

MySQL的sql语言-下篇(dcl和sql进阶)
sql语言:
上篇 MySQL的sql语言-上篇
中篇 MySQL的sql语言-中篇
SQL语句执行顺序:
from -->where -->group by -->having -->select -->order by -->limit
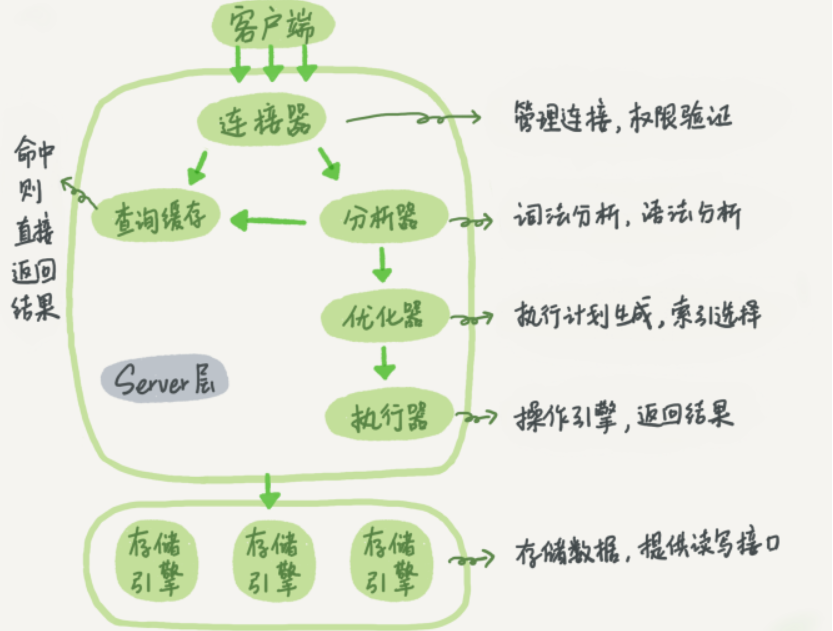
查询执行路径中的组件:
- 查询缓存、解析器(分析器)、优化器、执行引擎、存储引擎
多表查询:
子查询:
在SQL语句嵌套着查询语句,性能较差,基于某语句的查询结果再次进行的查询
子查询示例:
用于比较表达式中:子查询只能是返回单个值
select name,age from students where age>(select avg(age) from students);
用于IN中:子查询的结果要返回一个或多个值
select name,age from students where age in (select age from teachers);
用于EXISTS 和 Not EXISTS
注意点:
- exists()和not exists()的结果返回的是bool值,有结果为真,无结果为假
- 用在where之后,必须有子查询
例:
select * from students s where EXISTS (select * from teachers t where s.teacherid=t.tid);
用于from
select stuid,name,age from students where age > (select avg(age) from students);
#先把子查询的结果,别名为:o,再查询别名“o”表的name,age,条件满足age=22的
select o.name,o.age from (select * from students where stuid<5) o where o.age=22;
用于uptade
update teachers set age=(select avg(age) from students) where tid=4;
联合查询: union
联合查询示例:
将多个表的数据组合在一起显示,重复的数据会自动去重
联合的多个表要字段数量相同,或者从多个表挑出一样的字段数量
联合表的数据类型匹配、字段的排序要对应(尽量相同),如:id=id行
例:
select * from teachers union select stuid,name,age,gender from students;
#把两个表联合显示,默认去重。加all则原样显示
select * from teachers union all select stuid,name,age,gender from students;
交叉连接: cross join
a表字段总数 * b表字段总数
多个表内容横向乘积显示,如:a表10字段,b表20字段,联合显示200字段
注意: 生产场景尽量不要使用,会导致服务器死机,特别是两个表数据很多时
例:
select stuid,s.name 学生姓名,s.age,tid,t.name 老师姓名,t.age from teachers s cross join students t;
内连接: inner join
三种方式:
- 等值连接: 让表之间的字段以“等值”建立连接关系
- 不等值连接
- 自然连接: 去掉重复列的等值连接
例:
显示效果与交叉连接内容一样,但根据条件过滤显示
写法一:
select * from students s inner join teachers t on s.teacherid=t.tid where t.age<=50;
写法二:
#将inner join替换成“,”,on替换成where
select * from students s , teachers t where s.teacherid=t.tid;
外连接:
根据条件的交集,显示内容,有表的前后顺序
三种方式:
- 左外连接: left join
- 右外连接: right join
- 自连接: 本表和本表进行连接查询,基于左、右连接
左连接:
可以将left outer简写成:left
select s.stuid,s.name,s.age,s.teacherid,t.tid,t.name,t.age from students s left outer join teachers t on s.teacherid=t.tid;
右连接:
右连接写为:right outer。可简写
select s.stuid,s.name,s.age,teacherid,tid,t.name,t.age from students s right join teachers t on teacherid=t.tid;
完全外连接:
将两个表的内容完全连接,通过union去重连接。(其他数据库支持full outer join,但mysql不持之完全外连接)
三段为一个整体,全部都是一个命令
select s.stuid,s.name,s.age,teacherid,tid,t.name,t.age from students s left join teachers t on s.teacherid=t.tid
union
select s.stuid,s.name,s.age,teacherid,tid,t.name,t.age from students s right join teachers t on teacherid=t.tid;
自连接:
表emp有id、name、ld_id三个字段,现要求查询一个表内id=ld_id,就要用到自连接(自己表连接自己表)
注意:
- 通过内连接不能实现,内连接会把空值去除掉
- 所以只能使用外连接实现两表联合
#通过外连接,把一个表设别名两次(一个别名对应一个虚拟表),再把两个虚拟表的内容合并,再条件运算
select e.name,l.name from emp e left join emp l on e.leaderid=l.id;
#使用ifnull函数设置默认值
select e.name 员工姓名,ifnull(l.name,'无上级') 领导 from emp e left join emp l on e.leaderid=l.id;
三表查询:
一般不会有超出3表以上的查询,4-5表的内容都是数据库的设计有问题了
示例:
select st.stuid,st.name,co.course,sc.score from students st inner join scores sc on st.classid=sc.courseid inner join courses co on sc.courseid=co.courseid;
VIEW视图:
视图是一个虚拟表,其内容保存的是select查询语句的结果,功能相当于shell的alisa
支持增删改成等操作,但不建议使用
视图只在: *.frm文件
例:
create view 视图名 as select语句;
function函数:
存放表: mysql.proc
函数分为: 系统内置、自定义
流程控制
存储过程和函数中可以使用流程控制来控制语句的执行
| if | 用来进行条件判断。根据是否满足条件,执行不同语句 |
| case | 用来进行条件判断,可实现比IF语句更复杂的条件判断 |
| loop | 重复执行特定的语句,实现一个简单的循环 |
| leave | 用于跳出循环控制,相当于SHELL中break |
| lterate | 跳出本次循环,然后直接进入下一次循环,相当于SHELL中continue |
| repeat | 有条件控制的循环语句。当满足特定条件时,就会跳出循环语句 |
| while | 有条件控制的循环语句 |
自带的系统函数:
| avg() | 求平均值 |
| max() | 最大值 |
| min() | 最小值 |
| sum() | 字段的所有数字相加的总和 |
| count(字段) | 字段的所有行的总数,飞空的数量 |
| concat() | 字符连接 |
| ifnull(id,'123') | 字段为空时,给定默认值 |
| row_count() | 显示上一个命令执行成功的总数记录 |
| password() | 加密函数 |
| current_time() | 当前时间戳 |
| now() | 当前时间戳,同上 |
| current_user() | 当会话的用户 |
自定义函数:
create function 函数名(参数 类型,..)
returns 返回值的数据类型
begin
内容
return 返回内容
end 结束符
函数相关命令:
show function status; 查看自定义函数
select * from mysql.proc\G; proc表存放自定义函数
show create function 函数; 查看创建过程
drop function function_name 删除
select 函数(); 调用函数
例:
mysql会以“;”做结束符,所以有分号时会理解成完成,所以要设置别的结束符
#创建返回"hello world"字符串的函数
create function qq() returns varchar(20) return "hello word";
#统计学生总数的函数
delimiter // #设置结束符
create function dl(id int unsigned) returns varchar(20)
begin
delete from students where stuid=id;
return (select count(*) from students);
end //
delimiter ; #恢复结束符
变量:
show variables; 查看系统当前所有变量
系统变量:
MySQL数据库中内置的变量
@@v变量名 #引用变量
set global 变量=参数;
用户自定义变量:
普通变量:
在当前会话中有效,
@变量名 #引用变量
set @aa=select * from students;
局部变量:
在函数、存储过程内才有效,需要用declare声明,之后直接使用: var_name
说明:
- 局部变量的作用范围是在BEGIN...END程序中,而且定义局部变量语句必须在BEGIN...END的第一行定义
定义语法:
declare 变量1[,变量2..] 变量类型 [deafult 默认值]
例:
delimiter ;;
create function zh(x int unsigned,y int unsigned)
returns int
begin
declare a,b smallint unsigned;
set a=x,b=y;
return a+b;
end ;;
delimiter ;
赋值变量:
只存活当前会话
set 变量名='aaa';
select count(*) from students into 变量名; #只能是单个值
存储过程
多表SQL的语句的集合,可以独立执行,存储过程保存在mysql.proc表中
一般不推荐使用在生产场景,可用于测试环境,方便执行命令
存储过程优势:
存储过程把经常使用的SQL语句或业务逻辑封装起来,预编译保存在数据库中,当需要时从数据库中直接调用,省去了编译的过程,提高了运行速度,同时降低网络数据传输量
存储过程与自定义函数的区别
- 存储过程实现的过程要复杂一些,而函数的针对性较强
- 存储过程可以有多个返回值,而自定义函数只有一个返回值
- 存储过程一般可独立执行,而函数往往是作为其他SQL语句的一部分来使用
存储过程相关命令:
show procedure status; 查看系统中所有的存储过程
show create procedure status\G; 创建过程
drop procedure 过程名称;
call 过程名称; 调用存储过程
创建语法:
使用in、out、inout 指定参数的传输
create procedure 过程名([参数])
begin
sql命令;
end
例:
#获取当前时间
delimiter //
CREATE PROCEDURE showTime()
BEGIN
SELECT now();
END //
delimiter ;
#手动传参:in
delimiter //
CREATE PROCEDURE selectById(IN id SMALLINT UNSIGNED)
BEGIN
SELECT * FROM students WHERE stuid = id;
END//
delimiter ;
call selectById(2);
#做循环,传参100,实现0累加到100的总数,普通变量在使用后还能存在,不会清空,直到会话关闭
delimiter //
CREATE PROCEDURE dorepeat(n INT)
BEGIN
SET @i = 0;
SET @sum = 0;
REPEAT SET @sum = @sum+@i;
SET @i = @i + 1;
UNTIL @i > n END REPEAT;
END//
delimiter ;
CALL dorepeat(100);
SELECT @sum;
#out输出存储过程内部的带有结果的变量,在赋值给普通变量@line,最后查询变量@line
delimiter //
CREATE PROCEDURE deleteById(IN id SMALLINT UNSIGNED, OUT num SMALLINT UNSIGNED)
BEGIN
DELETE FROM students WHERE stuid >= id;
SELECT row_count() into num;
END//
delimiter ;
call deleteById(2,@Line);
SELECT @Line;
trigger触发器:
触发器的执行不是由程序调用,也不是由手工启动,而是由事件来触发、激活从而实现执行。相当与if语句定义的内容,满足时做哪些操作
不建议生产环境使用
触发器相关命令:
show triggers\G;
DROP TRIGGER trigger_name;
语法:
create [definer={ 用户@主机| 当前用户}] trigger 触发器名
触发时间 触发的事件
on 监听的表 [for each row]
触发事件进行的操作
说明:
definer: 执行的人
触发时间:
before 事件之前触发,事件触发时,不再执行引起事件触发的sql,而是执行定义的内容
after 事件之后触发
触发事件: 触发的事件类型
insert、update、delete
for each row: 循环次数,事件触发后的操作做多少次,相当于while的条件
event事件:
类似于shell中的计划任务,mysql的event事件也支持一次性,周期性。它由一个特定的线程管理,也就是“事件调度器”
工作机制与触发器类似,都是在某些事件发生时才启动
事件调取器可以精确到每秒钟执行一个任务,shell只能分钟
存放表: mysql.event
event服务:
select @@event_scheduler; 查看event服务状态
show processlist; 查看守护进程是否启动
事件调度器: event_scheduler
负责调用事件,默认关闭,这个调度器不断地监视一个事件是否要调用, 要创建事件,必须打开调度器
启动后以守护进程方式运行
启用方法:
#临时启动
set global event_scheduler=1;
#永久启动
vim /etc/my.cnf.d/mariadb-server.cnf
[server]
event_scheduler=1
使用事件:
事件有两个主要部分:
- 事件调度(event_schedule),表示事件何时启动以及按什么频率启动
- 事件动作,普通sql是一条执行,begin..end语句可以执行多条
说明:
- 事件创建以后是立即启动的,也就是活动状态。但是可以手动指定状态,活动则是事件触发就执行,停止状态不会动
语法:
create [definer= 用户] event [if not exists] 事件名称
on SCHEDULE 调度时间 | schedule 调度时间 #大小周期小写临时
[on completion not preserve] #执行后删除,有not为删除(默认)
[rename to new_event_name]
[enable | disable | disable ON slave]
[commont 'comment']
do 执行的sql
schedule: 调度的时间方法
at timestamp [+ 时间间隔 间隔] | every 间隔
[starts timestamp [+ 间隔 间隔}]
[ends 时间戳 [+ 间隔 间隔]]
时间间隔:
quantity { 时间 }
时间:
year、month、week、day、hour、mintue、second
quarter 一刻钟
year_month、day_hour、day_mintue、day_second、hour_mintue、hour_second、mintue_second
修改event事件:
ALTER [DEFINER = { user | CURRENT_USER }] EVENT event_name
[ON SCHEDULE schedule]
[ON COMPLETION [NOT] PRESERVE]
[RENAME TO new_event_name]
[ENABLE | DISABLE | DISABLE ON SLAVE]
[COMMENT 'comment']
[DO event_body]
案例:
创建一次临时的事件
create event event_now
on schedule at now()
do insert into events_list values('event_now', now());
创建周期性事件,每1s一次
CREATE EVENT event_every_second
ON SCHEDULE EVERY 1 SECOND
DO INSERT INTO events_list VALUES('event_now', now());
定时调用存储过程
delimiter //
create procedure sp_insert()
begin
insert into events_list values('event_now', now());
end//
delimiter ;
CREATE DEFINER=`root`@`localhost` EVENT event_test
ON SCHEDULE EVERY 10 SECOND
STARTS '2019-12-02 22:55:00' ON COMPLETION PRESERVE ENABLE DO call sp_insert();
修改事件
ALTER DEFINER=`root`@`localhost EVENT event_test
ON SCHEDULE EVERY 30 SECOND
ON COMPLETION PRESERVE ENABLE
DO call sp_insert();
禁用事件
alter event testdb.event_test disable;
MySQL用户管理:
元数据数据库:mysql
系统授权表:
- db, host, user,columns_priv, tables_priv, procs_priv, proxies_priv
用户帐号:
'用户'@'主机'
主机是客户端登录的主机,不是服务端的地址
主机支持:
- @'hj.com'
- IP、Network
- %、_ 通配符,任意、单个
用户操作:
#新创建用户的默认权限:usage
CREATE USER 'user'@'host' [IDENTIFIED BY 'password'];
#重命名
RENAME USER old_user_name TO new_user_name;
#删除用户
DROP USER 'USERNAME'@'HOST‘
修改密码:
新版mysql中用户密码可以保存在mysql.user表的authentication_string字段中
如果mysql.user表的authentication_string和password字段都保存密码,authentication_string优先生效
mysql的加密机制并没有加盐。所以同一密码的格式一样,要手动加盐
方法:
#10.4以下可只改password字段,数据库重启才生效
set password FOR 'user'@'host' = password('123456');
#10.4版本以上直接修改,立即生效
set password FOR 'user'@'host' = password('123456');
alter user root@'%' identified by '123456';
#刷新权限
flush privileges;
破解root密码:
简单粗暴,直接删目录,但数据丢失,启动时自动生成
yum安装的是: /var/lib/mysql/*
修改配置文件:
vim /etc/my.cnf.d/mariadb-server.cnf
[mysqld]
skip-grant-tables
skip-networking
systemctl restart mariadb
mysql
-->alter user root@'%' identified by '123456';
说明:
此时修改密码不支持set password变量修改,只可update或者alter user修改
skip-grant-tables是跳过权限表,但远程主机也会跳过密码
skip-networking是禁止网络连接,相当于只能socket连接,两个参数一起使用,避免了远程连接
权限管理和DCL语句:
权限类别:
- 管理类
- 程序类
- 数据库级别
- 表级别
- 字段级别
管理类:
create temporary tables
create user
file
super
show databases;
reload
shutdown
replication slave 数据库复制权限
replication client
lock tables
process
程序类: 针对function、procedure、trigger
create
table
drop
excute
库、表级别: 针对database、table
alter
create
create view
drop index
show view
with grant option 将自己获取的权限转给其他用户
数据操作:
select
insert
update
delete
字段级别:
select
update
insert
所有权限:
all
授权: grant
grant 权限类型1,.. on [对象类型] 对象 to 用户@主机 [identified by 密码] [with grant option];
权限类型:
#前面介绍的所有权限类型都是
all
insert、update、delete等等
PRIVILEGES
对象类型:
表、函数、存储过程
对象:
*.* 所有库
name.* name库的所有表
name.qwe name库的qwe表
table 当先所在库的表
name.函数、存储过程、触发器
权限转移: grant option
max_queries_per_hour count 查询次数/h
max_update_per_hour count 更新次数/h
max_connections_per_hour count 连接次数/h
max_user_connections count 用户连接次数/h
例:
grant all on *.* to test@'127.0.0.1' identified by '123456' with grant option;
grant select(字段),insert(字段1,字段2) on test.test to test@1.1.1.%;
create user hj@'%' identified by '123456';
grant all on *.* to hj@'%' with grant option;
show grants for test@127.0.0.1; 查看权限
show grants for current_user(); 查看当前用户权限
取消授权:
revoke delete on testdb.* from 'testuser'@‘172.16.0.%’;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号