

数据切分
数据切分:
就是指通过某种特定的条件,将我们存放在同一个数据库中的数据分散存放到多个数据库(主机)上面,以达到分散单台设备负载的效果。也就是当数据达到几百万的数据时,压力过大选择分服务器分库
两种切分模式:
- 一种是按照不同的表(或者Schema)来切分到不同的数据库(主机)之上,这种切可以称之为数据的垂直(纵向)切分
- 一种是根据表中的数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库(主机)上面,这种切分称之为数据的水平(横向)切分
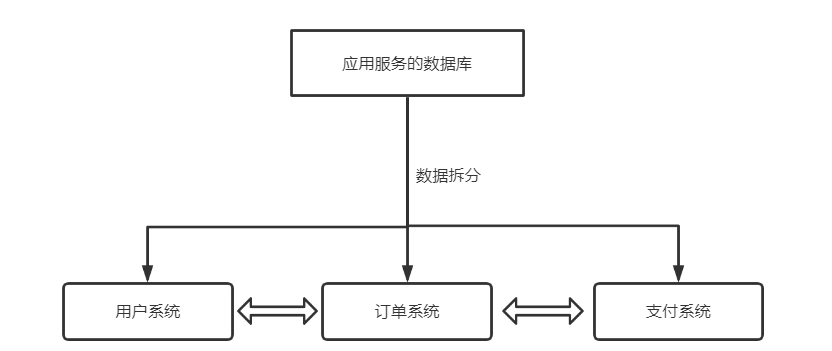
垂直切分:
原有单个服务器上有三个表: A、B、C,将A分到server1主机,B分到server2,C分到server3。达到分担压力的作用
三者之间没有涉及到连表查询等依赖关系,使用时,根据开发人员写得api接口,相互传输数据
拆分要点:
- 分表的前提条件是,分出去的表之间相互没有依赖关系,不需要连表、多表查询,不能join操作
优点:
- 拆分后业务清晰,拆分规则明确
- 系统之间整合或扩展容易
- 数据维护简单
缺点:
- 部分业务表无法 join,只能通过接口方式解决(代码中连接),提高了系统复杂度
- 受每种业务不同的限制存在单库性能瓶颈,不易数据扩展跟性能提高
- 事务处理复杂
- 由于垂直切分是按照业务的分类将表分散到不同的库,所以有些业务表会过于庞大,存在单库读写与存储瓶颈,所以就需要水平拆分来做解决
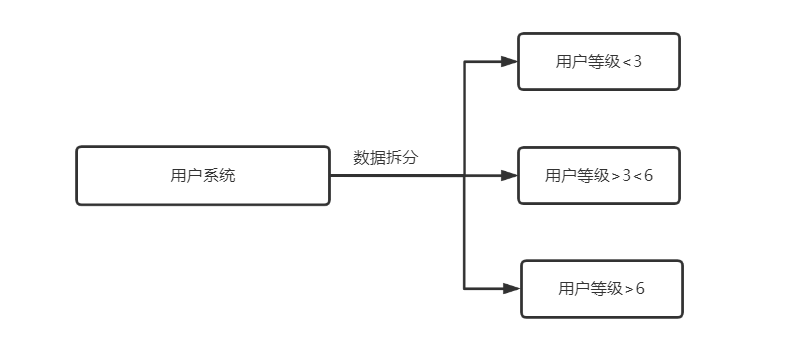
水平拆分:
原有两个表; 用户表、消息表。拆分时可以根据用户的不同等级,比如:<3级的放在server1,>3<6级的放在server2,>6的都放在server3
水平拆分一般都是根据数据的类容、类型来拆分。而每个分出去的数据在数据库中间件上都有一个类似于索引记录,指明该数据在哪个主机哪个库
几种典型的分片规则包括:
- 按照用户ID求模,将数据分散到不同的数据库,具有相同数据用户的数据都被分散到一个库中
- 按照日期,将不同月甚至日的数据分散到不同的库中
- 按照某个特定的字段求摸,或者根据特定范围段分散到不同的库中
优点:
- 拆分规则抽象好,join 操作基本可以数据库做
- 不存在单库大数据,高并发的性能瓶颈
- 应用端改造较少
- 提高了系统的稳定性跟负载能力
缺点:
- 拆分规则难以抽象
- 分片事务一致性难以解决
- 数据多次扩展难度跟维护量极大
- 跨库 join 性能较差
垂直切分和水平切分的共同缺点:
- 引入分布式事务的问题
- 跨节点 Join 的问题
- 跨节点合并排序分页问题
- 多数据源管理问题
数据切分的原则:
- 第一原则:能不切分尽量不要切分
- 第二原则:如果要切分一定要选择合适的切分规则,提前规划好
- 第三原则:数据切分尽量通过数据冗余或表分组(Table Group)来降低跨库 Join 的可能
- 第四原则:由于数据库中间件对数据Join实现的优劣难以把握,而且实现高性能难度极大,业务读取尽量少使用多表Join

 浙公网安备 33010602011771号
浙公网安备 33010602011771号