Ubuntu18.04 Scala Hadoop Spark安装
一.安装Scala
1.将Scala 安装包复制到 /usr/local
mv scala-2.13.7.tgz /usr/local/
2.解压压缩包并修改名称
tar -xvf scala-2.13.7.tgz # 修改名称 mv scala-2.13.7/ scala
3.配置环境变量
vi /etc/profile # 在最后添加下面内容 export SCALA_HOME=/usr/local/scala export PATH=$SCALA_HOME/bin:$PATH # 生效 source /etc/profile
4.查看scala
scala -version

二.安装Hadoop
1.配置ssh无密码登录
ssh-keygen -t rsa # 一直回车
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
测试是否成功
ssh localhost
2. 解压hadoop并重命名
tar -xvf hadoop-3.3.1.tar.gz mv hadoop-3.3.1/ hadoop
3.配置环境变量
vi /etc/profile # 在最后添加下面代码 export HADOOP_HOME=/usr/local/hadoop export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH source /etc/profile
4.查看hadoop
hadoop version

修改权限
cd /usr/local
sudo chown -R suphowe:suphowe hadoop
5.hadoop伪分布式配置
5.1修改core-site.xml文件
vi /usr/local/hadoop/etc/hadoop/core-site.xml
添加
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
5.2 修改hdfs-site.xml
vi /usr/local/hadoop/etc/hadoop/hdfs-site.xml
添加
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
5.3 修改hadoop-env.sh
vi /usr/local/hadoop/etc/hadoop/hadoop-env.sh
添加JAVA_HOME
export JAVA_HOME=/usr/lib/jdk/jdk1.8.0_311
5.4执行NameNode格式化
hdfs namenode -format
运行
/usr/local/hadoop/sbin/start-dfs.sh
5.5 启动失败处理
but there is no HDFS_NAMENODE_USER defined. Aborting operation.
对于start-dfs.sh和stop-dfs.sh文件,添加
#!/usr/bin/env bash HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
对于start-yarn.sh和stop-yarn.sh文件,添加
#!/usr/bin/env bash YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
重新启动

5.6 测试
jps
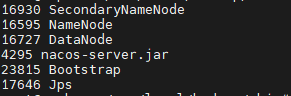
5.7浏览器查看
localhost:50070
三.配置YARN
1.修改配置文件mapred-site.xml
vi /usr/local/etc/hadoop/mapred-site.xml
添加
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2.修改配置文件yarn-site.xml
vi /usr/local/etc/hadoop/yarn-site.xml
添加
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
3.编写启动脚本start-hadoop.sh
vi /usr/local/hadoop/sbin/start-hadoop.sh
添加
#!/bin/bash # 启动hadoop start-dfs.sh # 启动yarn start-yarn.sh # 启动历史服务器,以便在Web中查看任务运行情况 mr-jobhistory-daemon.sh start historyserver
4.编写停止脚本stop-hadoop.sh
vi /usr/local/hadoop/sbin/stop-hadoop.sh
添加
#!/bin/bash # 停止历史服务器 mr-jobhistory-daemon.sh stop historyserver # 停止yarn stop-yarn.sh # 停止hadoop stop-dfs.sh
5.通过 Web 界面查看任务的运行情况
localhost:8088
四.安装Spark
待续

 浙公网安备 33010602011771号
浙公网安备 33010602011771号