机器学习漫游(1) 基本设定
最近的十几年机器学习很是火热,尤其是其中的一个分支深度学习在工业界取得很好应用,吸引了很多眼球。不过从其历程来看,机器学习的历史并不短暂~从早期的感知机到八十年代火热的神经网络,再到九十年代被提出的经典算法集成学习和支持向量机;而最近的十年算得上是机器学习发展的黄金年代,软、硬件计算条件大幅提高,尤其是现在数据量的爆发式增长让机器拥有充分“学习”的资本,另一方面现在开源项目越来越多,即便一些算法的实现很复杂,我等小白只需要调几个接口也能完成对数据的处理;在这个年代里,不同的人充斥着不同的野心,计算机科学家仍在探索人工智能的奥义,资本、媒体都在热炒机器学习概念,大数据、AI俨然成为宠儿,各行程序员也在茶余饭后有了谈资。盛名之下,其实难副,机器学习、人工智能的发展还处在浅层,特别是深度学习这些被媒体过度炒作的产物,从计算智能到感知智能再到认知智能,前面的路依然很远。长路漫漫,不管怎样,越来越多的人投入这个行业确实对行业本身有很大的发展,特别是可以看出,国内外很多高校的专家学者已经把研究阵地转向工业,不仅仅是因为报酬丰厚,更因为工业界提供了现实场景更丰富的数据,而这些数据让算法拥有很好的施展空间。
还记得16年在亚马逊买了一本南大周志华老师的<<机器学习>>,到手之后真的超出了预期,书上面的算法介绍的比较系统,每一章节提到了某个领域的经典算法,后面给出的附录也适合非科班同学看懂~更难得是这是一本中文的可以当成教材的书~而且从写的内容来看,真的很谦虚、严谨,总之比较推荐入门的同学看,因为之前一直被广为人知的还是NG的斯坦福大学Machine Learning公开课讲义,现在终于有本好的中文图书了。 似乎有些偏题了:)初衷只是想写一个机器学习系列笔记的开篇,算是对自己的一个督促吧,现在很多时候感觉脑子不动真的是要上锈了~好了不多说了,下面进入正题吧~
1.概念
机器学习到底是什么?Wiki上有Tom M. Mitchell这样一段定义:
"A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E."
我经常这样总结: “设计模型,并从已观测的数据中学习出模型参数,然后通过模型对未知进行分预测 。”这样说似乎还是有点抽象,台大李宏毅老师ppt解释的非常形象:
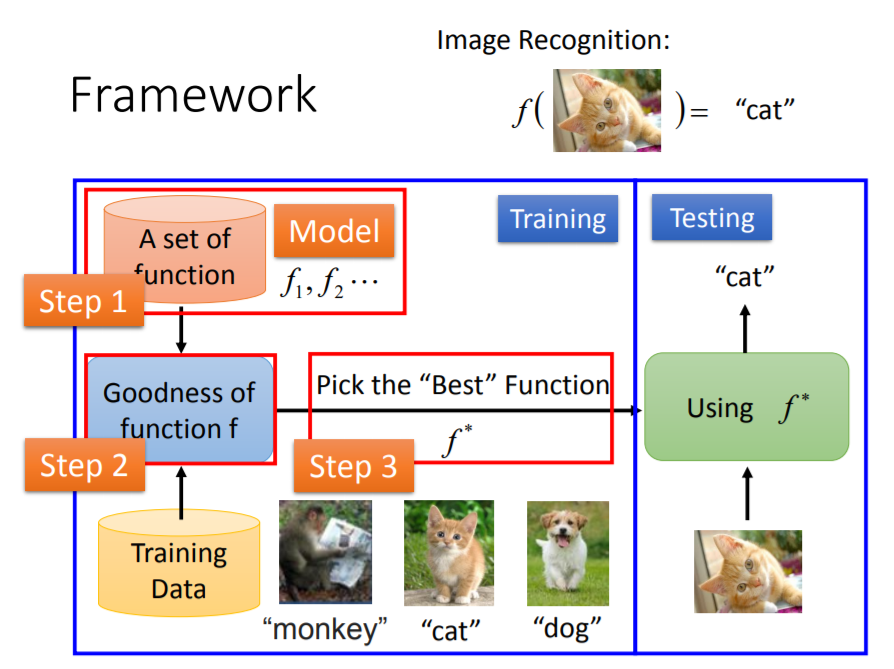
这个图解释的含义是什么呢?可以这样看:
机器学习的本质是进行预测,比如我们想要判断一幅输入的图像是猴子,猫还是狗。怎样预测呢?
(1)首先,我们需要找到一个模型来表达预测的过程,这个模型可能包含一个或者多个需要设定的参数,因此模型是一个多个函数组成的集合;
(2)在模型确定了之后,我们需要从数学上寻找一个函数来表示这个模型,即从函数集合中寻找一个能够“准确”地表达模型,这一步我们需要在已知的数据上进行学习,即让函数能够在已知数据上获得很不错的预测效果;
(3)使用(2)中确定的函数对未知的数据进行预测。
一个典型的机器学习系统包含输入和输出空间,分别对应输入和输出所有可能取值的集合。输入值,简称样本,描述了样本不同特征或者属性的取值,它可以是一个向量,矩阵,张量或者其他更为复杂的数学形式;比如:
\( x=\left ( x^{1},x^{2},...x^{n}\right )\)
输出值一般是离散或者连续的值,如果是离散的,对应于分类问题,此时描述了样本的类别标签,如果是连续的则对应于回归问题,描述了具体的输出值,输出值通常可以用\(y\)表示。机器学习系统的目标在于利用已知数据信息,设计“合理的”函数映射,在给定新的未知数据时,使得输出值比较符合我们的预期:
\(F=\left \{ f|Y=f_{\theta }(X),\theta \in R^{n} \right \}\)
大写的\(X\)和\(Y\)分别对应于某个输入或者输出的集合。好的特征输入对于机器学习模型的设计尤为重要,比如很多电商需要预测用户可能购买或者感兴趣的产品,怎样基于用户过去的购买、浏览、收藏等行为构建行为特征,把具体的用户行为数学化;如果我们需要对房价进行预测,我们可能会拥有已有房产的大小、地理位置、户型甚至当前房市总体行情等特征,我们需要选择哪些特征并处理成模型的输入形式,这对预测的最终结构非常重要,像这种特征选择或者处理在数据挖掘中做的非常多,我们有时叫做业务模型构建,这其实并不是机器学习过度关注的问题,机器学习更加关注与模型和算法本身。
我把机器学习做的事情概括成任务、策略和方法,其中任务描述了机器学习的最终目的,而策略描述了机器学习在处理问题时使用的方案,方法则是机器学习在处理实际问题中使用的具体方法。
2.任务
机器学习的本质在于使用已知数据的”经验“来预测未知数据,从模型的输出来看,我们处理实际问题的最终目的主要可以分成两种,一是分类(classification),即预测某个输入样本对应的类别,或者叫标签;二是回归(regression),即预测输入样本对应的具体的输出值。
(1)通俗一点的来讲,分类也就是我们通常所说的“识别”,比如上图中判断图像中是否包含一只猫。分类包含二元分类和多元分类,即模型可能输出的标签是2个或者大于2个,比如判断图像中是否存在猫,判断一封邮件是不是垃圾邮件,这里输出有或者无,是典型的二元分类,判断图像中是猫还是狗、猴子或者其他动物则是多元分类,可以看出分类模型中输出的值是离散的值。
(2)回归是指模型的输出可能是多个连续的值,比如要预测明天天气的最高温度,这里的温度就是一个存在于某个范围区间的值;房价预测、无人驾驶方向盘输出角度预测都可以看成是回归任务。
3.策略
在不同的场景下我们会遇到不同类型的数据,而数据的不同也会导致我们设计机器学习模型的策略不同,通常情况下可以分成以下几种:
(1)有监督学习(supervised learning),即给定的样本是有标记的;
(2)无监督学习(supervised learning),即给定的样本是无标记的;
(3)半监督学习(semi-supervised learning),一部分样本是有标记的,另一部分是无标记的。
大多数现实机器学习模型都是有监督学习,因为已知输出的数据训练效果对最后预测的结果影响太大了。有监督学习强调人类教“机器”进行“学习”,比如小孩子可能没有见过猴子(现实的或者图片),但是父母会告诉他:“这是一只猴子”,因此孩子的大脑皮层会对此做出记忆和处理,认为这种类型的东东是一只猴子;并且在看到其他动物的时候,大脑会将其图像和猴子的特征进行相似度比较,来判断是一只猴子还是其他动物,这一行为是典型的有监督学习;无监督学习强调让机器自己去学习,比如聚类算法,机器可以自己进行归类,而不需要任何标记的数据。考虑到现实场景获取有标记的数据代价较高,你需要人工的方式去打标记,而网络社会中包含大量没有标记的数据,这些数据很好获取,更为重要的是这些数据对于对于预测本身是有很大帮助的,比如近些年比较热门的一个方向迁移学习,如果我们要做人脸识别,由于人脸头像存在角度、光照等复杂外界因素的干扰,那么是否可以借助这些大量的不同场景的无标记数据实现模型本身的迁移,从而使其更能适应干扰,提高识别的精度呢?这就是迁移学习的一个重要作用。
4.方法
方法就是具体的模型设计用到的方法,比如线性方法或非线性方法,线性方法比如早期的感知机,线性回归,线性的子空间投影方法(如经典的降维算法,主成分分析)等等,非线性方法比如现在火热的深度神经网络,支持向量机等等,这些在后面的文章中会提到。
5.经验风险最小化、结构风险最小化和过拟合、欠拟合
有了模型和样本之后我们需要利用这些样本,即通过这些已经观测得到的数据对模型参数进行训练,这个过程也就是“学习”或者“训练”,然后通过学习的模型对未知数据进行预测的过程可以称之为“预测”,预测的目的在于检验学习得到模型的好坏。然而一个机器学习系统的好坏不仅和模型设计有关,而且和数据的特点有很大关系,“No free lunch”告诉我们,模型的设计必然会带来某些方面的代价或者损失,因此必须综合数据的特点、算法模型、开销等等各个方面来设计,比如在某些情况下样本规模大小和数据的分布完全不知道,倘若在设计模型的时候过于追求精度,致使模型对训练样本的预测效果很好,但是在预测新的未知数据时效果很差,也就是我们常说的“过拟合”问题。
举一个很直观的例子,小明学习的基础并不是很好,在学习了一个新的知识点之后做了很多习题,这些习题套路固定,题型类似,然后需要进行测试,如果测验用的题目和题型与练习的题目变化不大,那么小明在考试中很有可能取得很好的成绩,然而这种测试获得的成绩“掩盖”了背后的假象,一旦出题老师换一个全新的套路,小明的成绩很有可能就炸了。可以看出,“过拟合”意味着模型适应不同场景数据的能力,我们有时候叫做“泛化能力”。过拟合问题是机器学习长期需要面对的挑战之一,而现实中有很多情况掩盖了过拟合带来的问题,其中之一便是数据量,比如小明如果平时做的习题足够足够多,那么还是很有可能应付测验的。
再者,我们也不能让一个模型为了过于适应复杂场景,追求算法的适应能力,但是过多的损失了精度,这就是“欠拟合”。下面的样本分布图(样本分布图通常以二维坐标的形式展示样本的分布情况)给出了一个示例来展示欠拟合和过拟合。用小圈圈表示二维平面中的样本,其中红色圈圈表示训练样本,绿色圈圈表示真实样本,然后我分别用不同的多项式曲线去拟合这些样本,可以看出第一幅图中的简单直线并没有准确的对训练样本和真实样本进行拟合,但是从一定程度表示出了样本的“大概趋势”,这是“欠拟合”;第二幅图中的曲线拟合地效果比较好,尽管在个别样本稍有偏差,但就预测真实样本而言是三张图中最好的,这正是理想情况下需要寻找的模型;相比较而言,第三幅图中的曲线虽然能“完美”地反映出训练样本点的位置,不过存在很大的缺陷,也就是曲线过于复杂,在真实的环境下会遭遇严重的过拟合问题,比如横坐标9到10的这些点与预期值差别巨大。



在很多情况下,大量的数据是不可多得的,有时候我们尝试从模型而不是数据方面着手解决此问题,因此怎样合理地控制模型,使之避免过拟合呢?
首先在监督学习中,我们需要定义一定的标准来保证学习的精度的好坏,显而易见的是,我们可以使用一种叫做“损失函数”的东东来衡量结果,损失函数可以解释为“衡量预测值和实际值之间的一致性”。损失函数可以使用\(L\left ( Y,f(X)) \right )\)来表示,很容易想到的一种关于\(L\)的表示是使用衡量预测值和实际值之间的偏差,为了保证偏差总是大于0的,可以用\(L\left ( Y,f(X)) \right )=\left ( Y-f(x) \right )^{^{2}}\)来表示,还有的模型可能会使用偏差的绝对值之和、0-1值或者其他的方式定义损失函数。实际上如偏差平方和形式的损失函数是基于最小二乘拟合的一种应用,基于极大似然估计可以得到,在后面博客中写到线性回归的时候提到~如果给定训练集合,也就是包含多个样本的数据集,模型关于样本的平均损失可以称之为经验损失或者经验风险,顾名思义,也就是根据已给出的数据经验式地衡量模型的好坏。比如,对于训练集
\(\left \{ (x_{1},y_{1}),(x_{2},y_{2},...,(x_{m},y_{m}))\right \}\)
对应的经验损失可以定义为:
\(R_{emp}(f)=\frac{1}{n}\sum _{i=1}^{n}L(y_i,f(x_i))\)
直观地来说,如果需要机器学习的预测效果好,要求经验损失最小,也就是我们常说的经验风险最小化(Empirical Risk Minimization, ERM),基于此策略,可以考虑如下的经验风险最小化最优化模型:
\(\mathrm{min} \frac{1}{n}\sum _{i=1}^{n}L(y_i,f(x_i))\)
在样本数据量很大的情况下ERM往往能获得很好的预测效果,但是正如前面提到的,一旦数据规模较小,会出现“过拟合”的情况。过拟合是很多机器学习问题都会面对的一大挑战,很多方法用来避免出现过拟合。除了增大数据量以外,其中一个常见的做法是对模型的复杂程度进行约束,也就是添加正则化项(regularizer)或惩罚项(penalty)直观上来说模型越复杂,越难以模拟真实场景。翻看很多paper,不管是大牛的也好,灌水的也好,限制模型复杂度作为惩罚项已经是一件司空见惯的事情了~毕竟惩罚项很容易对模型进行解释了,尽管有时候随意添加惩罚项的效果并不怎么好... 这种约束模型复杂程度的做法叫做“结构风险最小化”,意在ERM的基础上限制模型复杂度:
\(R_{srm}(f)=\frac{1}{n}\sum _{i=1}^{n}L(y_i,f(x_i))+\lambda J(f)\)
上式中\(J(f)\)即模型复杂度项,系数\(\lambda\)为ERM和模型复杂惩罚之间的平衡因子~不过不同模型处理过拟合会使用不同的方法,比如在回归分析中添加的\(L_{1}\),\(L_{2}\)惩罚项,得到的lasso回归和岭回归;在决策树中使用剪枝来降低模型复杂度;在深度神经网络中使用dropout;等等。
6.模型评估和验证
在我们训练得到一个模型之后,我们需要一定的手段来对模型进行评估,大多数情况我们会预留出一部分数据作为测试集,使用这一部分数据进行验证工作。在模型评估环节当中我们不仅需要模型有精确地预测效果,还需要很强的健壮性,在算法精度和性能上都有好的表现。通常的一个做法是我们需要对样本集合做交叉验证,多次选取不同或者不同规模的训练集合进行评估。另外,不同的场景我们需要考虑的侧重点可能不一样,比如我们做一个账号产品缺陷检测系统,我们会更关注在真实的缺陷样本是否被检测出来,而不是真实的无缺陷样本有没有被检测出来。我们在类似于这样的二分类问题中使用召回率、错误接受率、正类准确率、准确率和F-measure等指标来衡量分类效果,用FP、FN、TN和TP定义以下行为样本的个数:
FP:真实样本是负例,被错误地预测为正例;
FN:真实样本是正例,被错误地预测为负例;
TN:真实样本是负例,被正确地预测为负例;
TP:真实样本是正例,被正确地预测为正例。
召回率(Recall Rate):其定义为\(\frac{TP}{TP+FN}\)。召回率是一种重要的分类器性能衡量指标,因为在实际应用中需要重点考虑的是正类的数据,其反映了被正确判定的正类样本占总的正类样本的比重,即衡量着正类样本检测的全面程度。
错误接受率(False positive rate):其定义为\(\frac{FP}{FP+TN}\)。 其反映了分类结果中负类数据被预测为正类数据的比例。
正类准确率(Precision):其定义为\(\frac{TP}{TP+FP}\),衡量检测到正类样本的准确率。
准确率(Accuracy):其定义为 \(\frac{TP+TN}{TP+FN+FP+TN}\)。其衡量着所有正确分类的样本占总样本的比例。
从以上定义看出,一个好的的分类器预测模型,希望能满足较高的召回率、正类检测准确率以及准确率,较低的错误接受率。然而,实际情况中,查准率和召回率之间往往难以同时都达到较高的值,需要在二者之间寻求权衡,因此需要折中考虑二者。通常引入F-measure值来考虑衡量准确率和召回率的调和平均数,其被定义为:
\(F=2\ast\beta\ast recall*pre/(recall + \beta ^{2}\ast pre)\)
现如今很多模型的优劣可以通过比较有名的benchmark来度量,每个benchmark的度量标准可能不一样,比如在图像分类竞赛中有些度量标准还包括top5,我们用最匹配的5个样本来衡量准确率,因此,模型评估很大程度取决于业务场景和设定的规则。
7.总结
机器学习是一门关于预测的学科,即设计模型利用已知的数据预测未知的数据。数据分布和模型本身都对预测的结果有一定的影响,没有完美的模型,我们构建的是适用于不同场景的模型;在预测过程中我们会遇到过拟合、欠拟合等挑战,而在benchmark上对模型评估和验证为我们提供了调节模型的指标。
暂时写到这,后面的文章准备从线性模型开始,写一些机器学习中经典或者重要的算法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号