prometheus+grafana+alertmanager 监控系统
prometheus+grafana+alertmanager 监控系统
1. 创建命名空间以及SA账号
1.1 创建命名空间
kubectl create ns monitor-sa
2. 创建sa账号
kubectl create serviceaccount monitor -n monitor-sa
3. 把sa账号monitor通过clusterrolebing绑定到clusterrole上
kubectl create clusterrolebinding monitor-clusterrolebinding -n monitor-sa --clusterrole=cluster-admin --serviceaccount=monitor-sa:monitor
如果报错请执行
kubectl create clusterrolebinding monitor-clusterrolebinding-1 -n monitor-sa --clusterrole=cluster-admin --user=system:serviceaccount:monitor:monitor-sa
2.执行node节点脚本 监控node节点
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: monitor-sa
labels:
name: node-exporter
spec:
selector:
matchLabels:
name: node-exporter
template:
metadata:
labels:
name: node-exporter
spec:
hostPID: true
hostIPC: true
hostNetwork: true
containers:
- name: node-exporter
image: prom/node-exporter:v0.16.0
ports:
- containerPort: 9100
resources:
requests:
cpu: 0.15
securityContext:
privileged: true
args:
- --path.procfs
- /host/proc
- --path.sysfs
- /host/sys
- --collector.filesystem.ignored-mount-points
- '"^/(sys|proc|dev|host|etc)($|/)"'
volumeMounts:
- name: dev
mountPath: /host/dev
- name: proc
mountPath: /host/proc
- name: sys
mountPath: /host/sys
- name: rootfs
mountPath: /rootfs
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
- key: "ceph"
operator: "Exists"
effect: "NoSchedule"
volumes:
- name: proc
hostPath:
path: /proc
- name: dev
hostPath:
path: /dev
- name: sys
hostPath:
path: /sys
- name: rootfs
hostPath:
path: /
3.安装prometheus
3.1 在k8s-node-04服务器执行
mkdir -p /data/alertmanager
mkdir -p /var/lib/grafana
chmod 777 -R /data/
chmod 777 -R /var/lib/grafana
3.2 安装prometheus
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-server
namespace: monitor-sa
labels:
app: prometheus
spec:
replicas: 1
selector:
matchLabels:
app: prometheus
component: server
#matchExpressions:
#- {key: app, operator: In, values: [prometheus]}
#- {key: component, operator: In, values: [server]}
template:
metadata:
labels:
app: prometheus
component: server
annotations:
prometheus.io/scrape: 'false'
spec:
nodeName: k8s-node-04
serviceAccountName: monitor
containers:
- name: prometheus
image: prom/prometheus:v2.2.1
imagePullPolicy: IfNotPresent
command:
- "/bin/prometheus"
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus"
- "--storage.tsdb.retention=24h"
- "--web.enable-lifecycle"
ports:
- containerPort: 9090
protocol: TCP
volumeMounts:
- mountPath: /etc/prometheus
name: prometheus-config
- mountPath: /prometheus/
name: prometheus-storage-volume
- name: k8s-certs
mountPath: /var/run/secrets/kubernetes.io/k8s-certs/etcd/
- name: alertmanager
image: prom/alertmanager:v0.14.0
imagePullPolicy: IfNotPresent
args:
- "--config.file=/etc/alertmanager/alertmanager.yml"
- "--log.level=debug"
ports:
- containerPort: 9093
protocol: TCP
name: alertmanager
volumeMounts:
- name: alertmanager-config
mountPath: /etc/alertmanager
- name: alertmanager-template-config
mountPath: /etc/alertmanager-tmpl
- name: alertmanager-storage
mountPath: /alertmanager
- name: localtime
mountPath: /etc/localtime
volumes:
- name: prometheus-config
configMap:
name: prometheus-config
- name: prometheus-storage-volume
hostPath:
path: /data
type: Directory
- name: alertmanager-config
configMap:
name: alertmanager
- name: alertmanager-template-config
configMap:
name: alertmanager-template
- name: alertmanager-storage
hostPath:
path: /data/alertmanager
type: DirectoryOrCreate
- name: localtime
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
3.3 安装prometheus svc 地址
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: monitor-sa
labels:
app: prometheus
spec:
type: NodePort
ports:
- port: 9090
targetPort: 9090
protocol: TCP
selector:
app: prometheus
component: server
3.4 安装prometheus 设置规则
kind: ConfigMap
apiVersion: v1
metadata:
labels:
app: prometheus
name: prometheus-config
namespace: monitor-sa
data:
prometheus.yml: |
rule_files:
- /etc/prometheus/rules.yml
alerting:
alertmanagers:
- static_configs:
- targets: ["localhost:9093"]
global:
scrape_interval: 15s
scrape_timeout: 10s
evaluation_interval: 1m
scrape_configs:
- job_name: 'kubernetes-node'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'kubernetes-node-cadvisor'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
- job_name: 'kubernetes-apiserver'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scrape
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_pod_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- action: replace
source_labels:
- __meta_kubernetes_pod_name
target_label: kubernetes_pod_name
- job_name: 'kubernetes-schedule'
scrape_interval: 5s
static_configs:
- targets: ['10.5.11.115:10251']
- job_name: 'kubernetes-controller-manager'
scrape_interval: 5s
static_configs:
- targets: ['10.5.11.115:10252']
- job_name: 'kubernetes-kube-proxy'
scrape_interval: 5s
static_configs:
- targets: ['10.5.11.115:10249','10.5.11.175:10249','10.5.11.176:10249','10.5.11.246:10249','10.5.11.13:10249','10.20.201.40:10249','10.20.201.41:10249']
- job_name: 'kubernetes-etcd'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/ca.crt
cert_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.crt
key_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.key
scrape_interval: 5s
static_configs:
- targets: ['10.5.11.115:2379']
rules.yml: |
groups:
- name: example
rules:
- alert: kube-proxy打开句柄数>600
expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 600
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"
value: "{{ $value }}"
- alert: kube-proxy打开句柄数>1000
expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 1000
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"
value: "{{ $value }}"
- alert: kubernetes-schedule打开句柄数>600
expr: process_open_fds{job=~"kubernetes-schedule"} > 600
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"
value: "{{ $value }}"
- alert: kubernetes-schedule打开句柄数>1000
expr: process_open_fds{job=~"kubernetes-schedule"} > 1000
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"
value: "{{ $value }}"
- alert: kubernetes-controller-manager打开句柄数>600
expr: process_open_fds{job=~"kubernetes-controller-manager"} > 600
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"
value: "{{ $value }}"
- alert: kubernetes-controller-manager打开句柄数>1000
expr: process_open_fds{job=~"kubernetes-controller-manager"} > 1000
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"
value: "{{ $value }}"
- alert: kubernetes-apiserver打开句柄数>600
expr: process_open_fds{job=~"kubernetes-apiserver"} > 600
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"
value: "{{ $value }}"
- alert: kubernetes-apiserver打开句柄数>1000
expr: process_open_fds{job=~"kubernetes-apiserver"} > 1000
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"
value: "{{ $value }}"
- alert: kubernetes-etcd打开句柄数>600
expr: process_open_fds{job=~"kubernetes-etcd"} > 600
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"
value: "{{ $value }}"
- alert: kubernetes-etcd打开句柄数>1000
expr: process_open_fds{job=~"kubernetes-etcd"} > 1000
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"
value: "{{ $value }}"
- alert: coredns
expr: process_open_fds{k8s_app=~"kube-dns"} > 600
for: 2s
labels:
severity: warnning
annotations:
description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过600"
value: "{{ $value }}"
- alert: coredns
expr: process_open_fds{k8s_app=~"kube-dns"} > 1000
for: 2s
labels:
severity: critical
annotations:
description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过1000"
value: "{{ $value }}"
- alert: 使用虚拟内存超过2G
expr: process_virtual_memory_bytes /1024 /1024 /1024 > 2
for: 2s
labels:
severity: warnning
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"
value: "{{ $value }}"
- alert: HttpRequestsAvg
expr: sum(rate(rest_client_requests_total{job=~"kubernetes-kube-proxy|kubernetes-kubelet|kubernetes-schedule|kubernetes-control-manager|kubernetes-apiservers"}[1m])) > 1000
for: 2s
labels:
team: admin
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): TPS超过1000"
value: "{{ $value }}"
threshold: "1000"
- alert: Pod_restarts
expr: sum (increase (kube_pod_container_status_restarts_total{}[5m])) by (namespace,pod,container,instance) > 3
for: 2s
labels:
severity: warnning
annotations:
description: "在{{$labels.namespace}}名称空间下发现{{$labels.pod}}这个pod下的容器{{$labels.container}}被重启"
value: "{{ $value }}"
threshold: "0"
- alert: 容器cpu使用率过高
expr: sum(increase(container_cpu_cfs_throttled_periods_total{container!="", }[5m])) by (container, pod, namespace) / sum(increase(container_cpu_cfs_periods_total{}[5m])) by (container, pod, namespace) * 100 > 80
for : 5m
labels:
severity: warnning
annotations:
description: "在{{$labels.namespace}}命名空间 {{$labels.pod}}这个pod的CPU使用率超过限制大小的 80%,请适当调整, 当前值为 {{ $value }} "
value: "{{ $value }}"
- alert: 容器内存使用率过高
expr: sum(container_memory_working_set_bytes{pod!=""}) by (pod,namespace,container) / sum(kube_pod_container_resource_limits_memory_bytes>0) by (pod,namespace,container) * 100 > 80
for : 5m
labels:
severity: warnning
annotations:
description: "在{{$labels.namespace}}命名空间 {{$labels.pod}}这个pod的内存使用率超过限制大小的 80%,请适当调整, 当前值为 {{ $value }} "
value: "{{ $value }}"
- alert: 容器OOMKilled
expr: (kube_pod_container_status_restarts_total - kube_pod_container_status_restarts_total offset 10m >= 1) and ignoring (reason) min_over_time(kube_pod_container_status_last_terminated_reason{reason="OOMKilled"}[10m]) == 1
for : 1m
labels:
severity: warnning
annotations:
description: Container {{ $labels.container }} in pod {{ $labels.namespace }}/{{ $labels.pod }} has been OOMKilled {{ $value }} times in the last 10 minutes.
- alert: Pod_waiting
expr: kube_pod_container_status_waiting_reason == 1
for: 2s
labels:
team: admin
annotations:
description: "命名空间{{$labels.namespace}}:发现{{$labels.pod}}下的{{$labels.container}}启动异常等待中"
value: "{{ $value }}"
threshold: "1"
# - alert: Pod_terminated
# expr: kube_pod_container_status_terminated_reason{namespace=~"kube-system|default|monitor-sa"} == 1
# for: 2s
# labels:
# team: admin
# annotations:
# description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}被删除"
# value: "{{ $value }}"
# threshold: "1"
- alert: Etcd_leader
expr: etcd_server_has_leader{job="kubernetes-etcd"} == 0
for: 2s
labels:
team: admin
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 当前没有leader"
value: "{{ $value }}"
threshold: "0"
- alert: Etcd_leader_changes
expr: rate(etcd_server_leader_changes_seen_total{job="kubernetes-etcd"}[1m]) > 0
for: 2s
labels:
team: admin
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 当前leader已发生改变"
value: "{{ $value }}"
threshold: "0"
- alert: Etcd_failed
expr: rate(etcd_server_proposals_failed_total{job="kubernetes-etcd"}[1m]) > 0
for: 2s
labels:
team: admin
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 服务失败"
value: "{{ $value }}"
threshold: "0"
- alert: Etcd_db_total_size
expr: etcd_debugging_mvcc_db_total_size_in_bytes{job="kubernetes-etcd"} > 10000000000
for: 2s
labels:
team: admin
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}):db空间超过10G"
value: "{{ $value }}"
threshold: "10G"
- alert: Endpoint_ready
expr: kube_endpoint_address_not_ready{namespace=~"kube-system|default"} == 1
for: 2s
labels:
team: admin
annotations:
description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.endpoint}}不可用"
value: "{{ $value }}"
threshold: "1"
- name: 物理节点状态-监控告警
rules:
- alert: 物理节点cpu使用率
expr: 100-avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)*100 > 60
for: 2s
labels:
severity: ccritical
annotations:
summary: "{{ $labels.instance }}cpu使用率过高"
description: "{{ $labels.instance }}的cpu使用率超过60%,当前使用率[{{ $value }}],需要排查处理"
- alert: 物理节点内存使用率
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 80
for: 2s
labels:
severity: critical
annotations:
summary: "{{ $labels.instance }}内存使用率过高"
description: "{{ $labels.instance }}的内存使用率超过80%,当前使用率[{{ $value }}],需要排查处理"
- alert: InstanceDown
expr: up == 0
for: 2s
labels:
severity: critical
annotations:
summary: "{{ $labels.instance }}: 服务器宕机"
description: "{{ $labels.instance }}: 服务器延时超过2分钟"
- alert: 物理节点磁盘的IO性能
expr: 100-(avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) < 60
for: 2s
labels:
severity: critical
annotations:
summary: "{{$labels.mountpoint}} 流入磁盘IO使用率过高!"
description: "{{$labels.mountpoint }} 流入磁盘IO大于60%(目前使用:{{$value}})"
- alert: 入网流量带宽
expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400
for: 2s
labels:
severity: critical
annotations:
summary: "{{$labels.instance }} 流入网络带宽过高!"
description: "{{$labels.instance }}流入网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}"
- alert: 出网流量带宽
expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400
for: 2s
labels:
severity: critical
annotations:
summary: "{{$labels.instance }} 流出网络带宽过高!"
description: "{{$labels.instance }}流出网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}"
- alert: TCP会话
expr: node_netstat_Tcp_CurrEstab > 1000
for: 2s
labels:
severity: critical
annotations:
summary: "{{$labels.mountpoint}} TCP_ESTABLISHED过高!"
description: "{{$labels.mountpoint }} TCP_ESTABLISHED大于1000%(目前使用:{{$value}}%)"
- alert: 磁盘容量
expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 80
for: 2s
labels:
severity: critical
annotations:
summary: "{{$labels.mountpoint}} 磁盘分区使用率过高!"
description: "{{$labels.mountpoint }} 磁盘分区使用大于80%(目前使用:{{$value}}%)"
4.安装kube-state-metrics组件
介绍
kube-state-metrics是什么?
kube-state-metrics通过监听API Server生成有关资源对象的状态指标,比如Deployment、Node、Pod,需要注意的是kube-state-metrics只是简单的提供一个metrics数据,并不会存储这些指标数据,所以我们可以使用Prometheus来抓取这些数据然后存储,主要关注的是业务相关的一些元数据,比如Deployment、Pod、副本状态等;调度了多少个replicas?现在可用的有几个?多少个Pod是running/stopped/terminated状态?Pod重启了多少次?我有多少job在运行中。
4.1 创建sa,并对sa授权
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: kube-state-metrics
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: kube-state-metrics
rules:
- apiGroups: [""]
resources: ["nodes", "pods", "services", "resourcequotas", "replicationcontrollers", "limitranges", "persistentvolumeclaims", "persistentvolumes", "namespaces", "endpoints"]
verbs: ["list", "watch"]
- apiGroups: ["extensions"]
resources: ["daemonsets", "deployments", "replicasets"]
verbs: ["list", "watch"]
- apiGroups: ["apps"]
resources: ["statefulsets"]
verbs: ["list", "watch"]
- apiGroups: ["batch"]
resources: ["cronjobs", "jobs"]
verbs: ["list", "watch"]
- apiGroups: ["autoscaling"]
resources: ["horizontalpodautoscalers"]
verbs: ["list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kube-state-metrics
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-state-metrics
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: kube-system
4.2 安装kube-state-metrics组件
apiVersion: apps/v1
kind: Deployment
metadata:
name: kube-state-metrics
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
app: kube-state-metrics
template:
metadata:
labels:
app: kube-state-metrics
spec:
serviceAccountName: kube-state-metrics
containers:
- name: kube-state-metrics
image: quay.io/coreos/kube-state-metrics:v1.9.0
ports:
- containerPort: 8080
4.3 将端口映射出来
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/scrape: 'true'
name: kube-state-metrics
namespace: kube-system
labels:
app: kube-state-metrics
spec:
ports:
- name: kube-state-metrics
port: 8080
protocol: TCP
selector:
app: kube-state-metrics
导入ID 6417 315
5.安装 grafana
apiVersion: apps/v1
kind: Deployment
metadata:
name: monitoring-grafana
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
task: monitoring
k8s-app: grafana
template:
metadata:
labels:
task: monitoring
k8s-app: grafana
spec:
nodeName: k8s-node-04
containers:
- name: grafana
image: grafana/grafana:8.4.5
ports:
- containerPort: 3000
protocol: TCP
volumeMounts:
- mountPath: /etc/ssl/certs
name: ca-certificates
readOnly: true
- mountPath: /var
name: grafana-storage
- mountPath: /var/lib/grafana/
name: lib
env:
- name: INFLUXDB_HOST
value: monitoring-influxdb
- name: GF_SERVER_HTTP_PORT
value: "3000"
# The following env variables are required to make Grafana accessible via
# the kubernetes api-server proxy. On production clusters, we recommend
# removing these env variables, setup auth for grafana, and expose the grafana
# service using a LoadBalancer or a public IP.
- name: GF_AUTH_BASIC_ENABLED
value: "false"
- name: GF_AUTH_ANONYMOUS_ENABLED
value: "true"
- name: GF_AUTH_ANONYMOUS_ORG_ROLE
value: Admin
- name: GF_SERVER_ROOT_URL
# If you're only using the API Server proxy, set this value instead:
# value: /api/v1/namespaces/kube-system/services/monitoring-grafana/proxy
value: /
volumes:
- name: ca-certificates
hostPath:
path: /etc/ssl/certs
- name: grafana-storage
emptyDir: {}
- name: lib
hostPath:
path: /var/lib/grafana/
type: DirectoryOrCreate
---
apiVersion: v1
kind: Service
metadata:
labels:
# For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons)
# If you are NOT using this as an addon, you should comment out this line.
kubernetes.io/cluster-service: 'true'
kubernetes.io/name: monitoring-grafana
name: monitoring-grafana
namespace: kube-system
spec:
# In a production setup, we recommend accessing Grafana through an external Loadbalancer
# or through a public IP.
# type: LoadBalancer
# You could also use NodePort to expose the service at a randomly-generated port
# type: NodePort
ports:
- port: 80
targetPort: 3000
selector:
k8s-app: grafana
type: NodePort
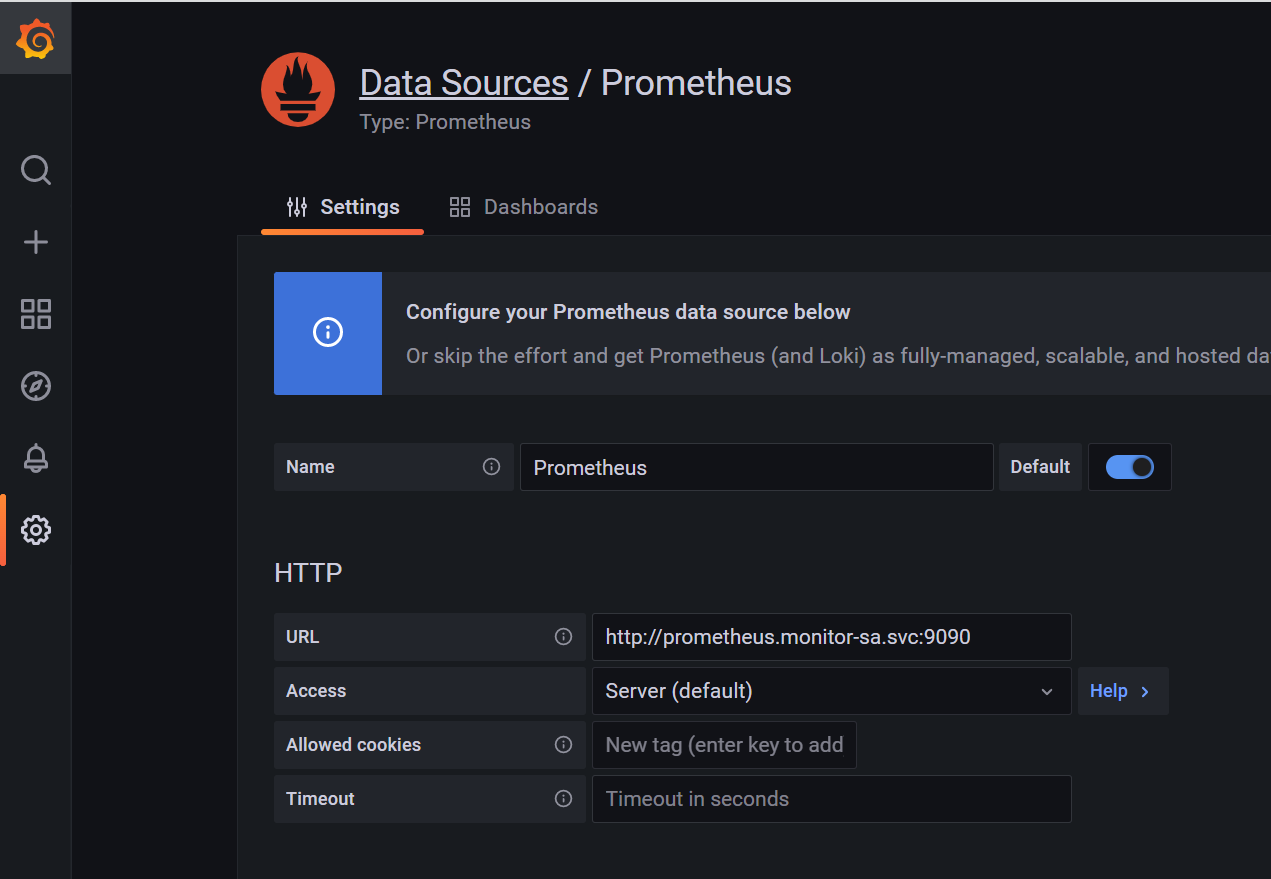
5.1 对接prometheus
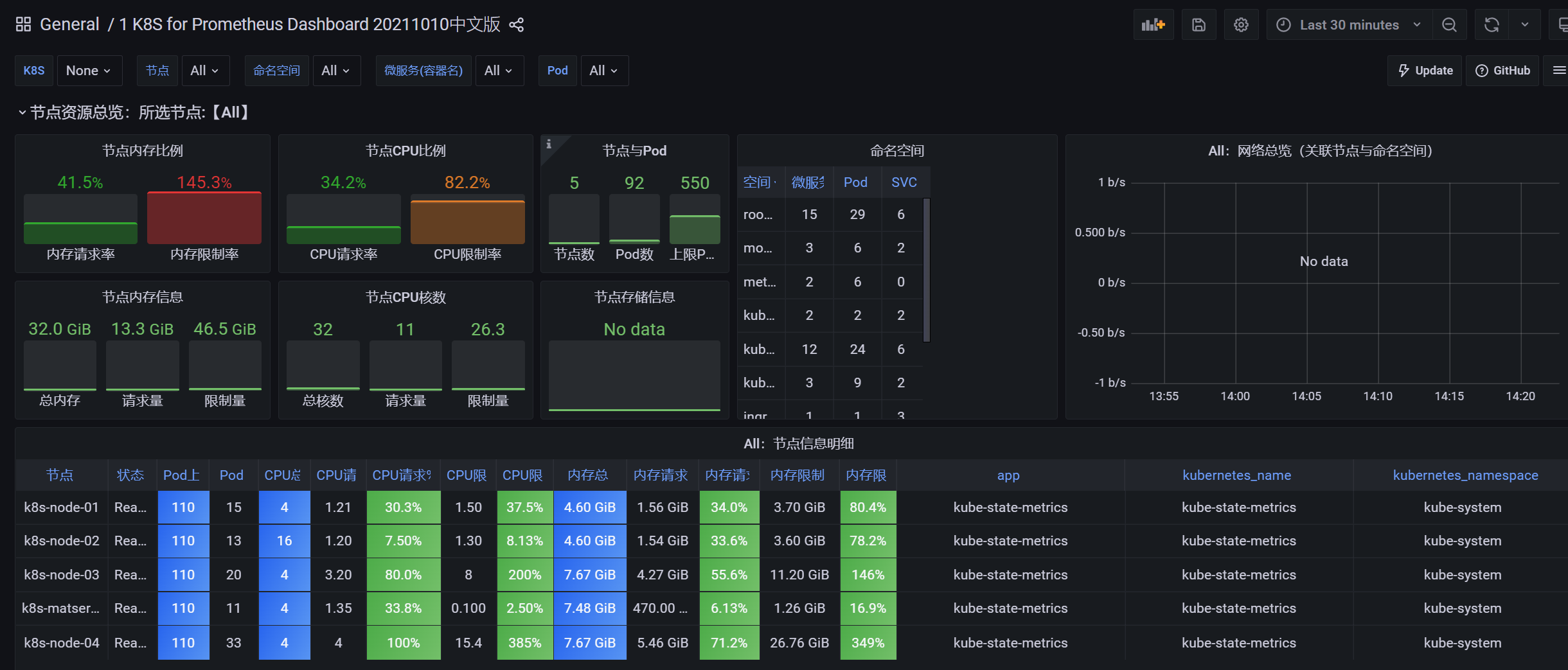
5.2 导入监控模板
参看官网 https://grafana.com/grafana/dashboards/
导入ID 13105 ID 是最好看的模板
第一部分
监控容器
推荐ID
13105
11074
3146
8685
10000
8588
315优化315
第二部分
监控物理机/虚拟机(linux)
推荐ID
8919
9276
监控物理机/虚拟机(windows)
推荐ID
10467
10171
2129
6.安装alermanager
6.1 安装alermanager svc地址
---
apiVersion: v1
kind: Service
metadata:
labels:
name: prometheus
kubernetes.io/cluster-service: 'true'
name: alertmanager
namespace: monitor-sa
spec:
ports:
- name: alertmanager
nodePort: 30066
port: 9093
protocol: TCP
targetPort: 9093
selector:
app: prometheus
sessionAffinity: None
type: NodePort
7.企业邮箱接受报警信息
7.1 开启企业邮箱授权码
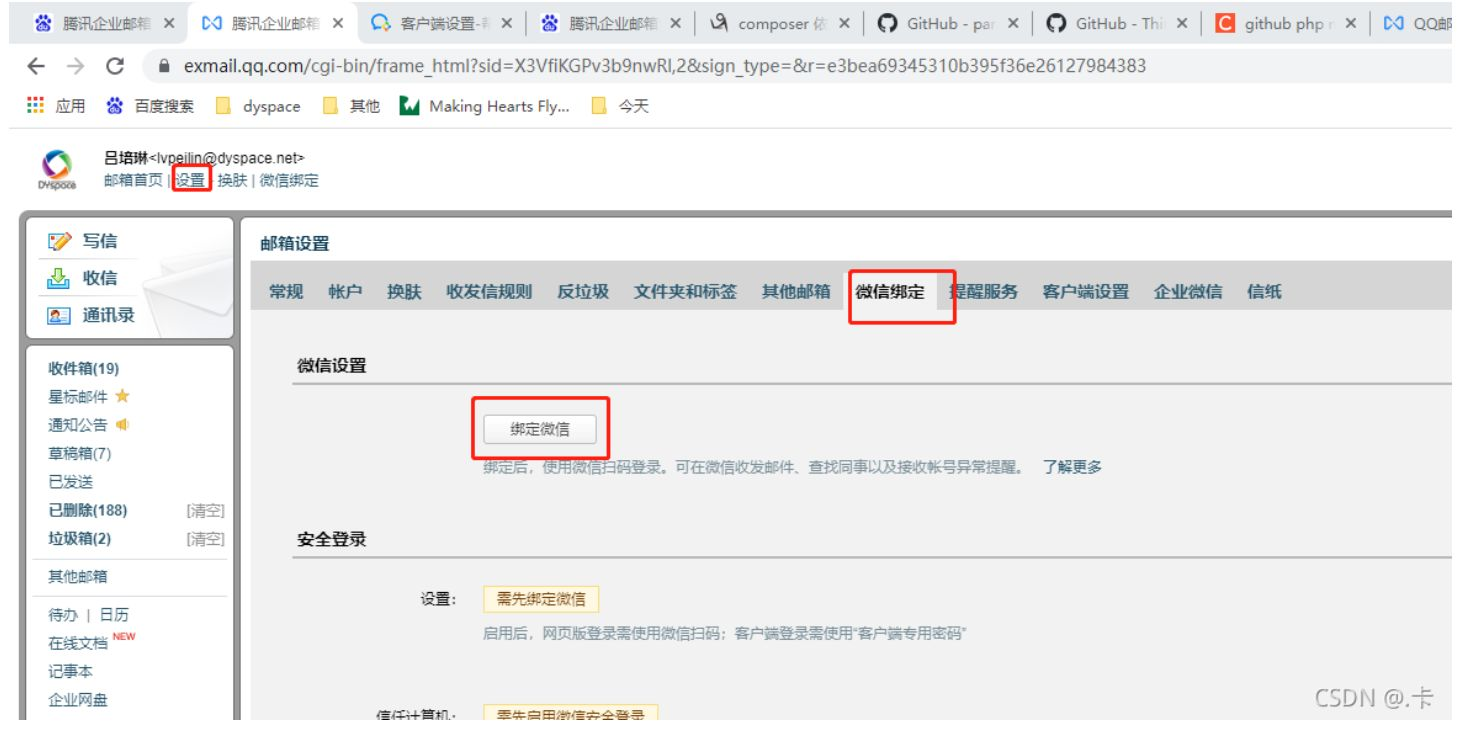
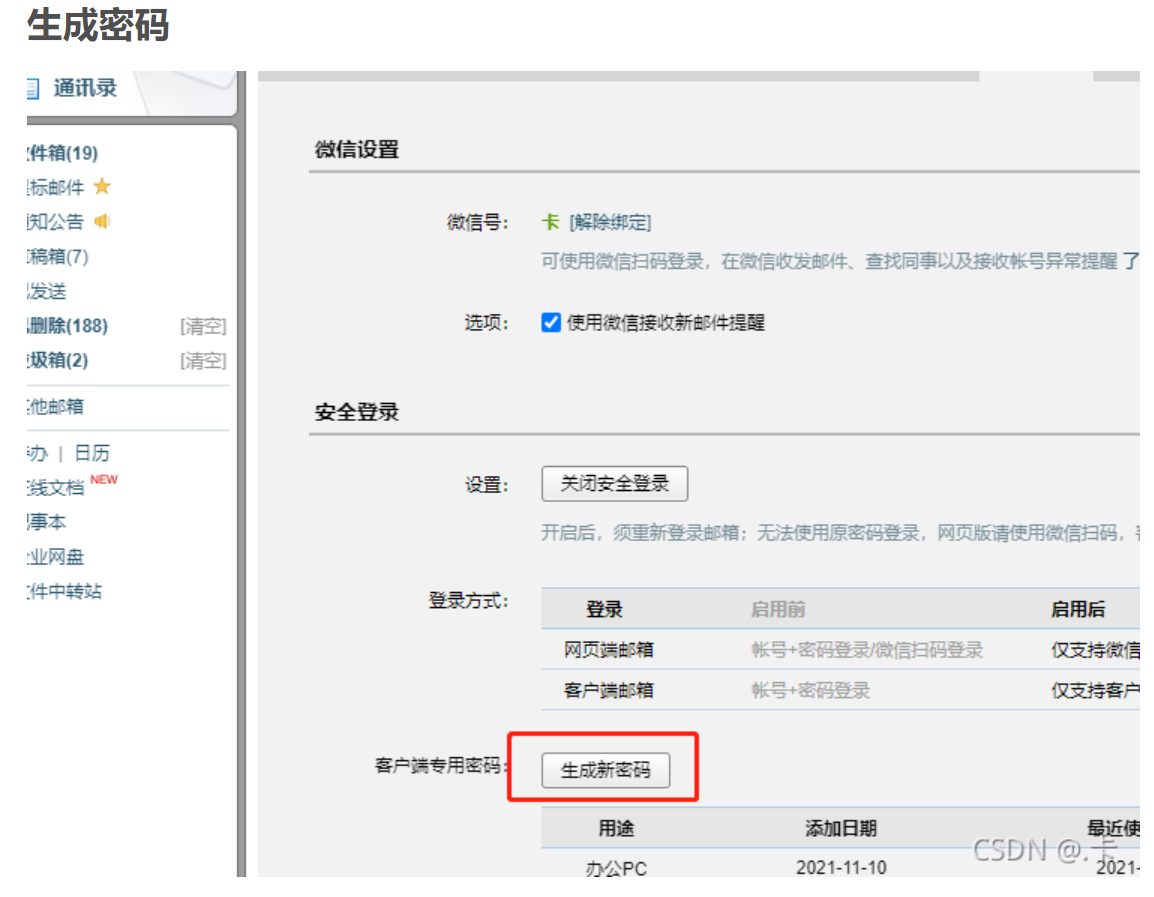
7.2 企业邮箱报警配置
kind: ConfigMap
apiVersion: v1
metadata:
name: alertmanager
namespace: monitor-sa
data:
alertmanager.yml: |-
global:
resolve_timeout: 1m
smtp_smarthost: 'smtp.exmail.qq.com:465'
smtp_from: '****@****.com'
smtp_auth_username: '****@****.com'
smtp_auth_password: '授权码'
smtp_require_tls: false
route:
group_by: [alertname]
group_wait: 10s
group_interval: 10s
repeat_interval: 1m
receiver: default-receiver
templates:
- '/etc/alertmanager-tmpl/*.tmpl'
receivers:
- name: 'default-receiver'
email_configs:
- to: '****@****.com'
html: '{{ template "email.to.html" . }}'
# webhook_configs:
# - url: 'http://10.5.11.115:31118/webhook'
# html: '{{ template "email.to.html" . }}'
# send_resolved: true
7.3 企业邮箱模板
apiVersion: v1
kind: ConfigMap
metadata:
name: alertmanager-template
namespace: monitor-sa
data:
email.tmpl: |-
{{ define "email.from" }}Sunny_lzs@foxmail.com{{ end }}
{{ define "email.to" }}Sunny_lzs@foxmail.com{{ end }}
{{ define "email.to.html" }}
{{ range .Alerts }}
=========start===========<br>
告警类型: {{ .Labels.alertname }}<br>
告警级别: {{ .Labels.severity }}<br>
告警信息: {{ .Annotations.description }}<br>
当前数值: {{ .Annotations.value }}<br>
触发时间: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}<br>
=========end===========<br>
{{ end }}
{{ end }}
7.4 效果图

8. 报警路径对接企业微信
8.1 获取企业微信URL
会获取到一个URL 地址
https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=95b*****
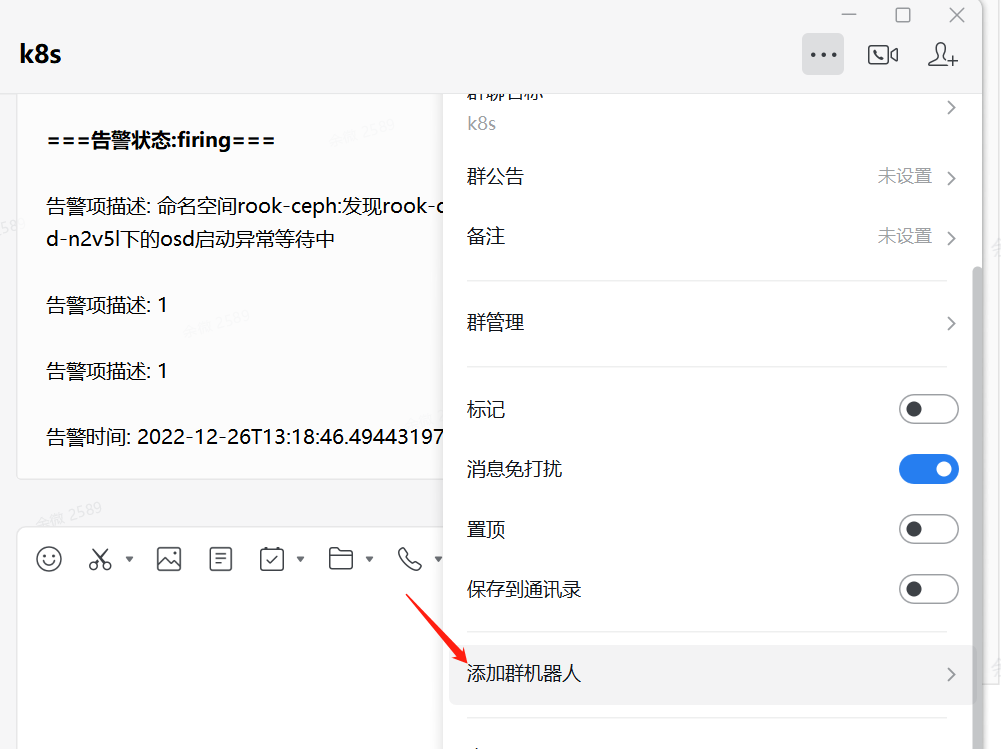
8.2 部署wxwork
apiVersion: v1
kind: Service
metadata:
name: wxwork-webhook
spec:
selector:
app: wxwork-webhook
ports:
- name: test-webhook
nodePort: 31118
protocol: TCP
port: 5233
targetPort: 5233
type: NodePort
sessionAffinity: None
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: wxwork-webhook
spec:
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: wxwork-webhook
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
type: RollingUpdate
template:
metadata:
labels:
app: wxwork-webhook
spec:
automountServiceAccountToken: false
affinity:
securityContext:
runAsNonRoot: true
runAsUser: 65534
dnsPolicy: ClusterFirst
containers:
- name: wxwork-webhook1
image: registry-vpc.cn-hangzhou.aliyuncs.com/mysoft-registry/wxwebhook:0.1.6
imagePullPolicy: IfNotPresent
resources:
limits:
cpu: 200m
memory: 100Mi
requests:
cpu: 10m
memory: 20Mi
ports:
- containerPort: 5233
workingDir: /usr/local/wxwork-webhook/
command:
- "python"
- "app.py"
- "--wxwork-webhook"
- "https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=95bb0aca-53dc-44f4-9******ed0"
- "--port"
- "5233"
volumeMounts:
- name: timezone-volume
mountPath: /etc/localtime
readOnly: true
- name: template-volume
mountPath: /usr/local/wxwork-webhook/templates/markdown.j2
subPath: markdown.j2
volumes:
- name: timezone-volume
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
- name: template-volume
configMap:
name: wxwork-template
8.3 部署wxwork 监控模板
apiVersion: v1
kind: ConfigMap
metadata:
name: wxwork-template
data:
markdown.j2: |-
告警信息【{{ alert_num }}】
[查看告警详情]({{ external_url }})
{% for msg in alert_messages %}
**===告警状态:{{ msg.status }}===**
{% if msg.status == "resolved" %}
{% for key, value in msg.annotations.items() %}
{% if key == "summary" %}
恢复项: {{value}}
{% endif %}
{% endfor %}
恢复时间: {{ msg.startsAt }}
{% else %}
{% for key, value in msg.annotations.items() %}
{% if key == "summary" %}
告警项: {{value}}
{% else %}
告警项描述: {{value}}
{% endif %}
{% endfor %}
告警时间: {{ msg.startsAt }}
{% endif %}
{% endfor %}
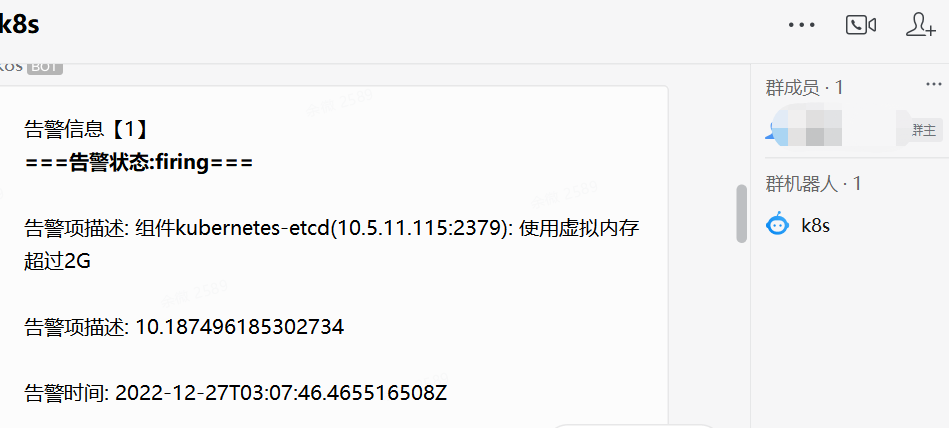
8.4 企业微信报警效果图
本文来自博客园,作者:小星奕的快乐,转载请注明原文链接:https://www.cnblogs.com/superzed/articles/17008269.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号