论文解析1:DNN for YouTube Recommendations
序:
作为一名刚进入职场的菜鸟级的程序员,开始本着每周一篇论文的原则,但是由于之前的工作比较偏业务工程,就将此搁置,最近开始做模型方向的东西,终于有机会重拾目标。第一篇读的论文就是youtube的这篇文章,记下笔记和理解,方便以后对某些理解错误的点进行改进。
1 论文的出发点:
youtube推荐遇到的三个主要问题:
-
scale:用户和视频熟练巨大,分布式learning algorithms 和高效的serving系统
-
freshness:视频更新速度很快,需要在新帖和老帖之间进行balance,更新快就要求模型能够迅速的追踪用户的实时行为,进而实现exploration/exploitation 【准确性和多样性】
-
noise:用户反馈数据的稀疏以及模型未学到的隐藏的特征【视频本身的很多数据都是非结构的】
论文主要架构:
-
召回:将用户的历史行为作为输入,训练数据为用户数*点击数,然后选出与用户高度相关的小型候选集用作ranking,取消了item特征的构造,根据item的id,利用DNN来学习item的embedding特征,利用用户的历史点击来表示用户的特征,用户之间的相似性由一系列的特征【观看过的视频id序列,用户属性,搜索历史】表示。
-
ranking:利用学到的user和video特征,通过objective function 计算得分
2 recall:
2.1 问题建模
将整个召回过程看成是一个多分类问题,类别的总集合就是输入的视频个数,每一个视频都会在最终得到一个概率值作为score。即在当前时刻t,为用户u在当前上下文C下在视频集合中预测出每一个视频i出现的概率。最终的结果表示是一个softmax分类器。输入的u<user,content>,i都是 embedding<1>的向量,而DNN网络的作用就从输入的embedding中学习u的embedding<2>向量,这里u的两个embedding意义是不一样的。第一个embedding是训练模型时的输入特征embedding,而u第二个embedding是DNN网络最后一层输出来作为用户的近似特征user vector。而i的第二个embedding指video vector,是预测时使用softmax matrix中每一个video 对应的权重w作为video的vector是线上inference使用的。
最终的问题就归结于:
-
通过不断降低真实p和预测p的loss,来调整video vector和user vector,整体的思路可以看作是利用DNN来模拟矩阵分解,【🐱小插曲】具体思路为:模型最后一层通过softmax得到的概率分布为:
h是softmax的计算公式, ![\psi(x)]() \psi(x) 是DNN的输出,
\psi(x) 是DNN的输出, ![V]() V 是softmax的权重矩阵,利用交叉熵来 衡量损失,真实的softmax输出是一个onehot编码.由此,
V 是softmax的权重矩阵,利用交叉熵来 衡量损失,真实的softmax输出是一个onehot编码.由此, ![<\psi(x).V^{T}>]() <\psi(x).V^{T}> 类比矩阵分解。用 DNN来代替用户矩阵生成。这里用DNN代替矩阵分解产生用户特征矩阵的好处在于可以更方便的加入连续特征和离散特征。
<\psi(x).V^{T}> 类比矩阵分解。用 DNN来代替用户矩阵生成。这里用DNN代替矩阵分解产生用户特征矩阵的好处在于可以更方便的加入连续特征和离散特征。
A key advantage of using deep neural networks as a gener- alization of matrix factorization is that arbitrary continuous and categorical features can be easily added to the model. Search history is treated similarly to watch history - each query is tokenized into unigrams and bigrams and each to- ken is embedded. Once averaged, the user’s tokenized, em- bedded queries represent a summarized dense search history. Demographic features are important for providing priors so that the recommendations behave reasonably for new users. The user’s geographic region and device are embedded and concatenated. Simple binary and continuous features such as the user’s gender, logged-in state and age are input di- rectly into the network as real values normalized to [0, 1]
2. 在这种超大规模的分类问题上,文章使用了负采样和importance weighting对采样进行校准。
2.2 模型构建
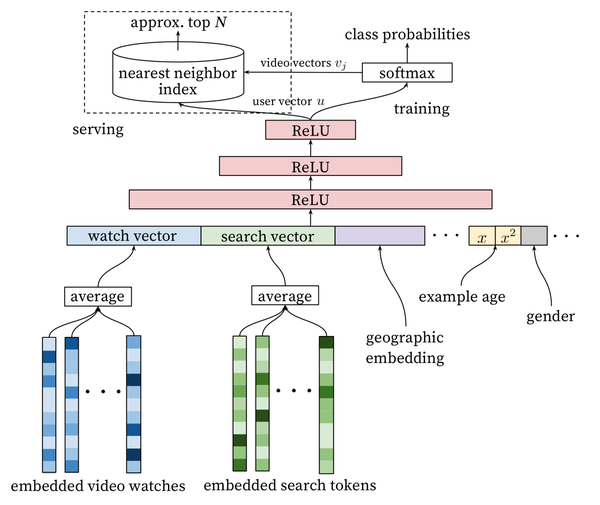
-
最底层是用户观看过的video的embedding向量,这里向量的生成有两种方式:第一种是先用word2vec对video做embedding,第二种通过一个embedding层加上上面的dnn一起训练。再与其他的特征向量做concat喂给上层的relu.
原文:Inspired by continuous bag of words language models [14], we learn high dimensional embeddings for each video in a fixed vocabulary and feed these embeddings into a feedfor- ward neural network. A user’s watch history is represented by a variable-length sequence of sparse video IDs which is mapped to a dense vector representation via the embed- dings
2. 经过三层神经网络,最后通过一个softmax,将问题转为用户最可能看的next watch问题。模型的输入是embedding用户浏览历史,搜索历史等的concat向量,输出分线上和线下两部分,线下输出的就是softmax输出层,线上是采用最近邻搜索,而不直接采用训练时得到的model,这样做的原因:在serving时,如果对每一个后选集都跑一遍模型开销比较大,所以通过线下得到的user和video的vector<可以存储在redis或者内存中> 做最近邻,来代替在服务器上进行model inference.
3. 为了拟合用户对新视频的偏好,模型引入了 Example Age 这个特征,模型在训练阶段是利用过去的行为预测未来,因此,对过去的行为都会有一个隐性的bias。按照视频本身的分布规律,他的分布是非静态的,但是推荐系统最终的推荐的视频分布,基本上是训练时间段内平均喜欢观看的视频。因此在训练阶段引入这个Example Age,这个特征就类似于推荐结果中的rank(pos)特征,因此在serving的时候,这个特征通常被设置为0.线下训练将log(第一次打点的时间距离当前训练时间),关于线上serving-Example Age的计算,文章是这样表达的:
At serving time, this feature is set to zero (or slightly negative) to re- flect that the model is making predictions at the very end of the training window.
2.3 label和content的选择
-
为每一个用户生成固定数量的训练样本:防止活跃用户带偏模型
Another key insight that improved live metrics was to generate a fixed number of training examples per user, effectively weighting our users equally in the loss function. This prevented a small cohort of highly active users from dominating the loss
2. 丢弃RNN中的时序信息:如果不丢弃,用户的推荐结果将过多受最近观看或搜索的一个视频的影响。为了综合考虑之前多次搜索和观看的信息,YouTube丢掉了时序信息,将用户近期的历史纪录等同看待。【没想清楚?????】
By discarding sequence information and representing search queries with an unordered bag of tokens, the classifier is no longer directly aware of the origin of the label.
3. 选择测试集:没有采用原始的hold-out方法,而是使用用户最近一次的行为作为测试集
3 RANKING
ranking由于比recall需要评估的样本数量小很多,因此,可以引入更多的特征来对每个视频进行打分。
ranking阶段的评价指标为:预期播放时长excepted watch time,这里不使用ctr的原因在于单纯的ctr指标是具有不确定性的,有些视频属于诱饵视频,用户点击后并不会对视频进行播放,因此,观看视频时长更能反应用户的兴趣,增加用户粘性。
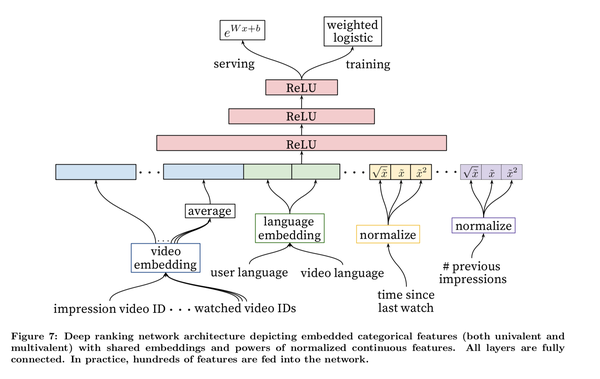
3.1 特征工程
特征工程最重要的是对用户的时序行为进行建模,并且将这些行为与要rank的item进行关联。文章指出最重要signal是描述用户与item或者相似item的交互行为,比如计算用户对视频的喜好,可以度量在用户历史行为中对视频所在channel的得分:
-
用户在这个channel中观看了多少视频
-
在这个channel下用户最近一次观看视频的时间 这两个连续特征最大的好处在于在不同的item上具有很好的泛化能力
a)Embedding Categorical Features
对于离散特征进行embedding处理,每一个纬度都有独立的embedding空间,但不是所有的id都要进行embedding操作,比如视频id,在训练的时候,之后截取点击频次的topN进行embedding,将大量长尾的id用0向量表示。这么做的原因一方面是是节约线上serving的内存消耗,另一方面是低频的视频准确性也不好。对于multivalent特征,比如用户过去点击过的视频,使用加权平均
b)Normalizing Continuous Features
由于神经网络对于输入数据的尺寸和分布比较敏感,而归一化方法对收敛很关键,因此,文章采用排序分位归一到区间[0,1)的方法,利用公式计算累计分位点作为归一化后的值:
3.2 模型serving
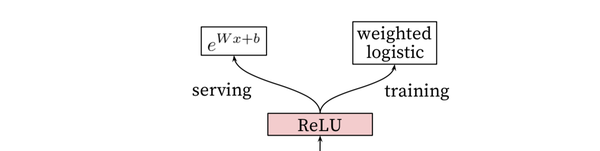
ranking在训练时候,采用的是weighted LR作为输出层
Question【❓】:对于传统的nn框架,通常使用LR或者softmax作为输出层,而在线上serving的时候也是原封不动的使用LR或者softmax来计算正样本的概率,为什么选择weighted LR作为输出层,如何训练weighted LR?模型serving的时候也没有使用sigmoid,而是使用exp(wx+b)这种指数形式来预测观看时长?
问题1:因为上面已经说过,文章预测的目标是观看时长期望,而不是点击,因此,将时长权重加入模型的训练,这里需要引入一个发生比odds的计算 ![odds=\frac{p}{1-p}=\frac{N^{+}}{N-}]() odds=\frac{p}{1-p}=\frac{N^{+}}{N-} (正样本与与负样本的比值),weightLR的特点是将正样本的权重变为之前的W倍,而这个带来的影响,并不是使得这个正样本发生的概率提升W倍,而是使得整个odds变为原来的w倍,也就是对预估的影响(loss)提升w倍。
odds=\frac{p}{1-p}=\frac{N^{+}}{N-} (正样本与与负样本的比值),weightLR的特点是将正样本的权重变为之前的W倍,而这个带来的影响,并不是使得这个正样本发生的概率提升W倍,而是使得整个odds变为原来的w倍,也就是对预估的影响(loss)提升w倍。
问题2:训练Weight有两种方式:第一种是将一条正样本重复w倍,这样在优化的时候,每次遇到这个样本,都会用梯度更新一次参数,一直迭代w次;第二种是更新一条正样本的梯度的时候,将梯度直接乘以w
问题3:从推导过程 ![odds=\frac{p}{1-p}\Rightarrow odds(i)=\frac{w_{i}p}{1-w_{i}p} \approx w_{i}p = T_{i}p = E(T_{i})]() odds=\frac{p}{1-p}\Rightarrow odds(i)=\frac{w_{i}p}{1-w_{i}p} \approx w_{i}p = T_{i}p = E(T_{i}) 可以得出:想要预测用户观看时长,就要计算odds,另一方面:
odds=\frac{p}{1-p}\Rightarrow odds(i)=\frac{w_{i}p}{1-w_{i}p} \approx w_{i}p = T_{i}p = E(T_{i}) 可以得出:想要预测用户观看时长,就要计算odds,另一方面: ![ln(odds) = \frac{p}{1-p} = \theta^{T}X \Rightarrow odds = e^{\theta^{T}X}]() ln(odds) = \frac{p}{1-p} = \theta^{T}X \Rightarrow odds = e^{\theta^{T}X}
ln(odds) = \frac{p}{1-p} = \theta^{T}X \Rightarrow odds = e^{\theta^{T}X}
因此,youtube使用exp(wx+b)这个指数形式预测的就是 曝光该视频时,用户播放该视频的时长,这样,与优化目标对齐。
结论:
-
e^{Wx+b}这一指数形式计算的是Weighted LR的Odds;
-
weighted LR 使用的是用户观看视频时长作为权重,使得对应的odds的期望就是观看视频时长的期望
-
因此,serving过程中
e^{Wx+b}计算的正是观看时长的期望

 浙公网安备 33010602011771号
浙公网安备 33010602011771号