到自己的不足和缺陷,也可以了解
到更多的知识,这些知识对我们的成长都是很有帮助的。
2.英语要好好学,起码专业的词汇量要多掌握一点,变量名称的定义和函数名称的定义都需要英文词汇的基础,一个好的变量和函数名可以大大提高
程序的可读性,让别人更好理解。而随手取的变量名在较长的程序中会让人看得十分难受。
posted on 2019-03-31 23:07 ballball给个名字吧 阅读(397) 评论(1) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号