(原创)Re-ID八步实践-WINDOWS 10下跑起
最近在做客户视觉分析-追踪方案的时候,客户提出了一个需求:能不能“不要脸:)“就能进行模糊身份识别。
甲方一个供应商笑呵呵的说:“领导,人脸识别,人脸识别,不要脸怎么识别?哪有不要脸的,那就不叫人脸识别咯”
客户说,我见其他地方有这样的技术,就是不要脸就能识别,你们能做不能做?
供应商说,这个我们也了解了解,您既然说能做,那肯定是能做了!
我们眼见也把工作计划跟客户领导都交代清楚了,完事后上前那个提出不要脸识别的客户搭了一句:您好,确实您说的技术存在,而且现在进步挺大的,其名约“行人重识别技术,简称RE-ID”
那个客户立马眼睛亮了,来来来,既然有专家在场,那给我们快讲讲,不行我们可以立个项目啊,哈哈,回头眼睛扫了下那位供应商的眼神,一万把刀投向了我们一行人。
那接下来,我们讲讲这个技术是如何实现的……
RE-ID技术,其实这个是在人脸识别之后的重要的进步,尤其是不要脸就能识别人,就是通过衣物、配饰、骨骼、形态等特征进行综合判定,主要解决跨摄像头跨场景下行人的识别与检索。该技术可以作为人脸识别技术的重要补充,可以对无法获取清晰拍摄人脸的行人进行跨摄像头连续跟踪,增强数据的时空连续性。
下图在实现上,可以通过性别、背包颜色、裤子颜射、背包类型等进行特征识别。那么要做REID,首先我们需要进行这些特征的提取。
在这些姿态、衣服颜色、衣着特点被综合提取后,我们能够实现跨摄像头进行人员追踪,请见下图:下图由四张图片构成,黄色这个人是之前新闻报道中的偷小孩事件的人,这个人会出现在多个摄像头里,现在警察刑侦时会人工去检索视频里这个人出现的视频段。这就是 ReID 可以应用的场景,ReID 技术可以根据行人的穿着、体貌,在各个摄像头中去检索,把这个人在各个不同摄像头出现的视频段关联起来,然后形成轨迹,这个轨迹对警察刑侦破案有一定帮助。这是一个应用场景。
在这中间,也体现出REID的几个关注点或者说是难点。
- 第一组图,无正脸照。最大的问题是这个人完全看不到正脸,特别是左图是个背面照,右图戴个帽子,没有正面照。
- 第二组图,姿态。绿色衣服男子,左边这张图在走路,右图在骑车,而且右图还戴了口罩。
- 第三组图,配饰。左图是正面照,但右图背面照出现了非常大的背包,左图只能看到两个肩带,根本不知道背包长什么样子,但右图的背包非常大,这张图片有很多背包的信息。
- 第四组图,遮挡。左图这个人打了遮阳伞,把肩部以上的地方全部挡住了,这是很大的问题。
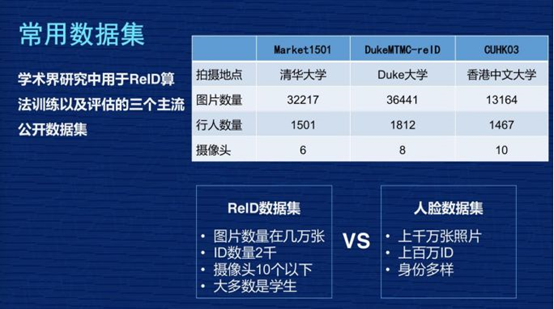
既然采用深度神经网络,那么肯定离不开训练数据集。通过训练,我们得到训练的模型weights文件,通过该文件对目标进行验证及评估。接下来我们看一下国际上最公认的三项数据集:
- 第一列,Market1501。用得比较多,拍摄地点在清华大学,图片数量有 32000 张左右,行人数量是 1500 个,相当于每个人差不多有 20 张照片,它是用 6 个摄像头拍的。
- 第二列,DukeMTMC-reID,拍摄地点是在 Duke 大学,有 36000 张照片,1800 个人,是 8 个摄像头拍的。
- 第三列,CUHK03,香港中文大学,13000 张照片,1467 个 ID,10 个摄像头拍的。
(待续……)






 浙公网安备 33010602011771号
浙公网安备 33010602011771号