2024年mysql8、0学习
一、 索引结构
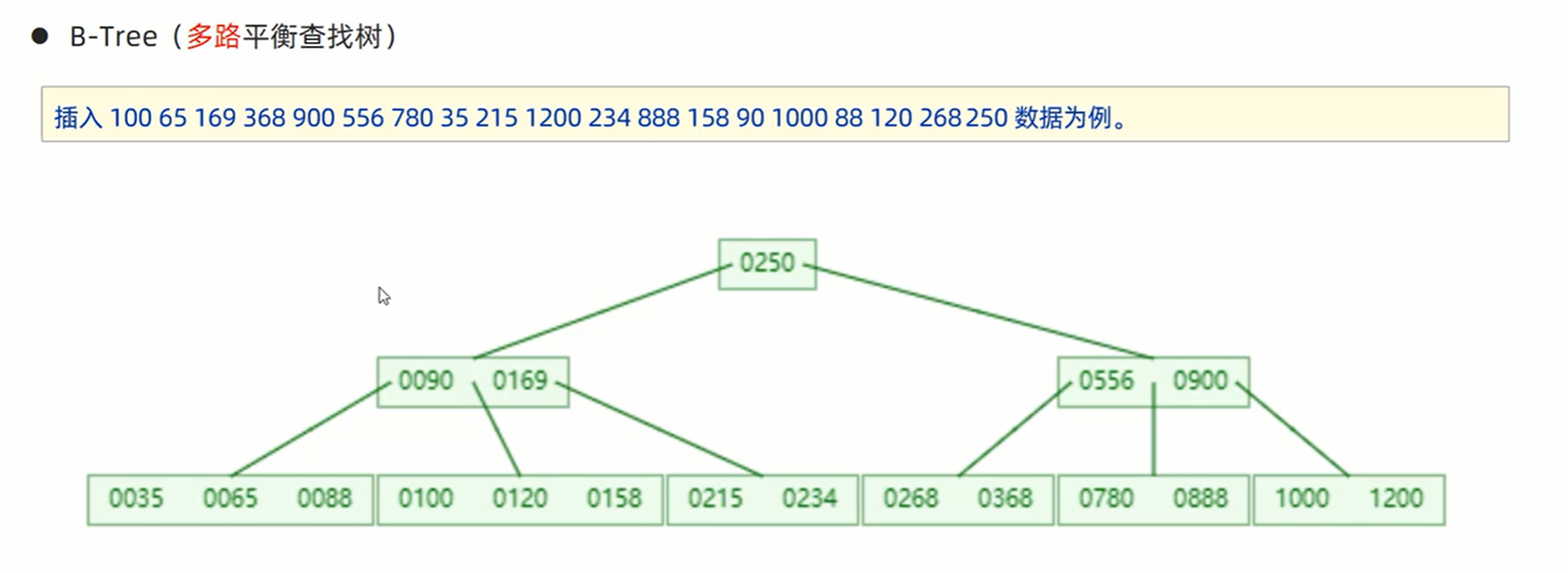
1、 B-TREE: 每个节点包含指定数量的node和指针,插入数据的时候从上往下查找,直到找到正确的层存储位置,插入node后如果本节点node的数量超过指定的数量,那么中间的node上移,循环上移直到树稳定。
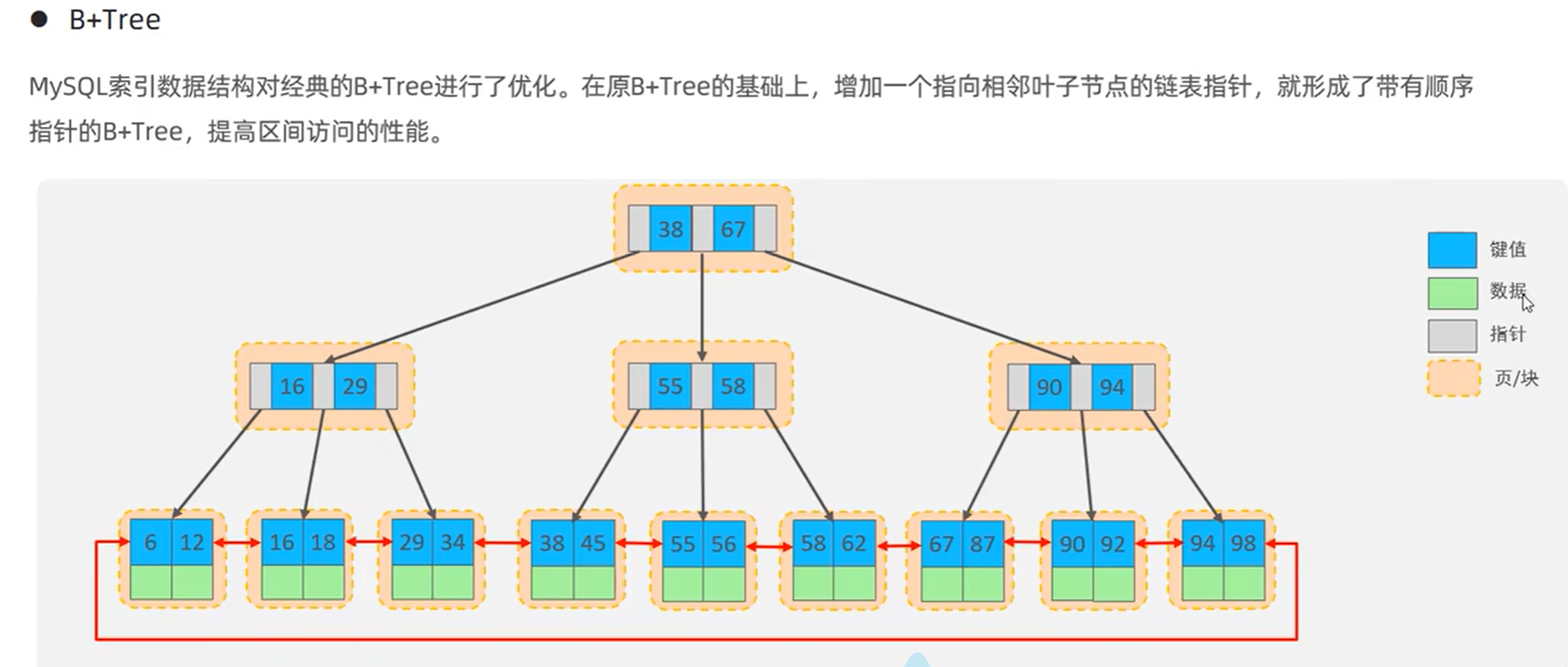
2、 B+TREE:

3、 MySql中的B+TREE:数据只存储在叶节点上,上层的节点只起到定位功能,不存储数据
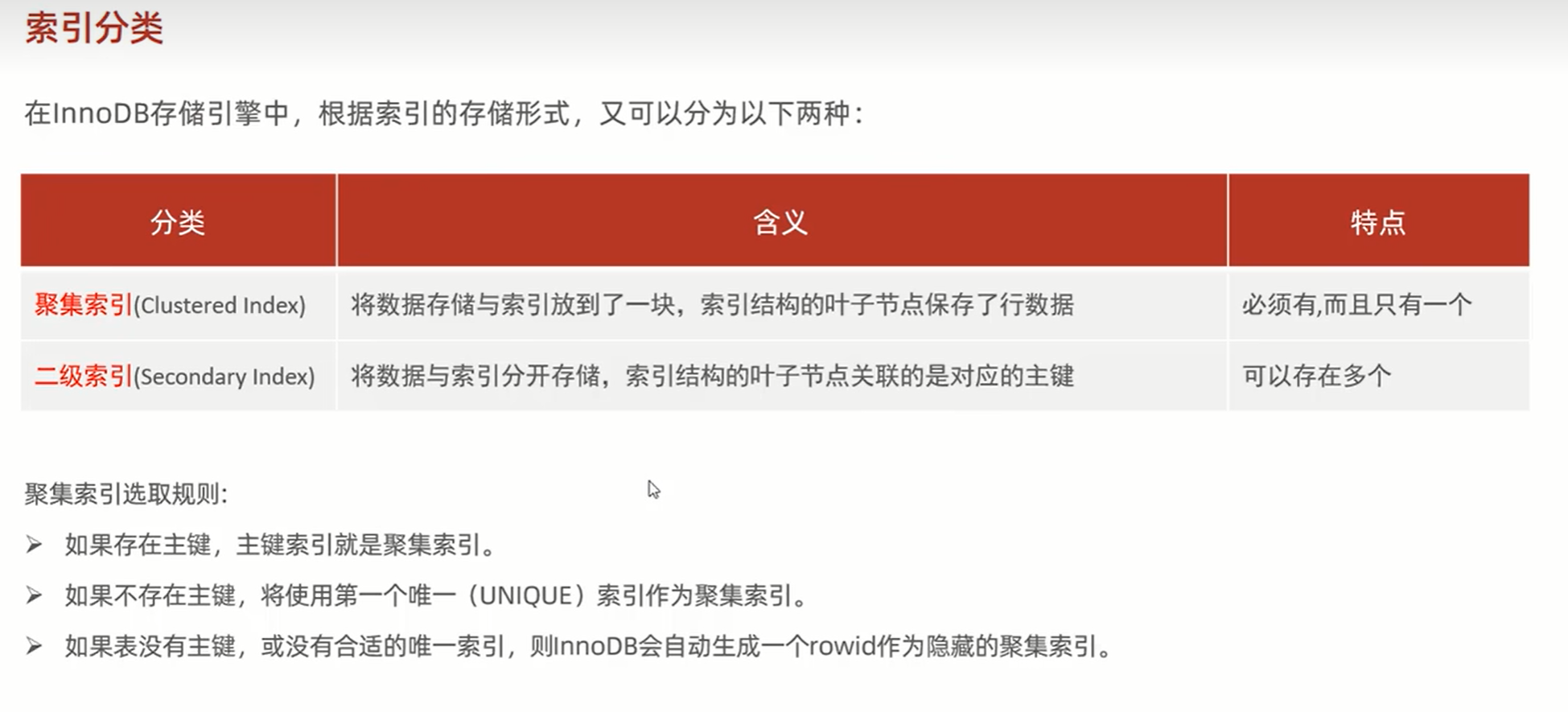
二、索引分类

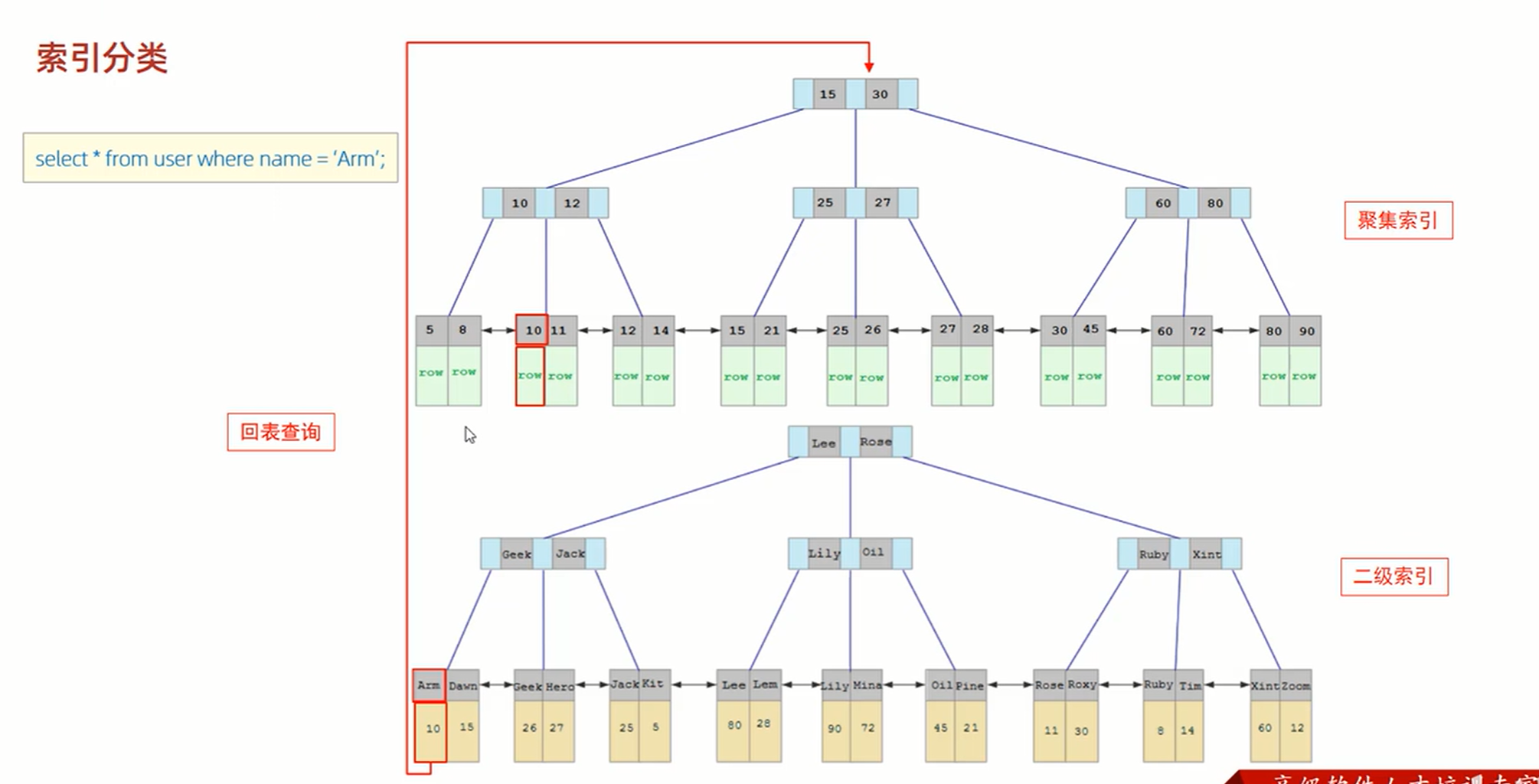
二级索引查找数据流程:根据二级索引找到聚集索引值,然后回表查询找到真正的数据
三、查看数据库性能和使用情况:
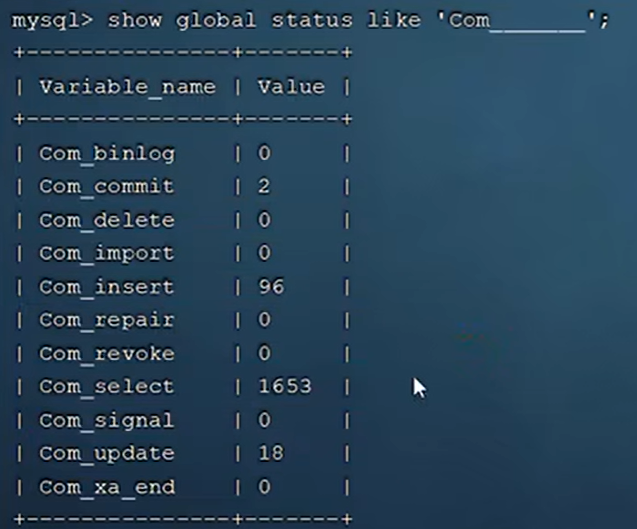
1. 慢查询: 查看当前数据库sql语句操作数量 show global status like 'Com_______';
查询慢查询日志(超过10秒): show variables like 'slow_query_log' ; 查看慢查询日志是否开启
开启慢查询日志: 修改 /etc/my.cnf
slow_query_log = 1 // 开启日志
long_query_time = 2 // 设置慢查询日志为2秒
2、 profiile详情: select @@have_profiling // 查看是否支持profile
set @@profiling = 1 // 开启profile
show PROFILES // 显示每条sql语句的耗时时间
show PROFILE for query 63 // 查看指定query_id 各阶段耗时
show PROFILE cpu for query 63 // 查看指定query_id 的sql语句的cpu使用情况
3、 explain执行计划:



四、 索引使用原则:
1、 最左前缀法则: 在使用联合索引的时候,查询从索引的最左测列开始,并且不跳过索引中间列。如果跳过某个中间列,索引将部分失效,即从跳过的字段开始后面的索引都失效。
2、 范围查询: 在使用联合索引的时候,出现范围查询(> < ),范围查询右侧的列索引失效。解决办法,使用 >= 和 <= .
3、 索引列运算: 不要在索引列上运算,否则列索引将失效。
4、字符串列:索引建在字符串上的时候,查询时要使用引号包含起来,不要发生隐式类型转换,否则索引失效。
5、 模糊查询: 如果只是尾部模糊匹配,索引仍然有效。如果是头部模糊匹配,索引失效。
6、 or连接的条件: or两侧的条件字段必须都有索引,两个索引才有效,只要有一个条件没有索引,那另一个条件的索引也将失效。
7、 数据分布影响:如果mysql评估使用索引比全表扫描还慢,则不使用索引。
8、 SQL提示: 在sql语句中加入一些人为的提示,来替代mysql自动选择使用的索引,来达到优化操作的目的。
use index: 建议使用哪个索引。 select * from c_cntr_siz_typ use index(udx_c_cntr_siz_typ) where cntr_siz_cod = '20' and cntr_typ_cod = 'GP';
ignore index: 建议不使用哪个索引。
force index: 必须用哪个索引。
9、 覆盖索引&回表查询:使用的二级索引中的字段,包含了select语句中的所有字段,就叫覆盖索引,这种情况下select中的数据能够从二级索引的叶子节点中直接读取。如果使用的二级索引没有包含selelct语句中的所有字段,那么还需要根据主键值从聚 集索引中。回表查询所需要的数据,这样就多了一次查询。
10、 前缀索引: 只将长字符串的前面一部分建立索引。使用前缀索引都要进行回表查询,因为二级索引的叶子节点上只存储了这个列的部分数据,回表查询出这个字段的全部值后和条件中的值进行比较,如果匹配则返回数据,不匹配的丢弃。然后在二级索引中继续查找看是否有满足前缀索引的值,直到二级索引的叶节点链表中出现不满足前缀索引的,查询结束。
11、 单列索引与联合索引: 推荐使用联合索引。
五、 索引设计原则:
1、 针对于数据量较大(10万行),且查询比较频繁的表建立索引。
2、 针对于常作为查询条件(where)、排序(orderby)、分组(group by)操作的字段建立索引。
3、 尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高。
4、 如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引。
5、 尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率
6、 要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率。
7、 如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它。当优化器知道每列是否包含NULL值时,它可以更好地确定哪个索引最有效地用于查询。
六、 其他SQL语句优化:
1、 插入数据优化:批量插入一次控制在1000条以内。手动控制事务。主键顺序插入。
load指令加载超大量数据。
mysql --local-infile -u root -p // shiyong --local-inlfile登录
set global local-infile = 1 // 开启load指令加载数据
load data local infile d:\data.sql into table table_name fields terminated by ',' lines terminated by '\n'; //load data.sql文件的数据进数据库, 字段已 ','分割,行已'\n'分割。
2、 主键优化:
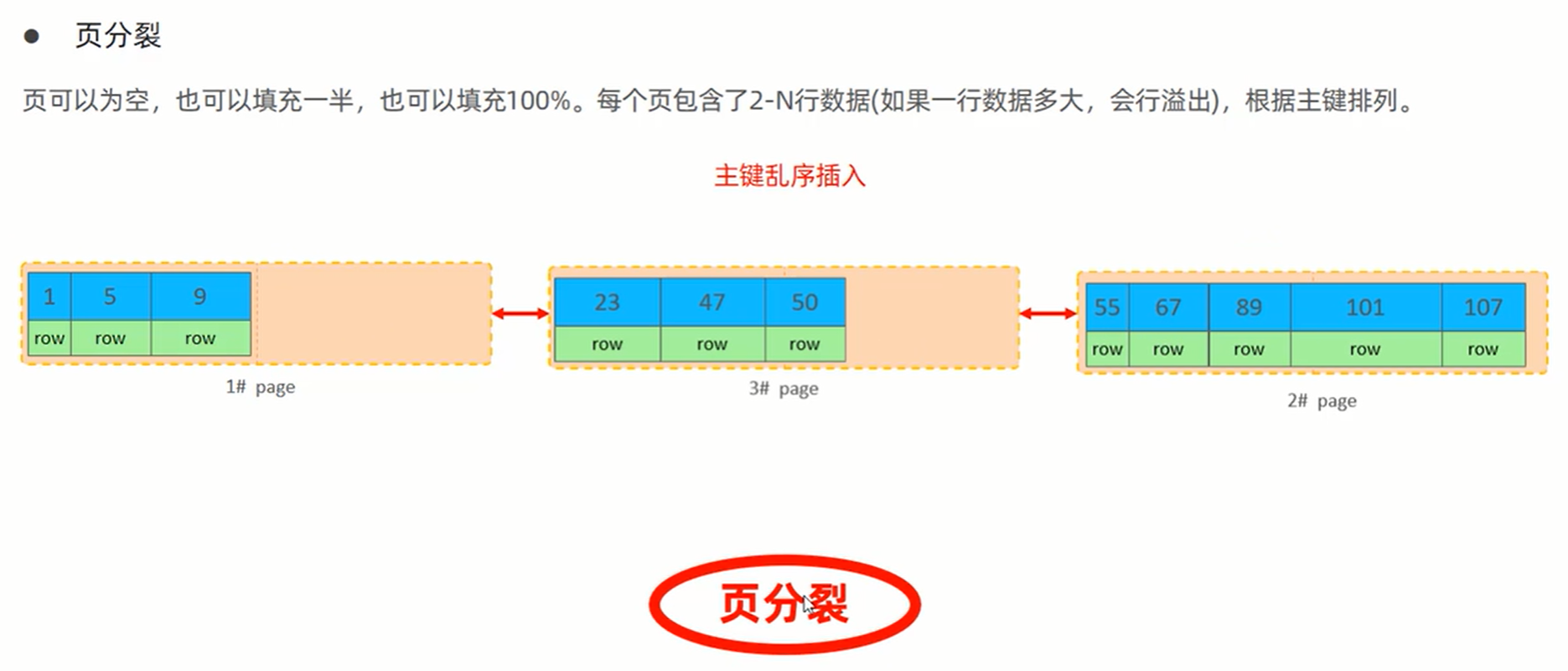
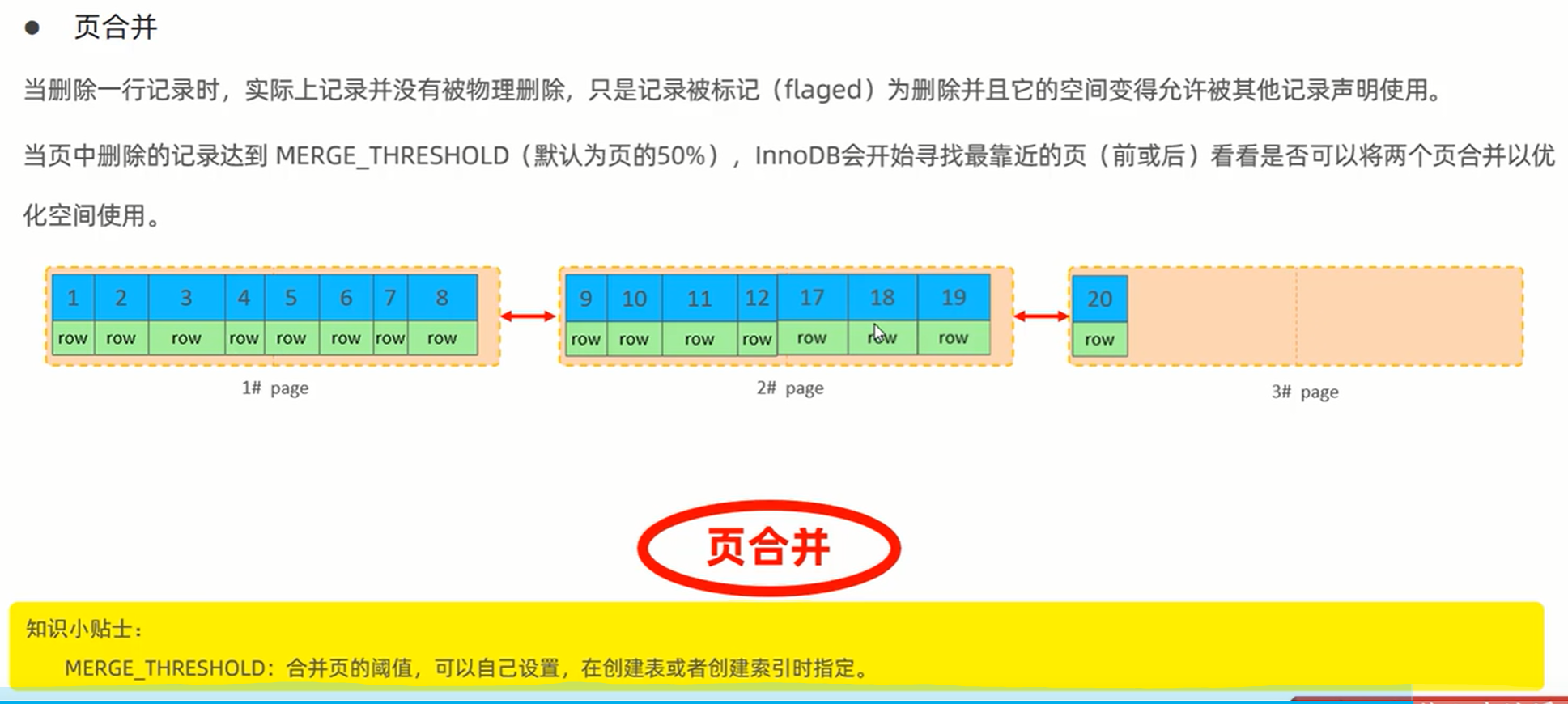
主键设计原则: 尽量降低主键长度,插入数据数据时尽量顺序插入,主键尽量是auto_increment自增主键。不要修改主键

3、 order by 优化:


4、 group by 优化:同 order by
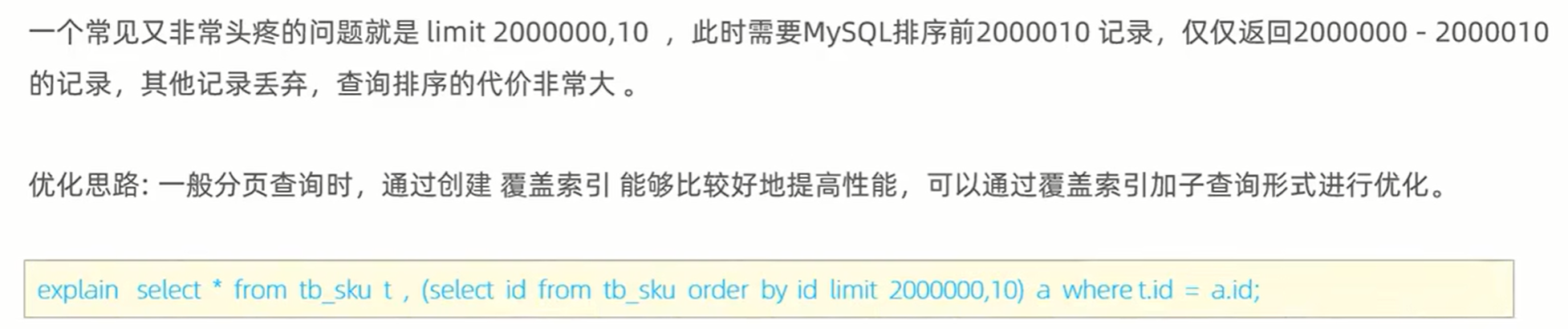
5、 limit 优化:
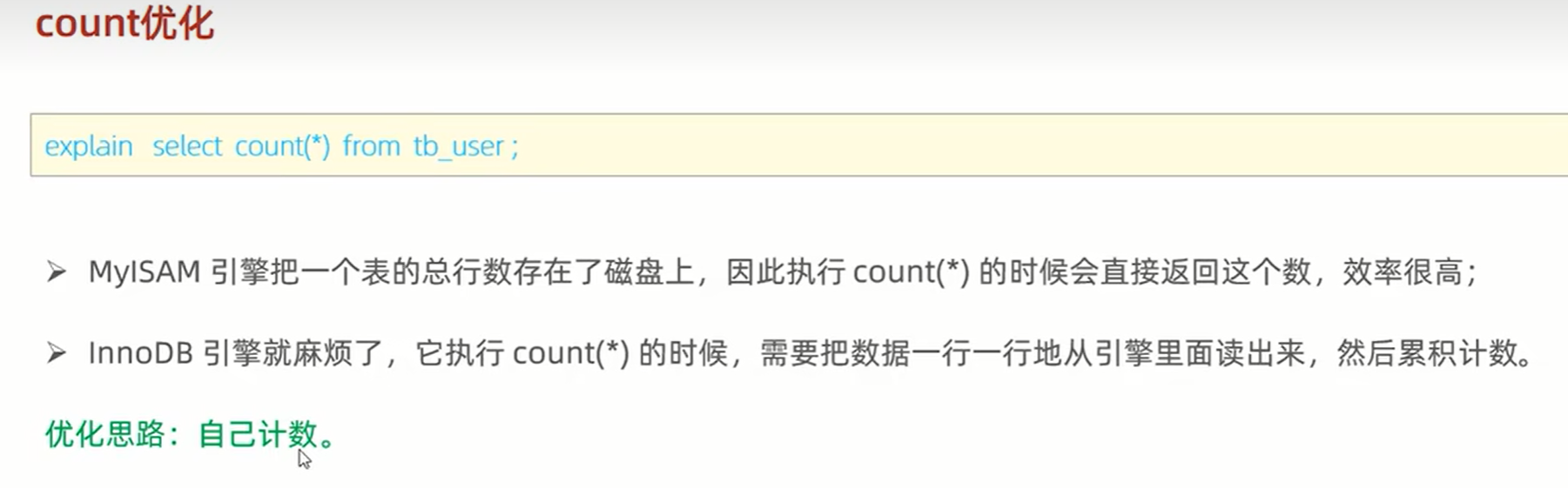
6、 count优化:使用count(*) ,性能最佳
7、 update 优化:update的时候要根据索引字段进行更新,否则就会锁表。

七、 视图: with cascaded check option 开启视图在增、删、改的时候进行条件检查

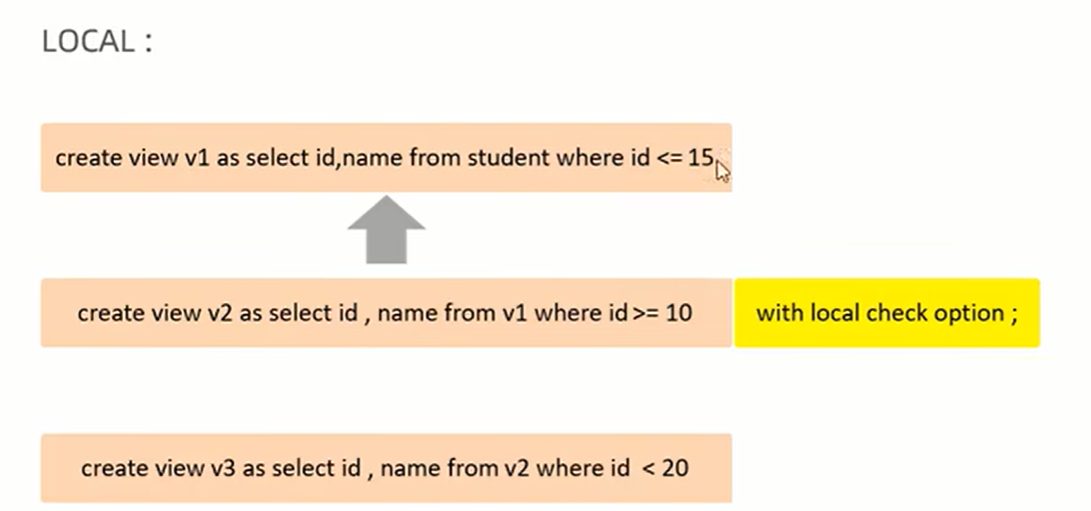
1、 视图更新:

八、 存储过程:
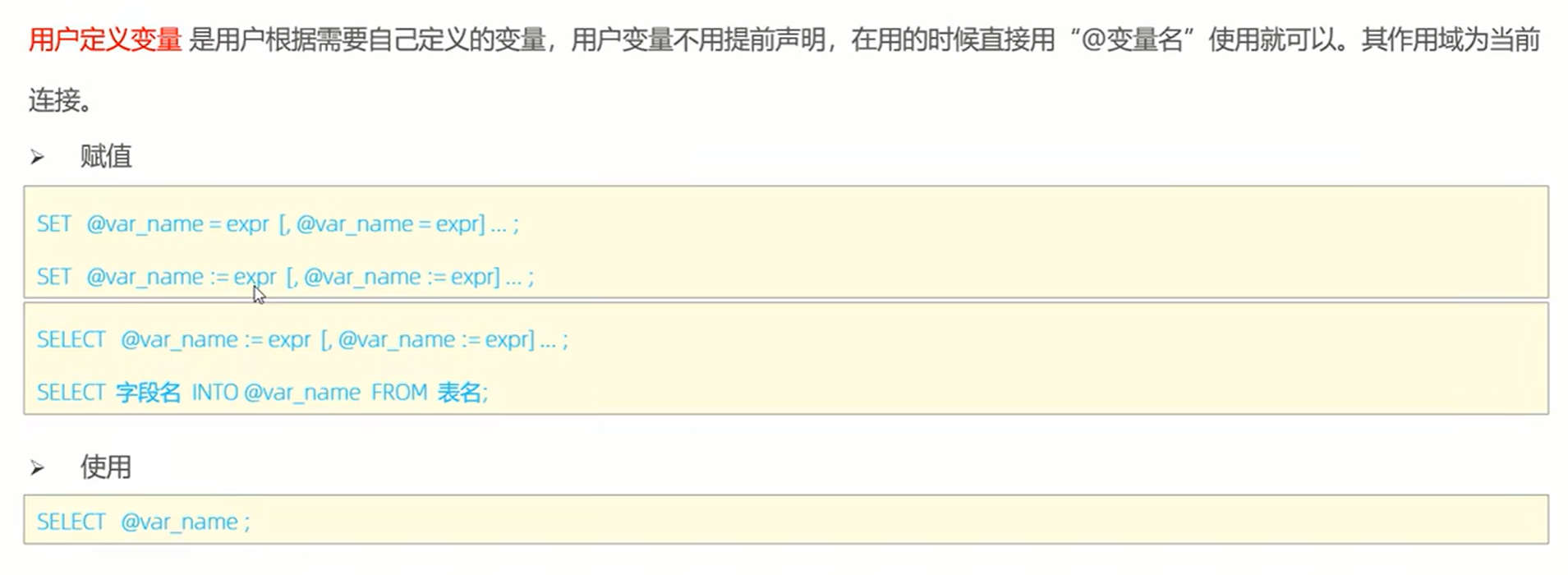
1、 变量: @@系统变量 @自定义变量
select @@global.local_infile // 查看系统变量


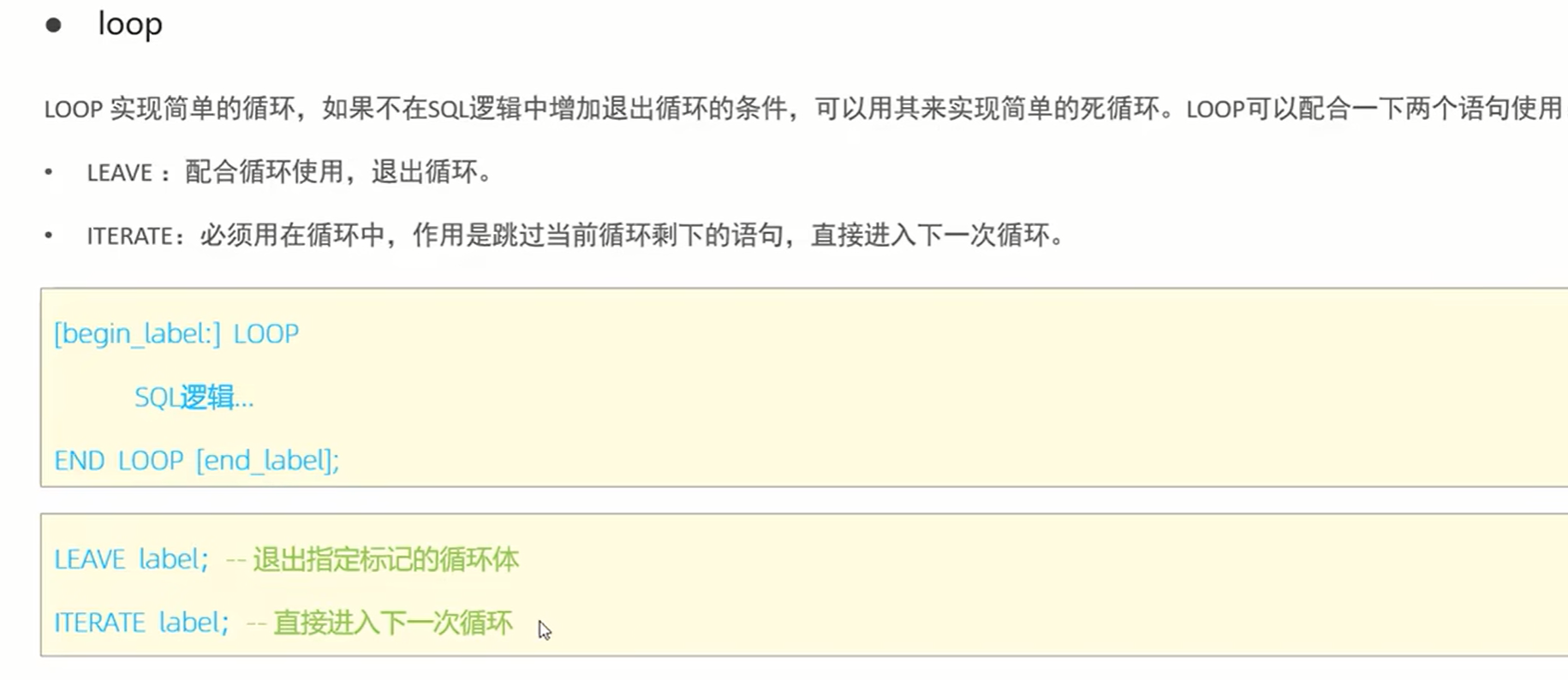
2、 loop循环:
3、 游标(cursor):

3、 条件处理程序:

4、 函数:

九、 锁
1、全局锁: 导数据库时使用:
flush tables with read lock; // 加锁
mysqldump -h主机 -uroot -p密码 数据库名 > sql.dmp // 备份数据库 mysqldump --single-transaction -h主机 -uroot -p密码 数据库名 > sql.dmp // 不加锁备份
unlock tables; //解锁
2、表级锁:
表锁:
表共享读锁: read lock // 加读锁后,所有客户端只能读不能写
表独占写锁: write lock // 加写锁后,加锁的客户端可读可写,其他客户端既不能读也不能写
语法: lock tables 表名... read/write ; // 加锁
unlock tables // 解锁
元数据锁(meta data lock) MDL: 表结构锁,表有事务活动的时候,表结构不能修改。


意向锁: 用于在加表锁的时候,方便对行锁进行判断,来快速决定表锁能不能锁定。
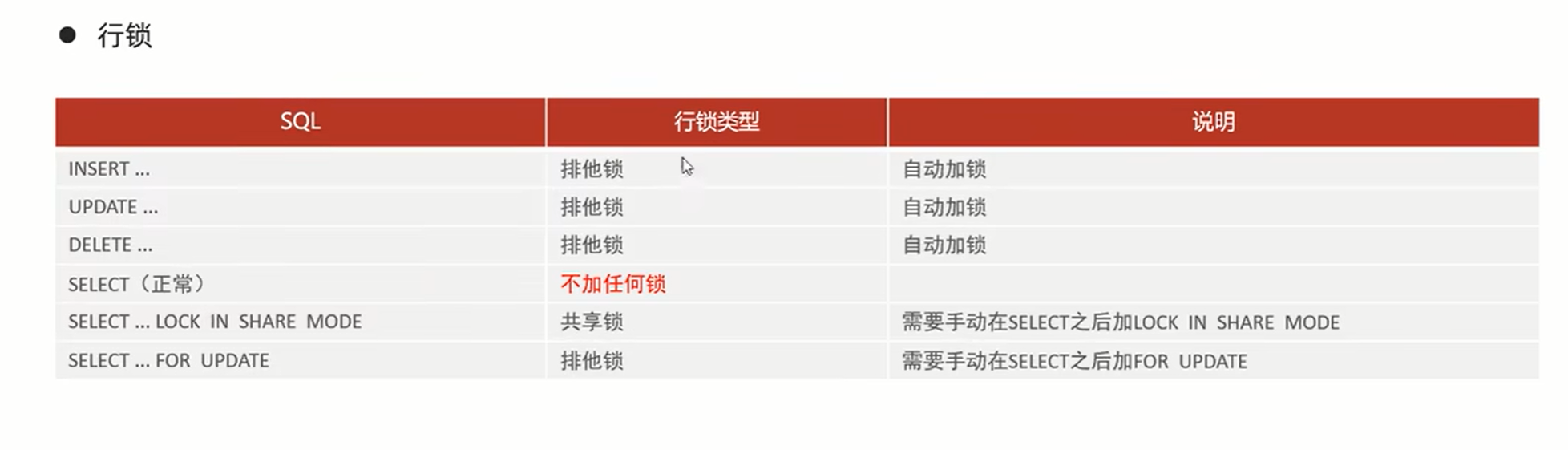
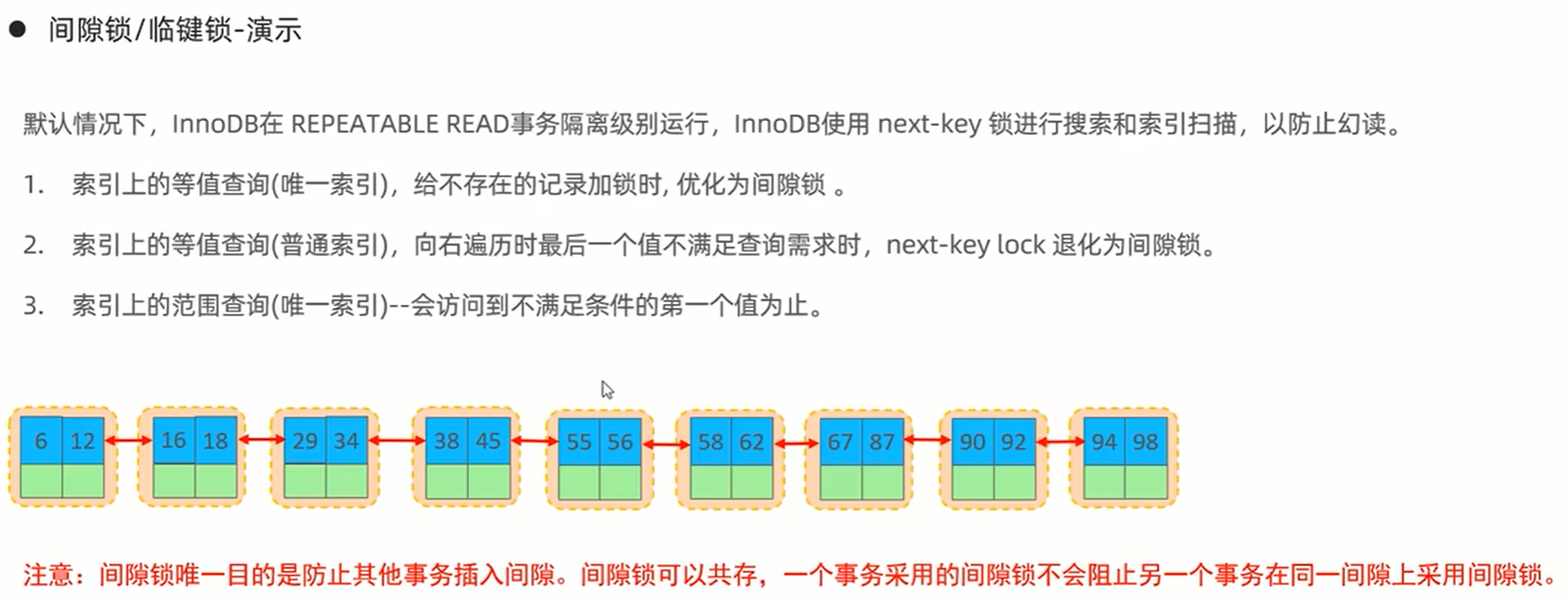
3、 行级锁:

行锁:


十、 innodb引擎:
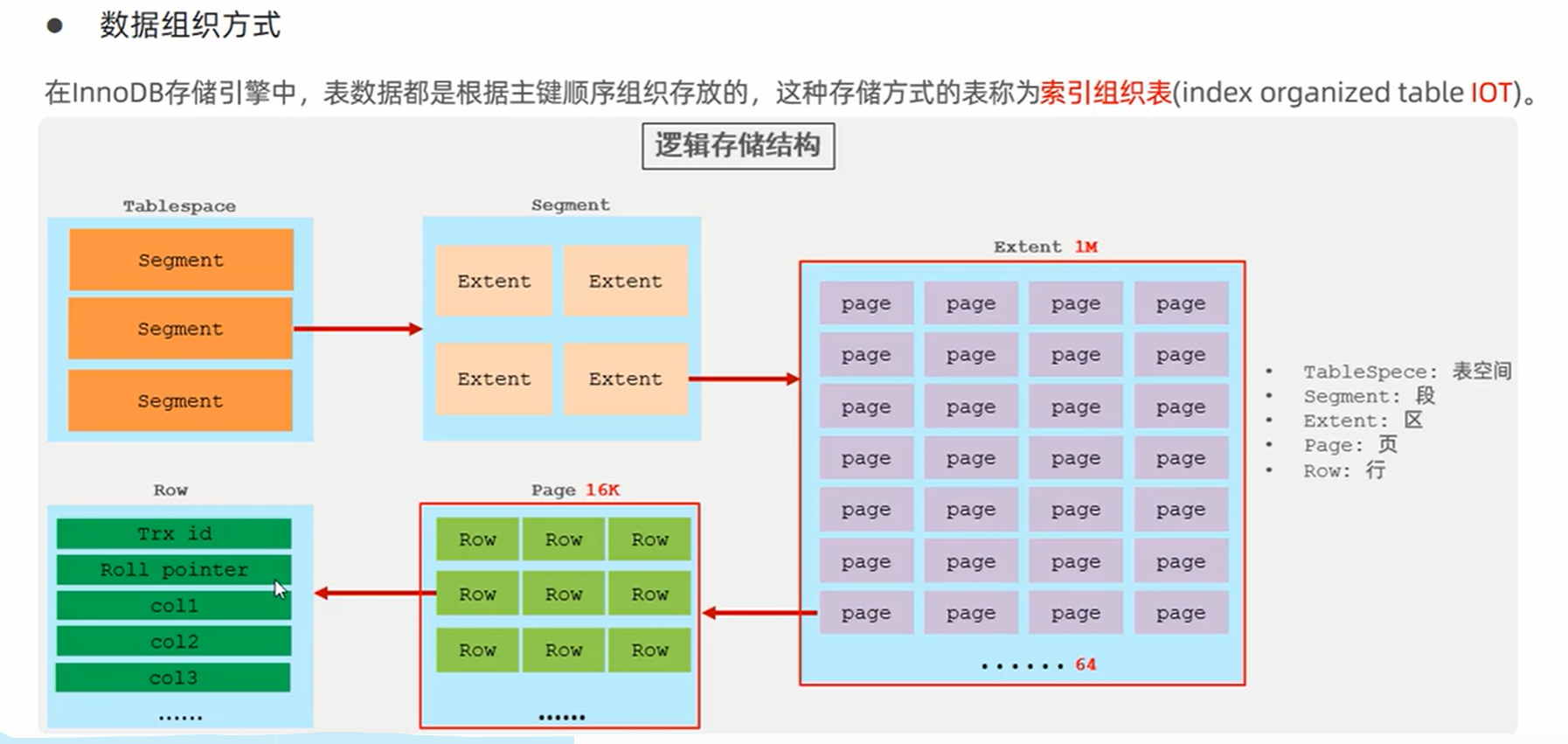
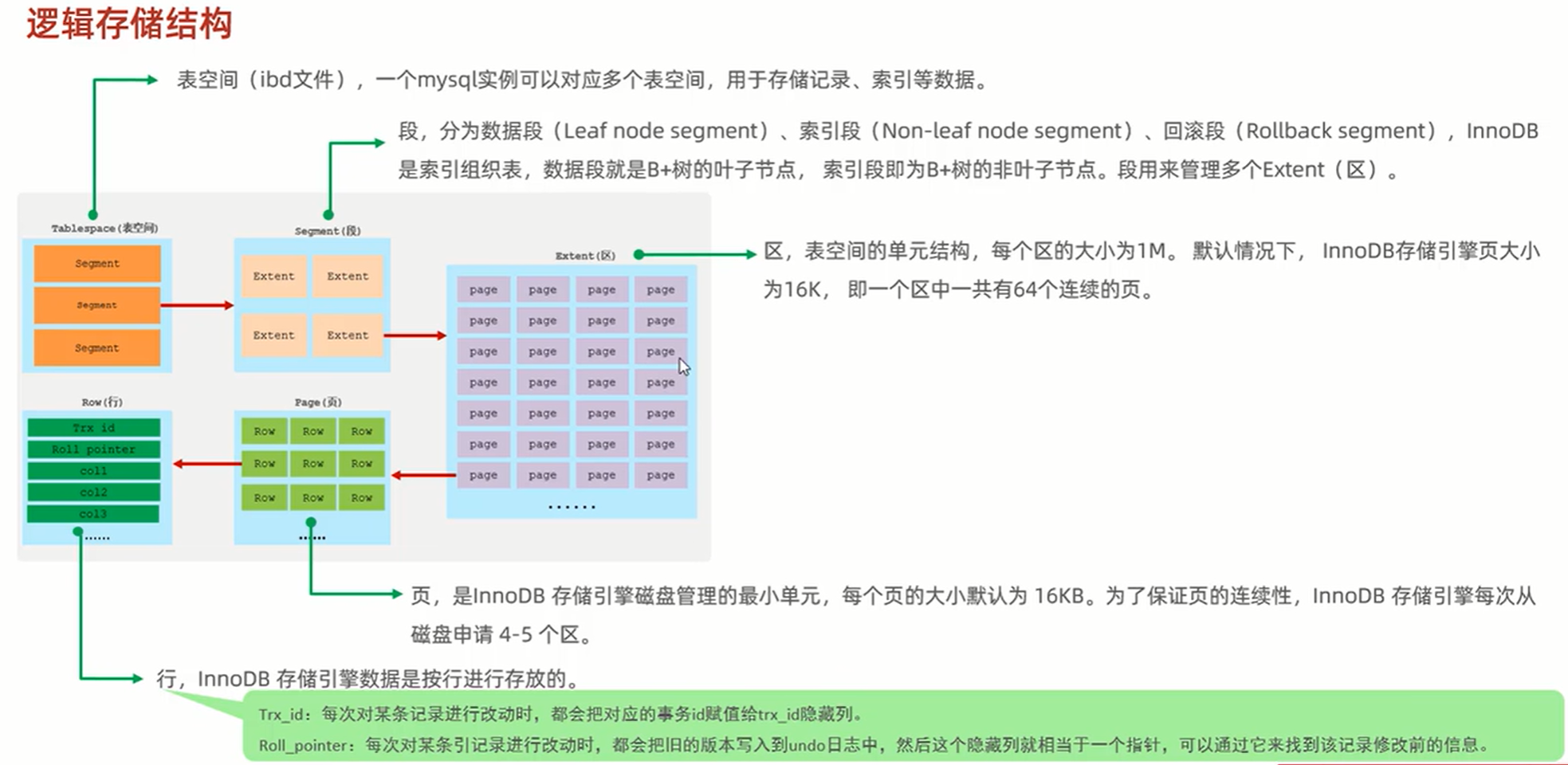
1、 逻辑存储结构:
2、 架构:

内存结构:
buffer pool:

change buffer:

adaptive hash index:

log buffer:
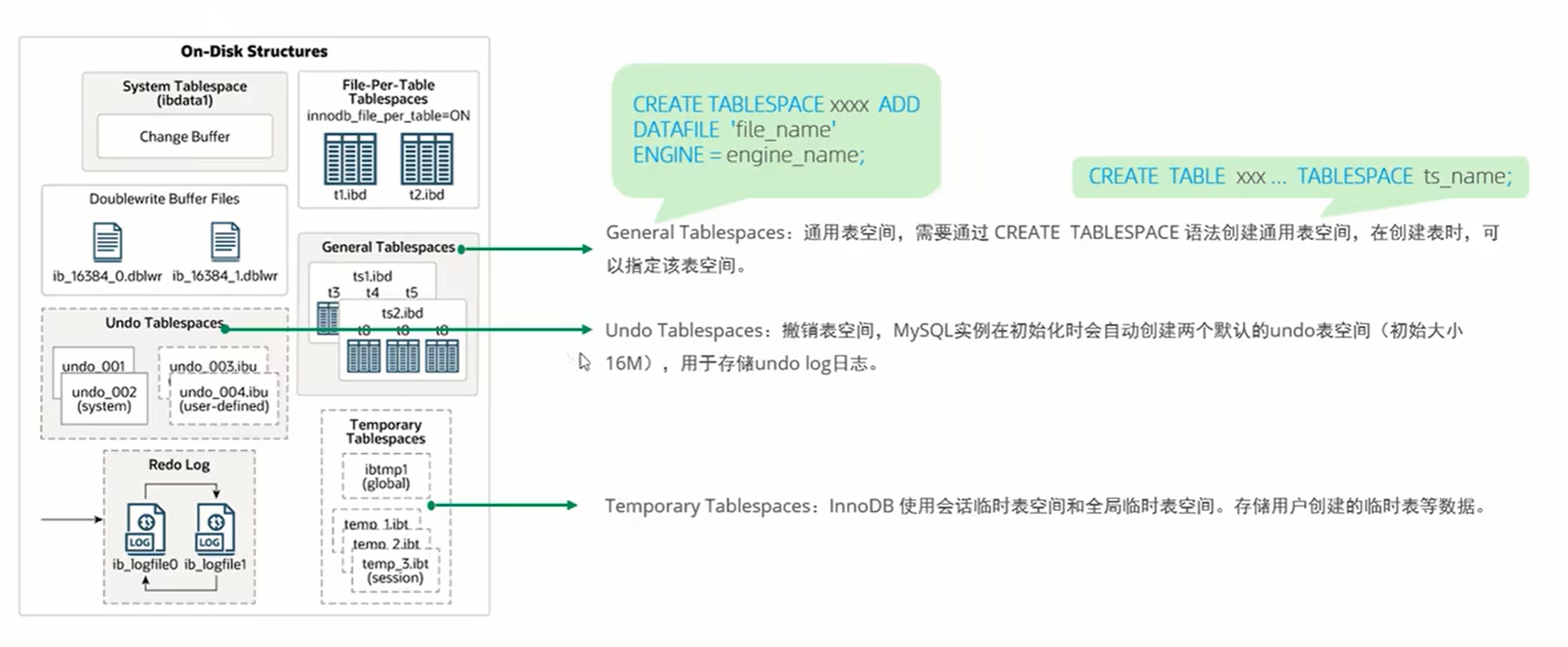
 磁盘结构:
磁盘结构:


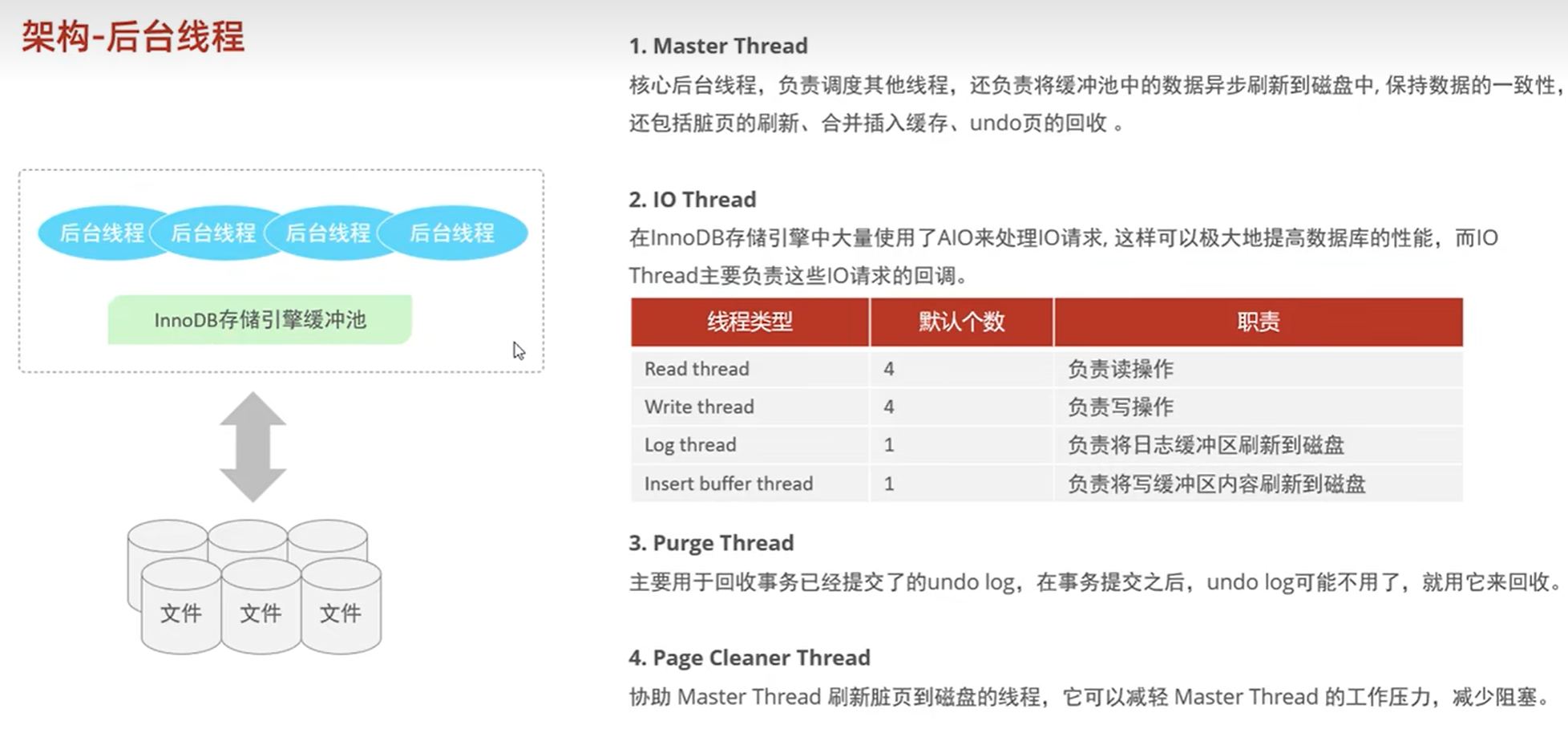
后台线程:
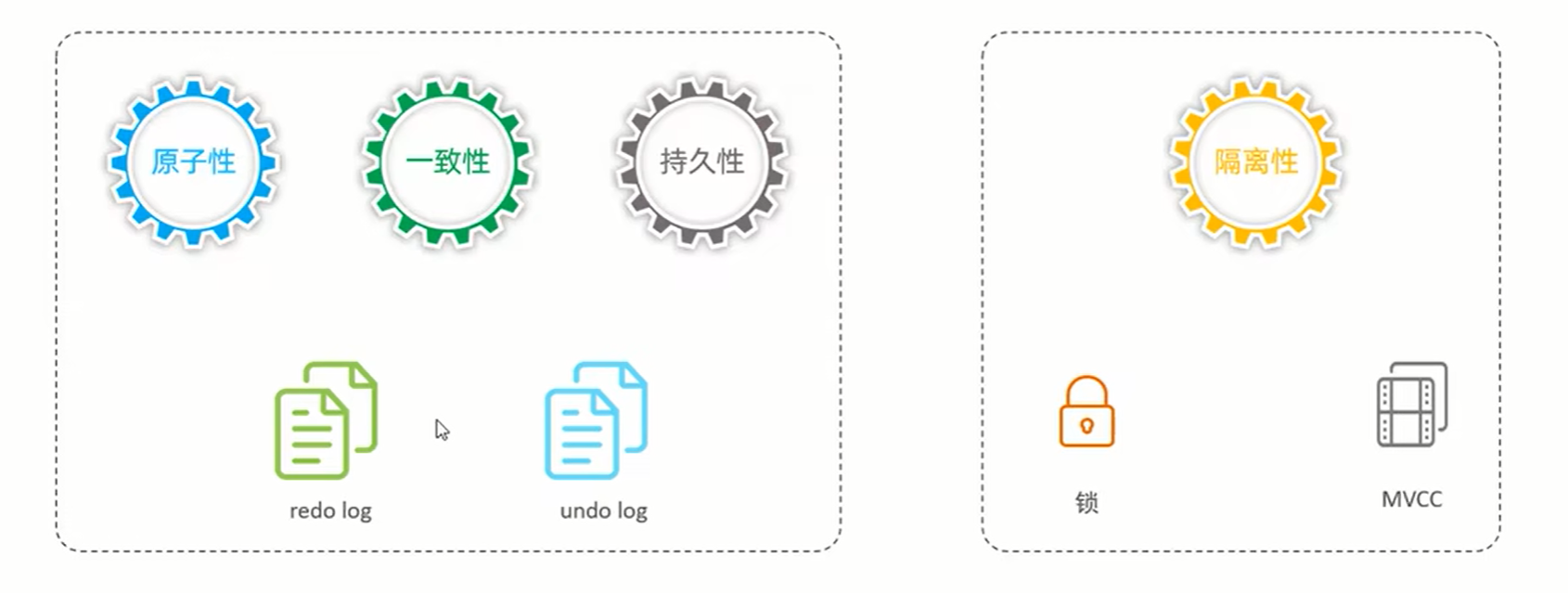
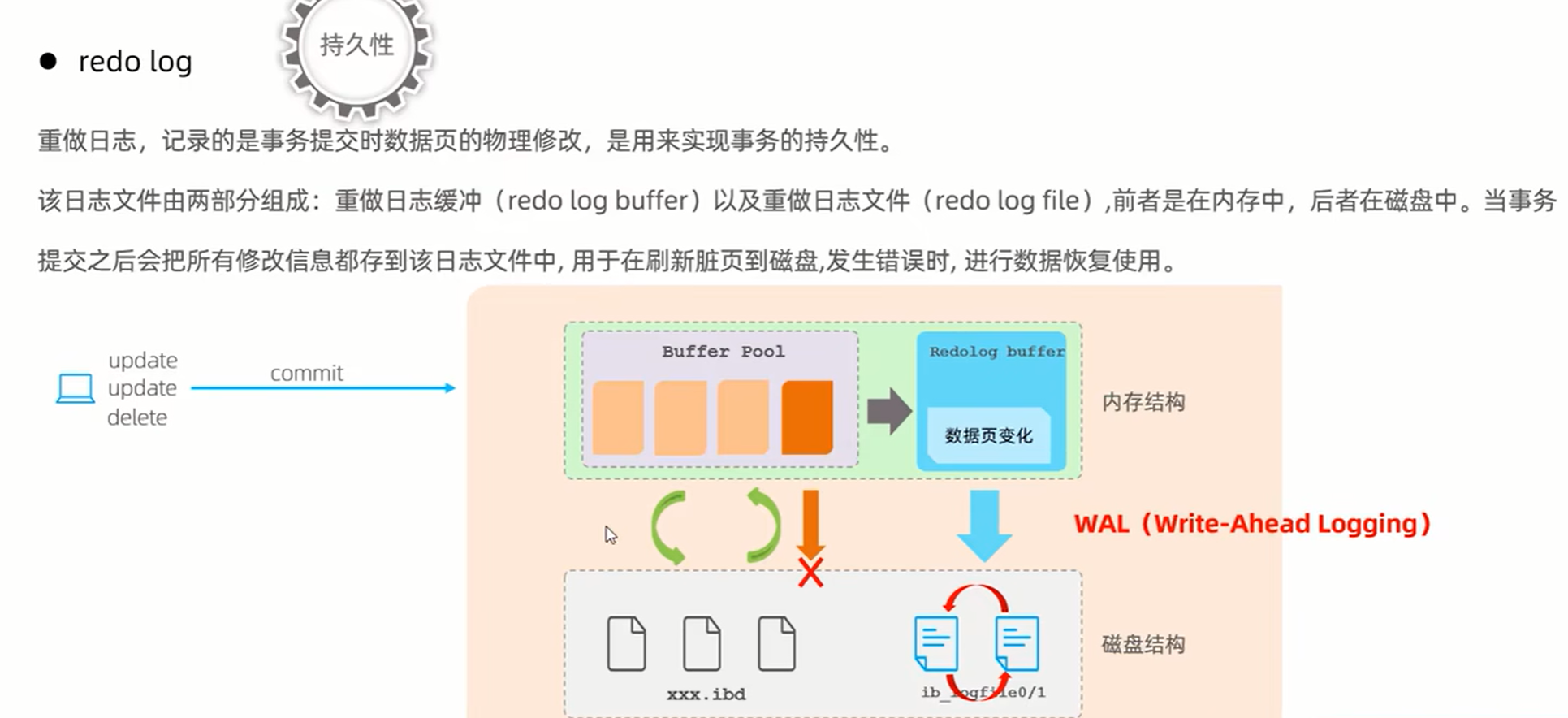
3、事务原理:


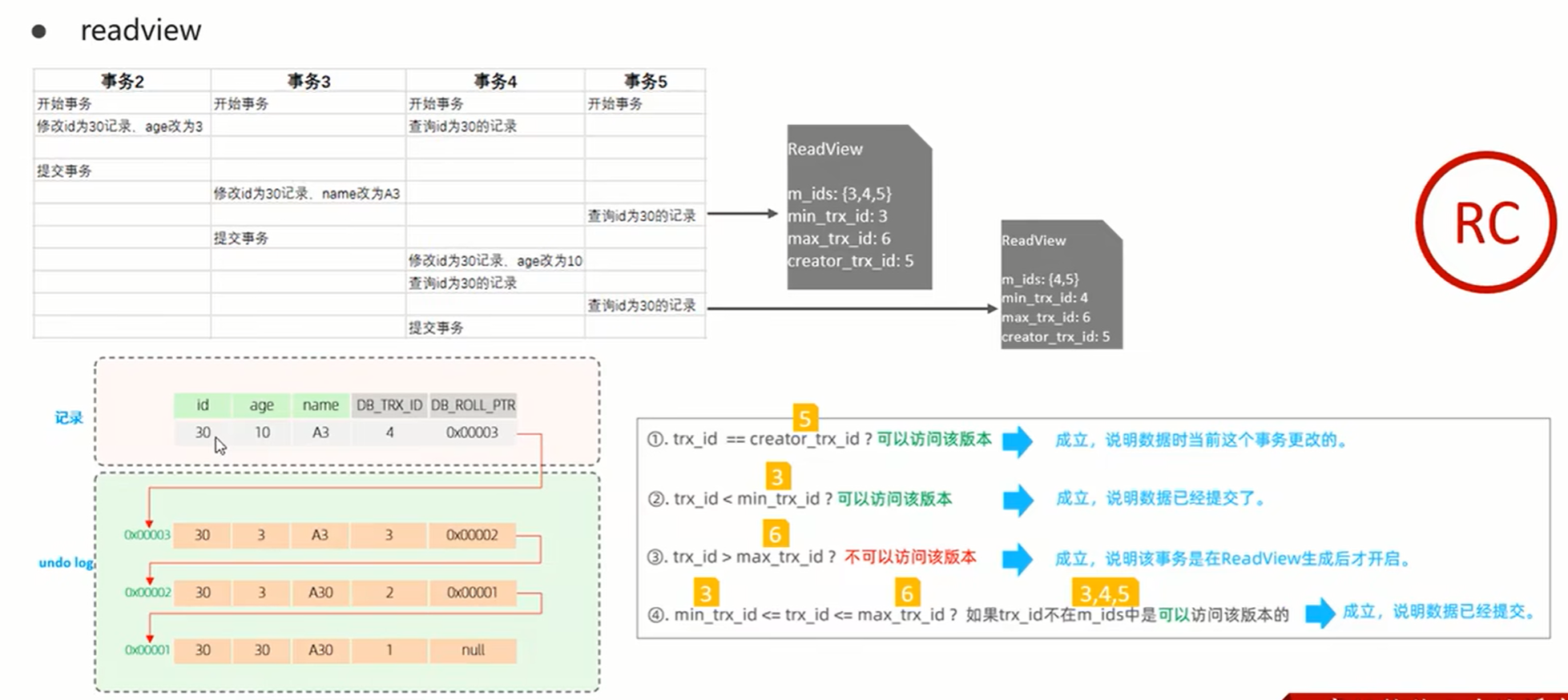
4、 MVCC: 多版本并发控制







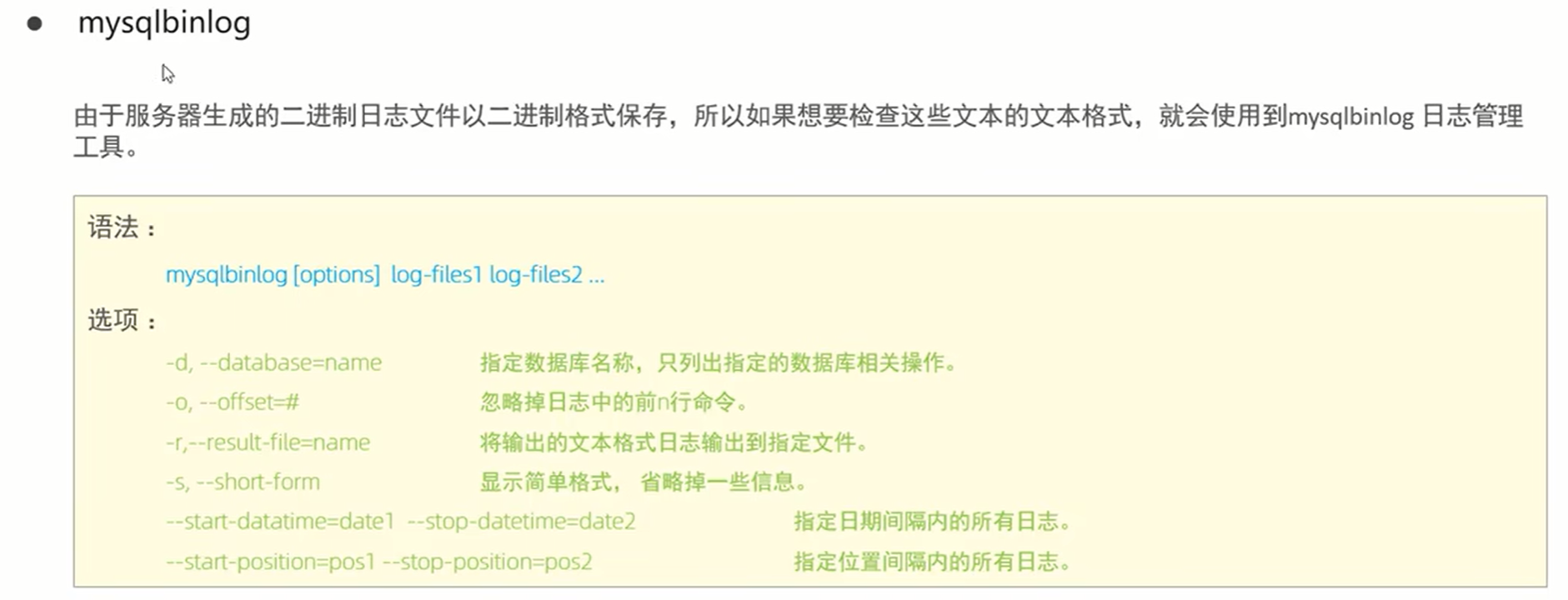
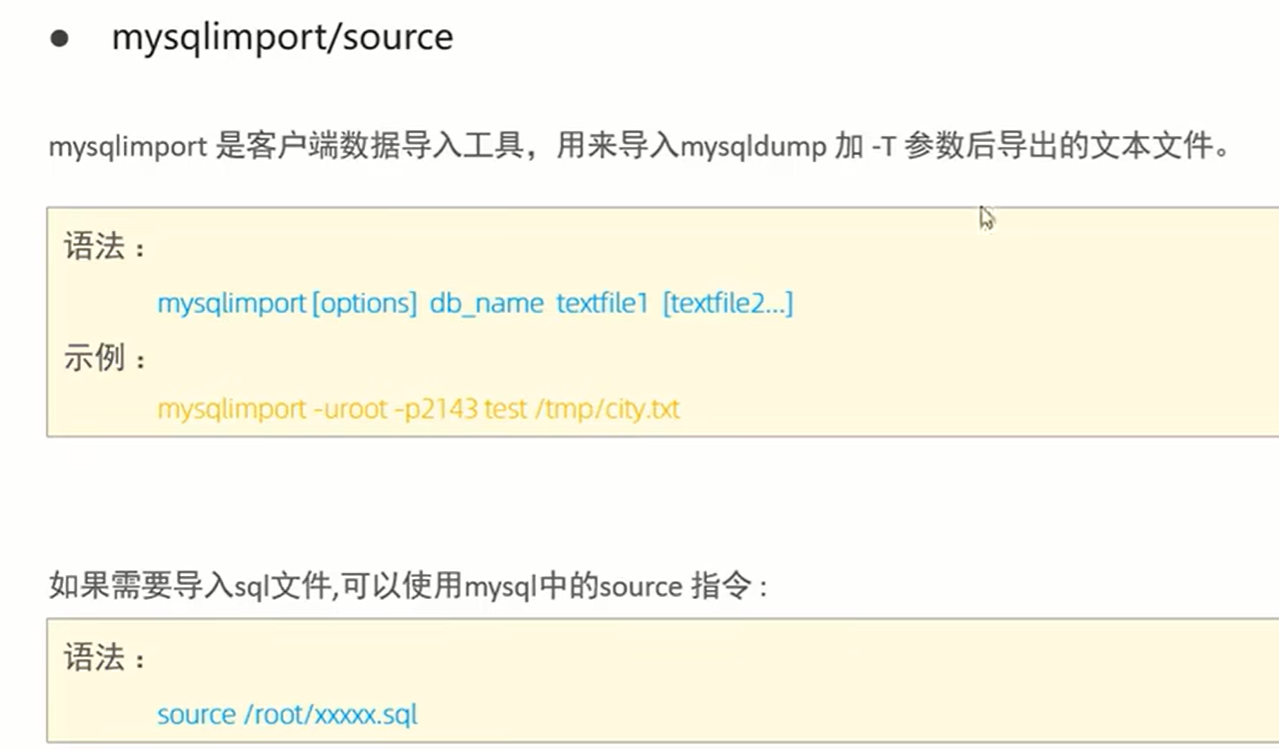
十一、 MySql管理


十二、 日志
1、 错误日志
show variables like "%log_error%"
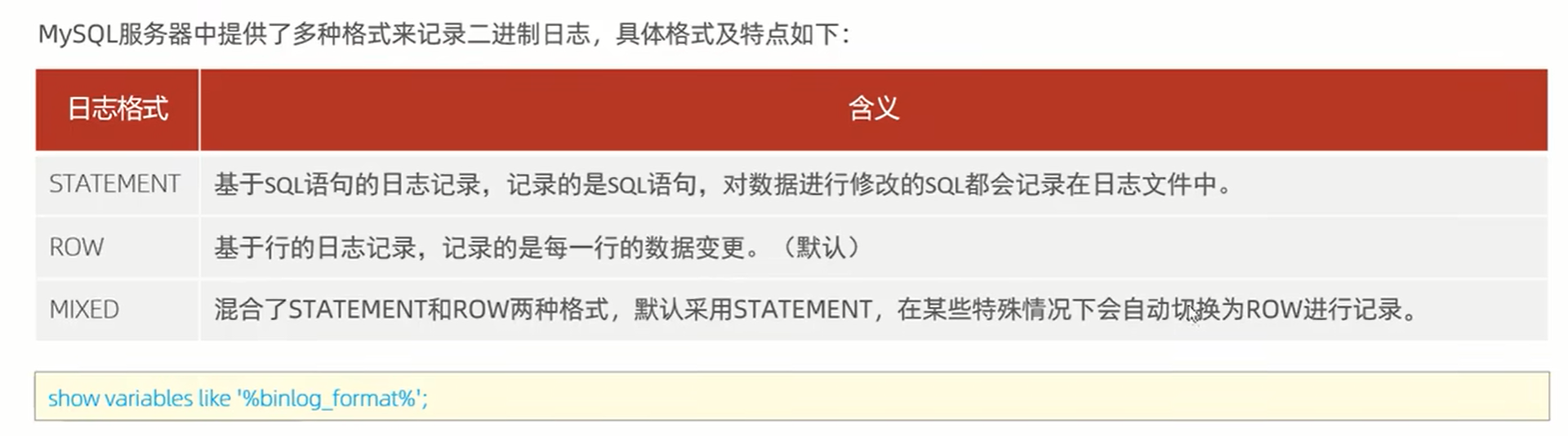
2、 二进制日志



3、 查询日志

4、 慢查询日志

十二、 主从复制:将主数据库的二进制日志文件传到从数据库上执行,实现主从同步。
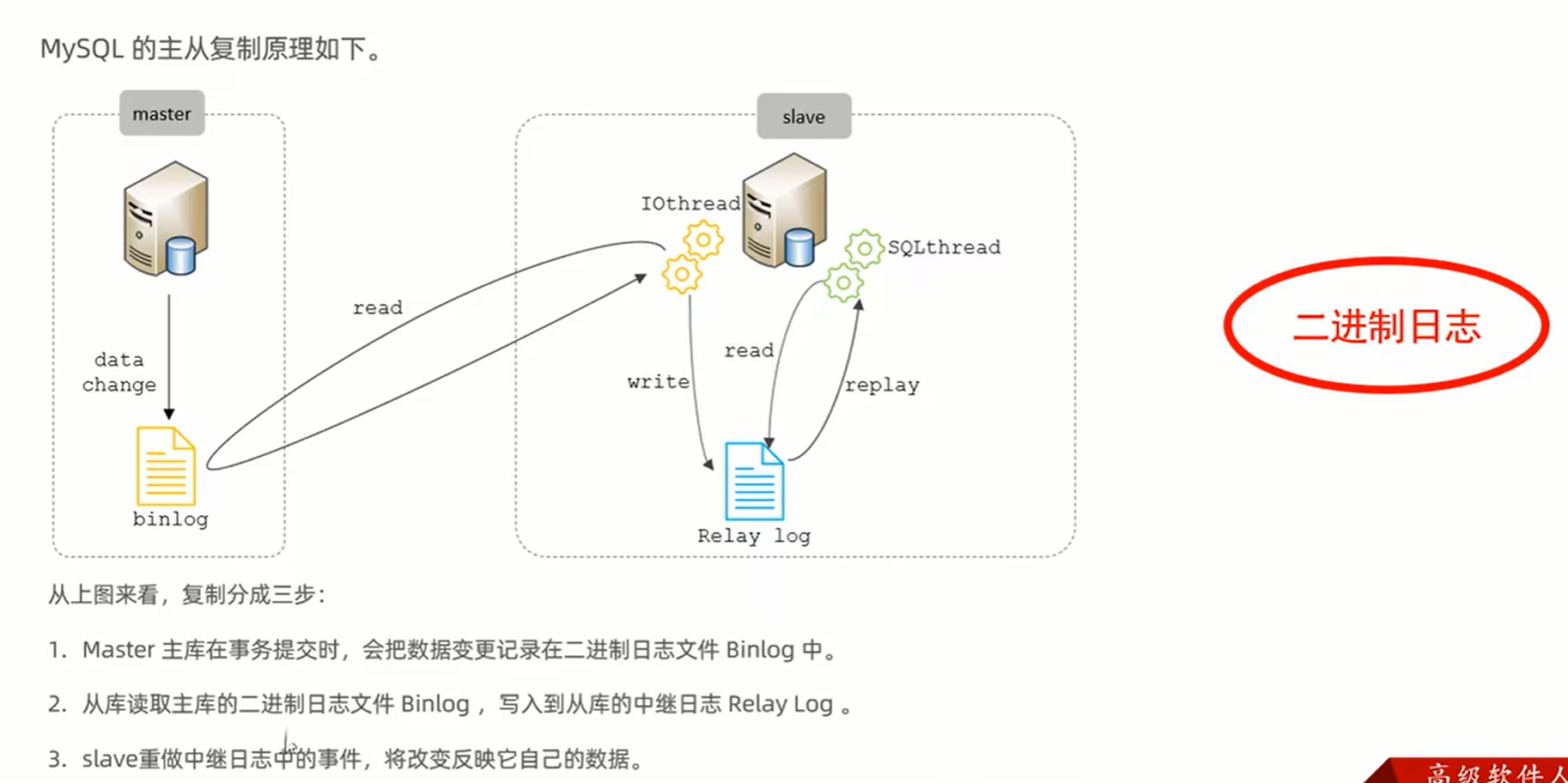
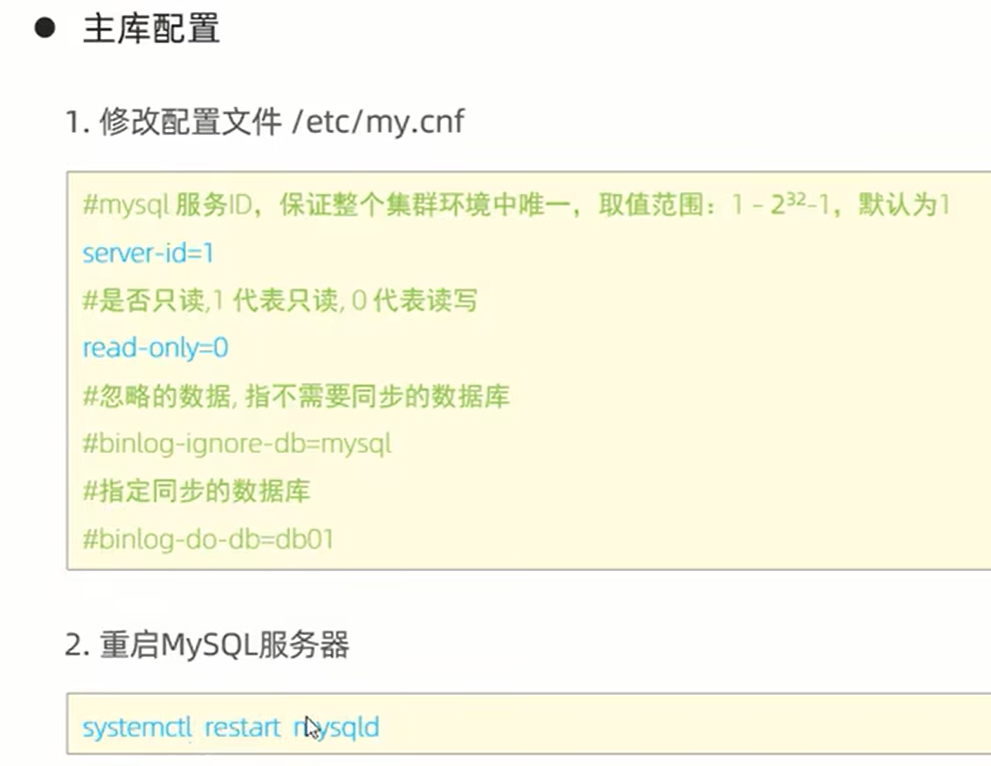




十三、 分库分表
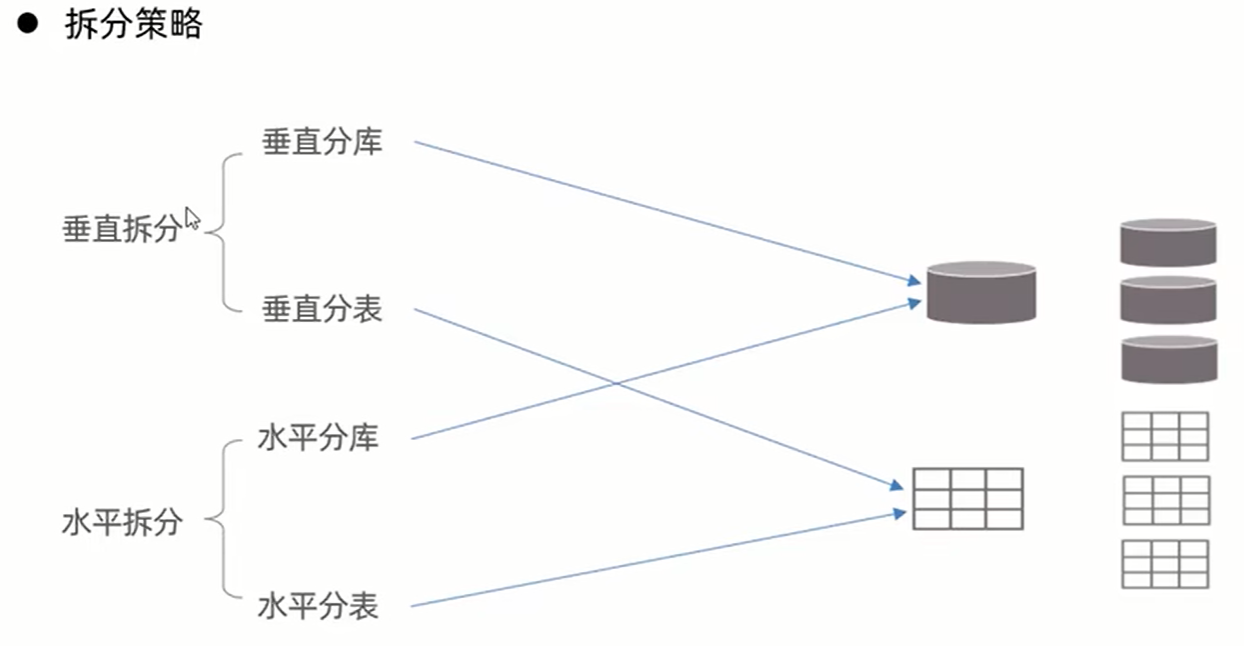
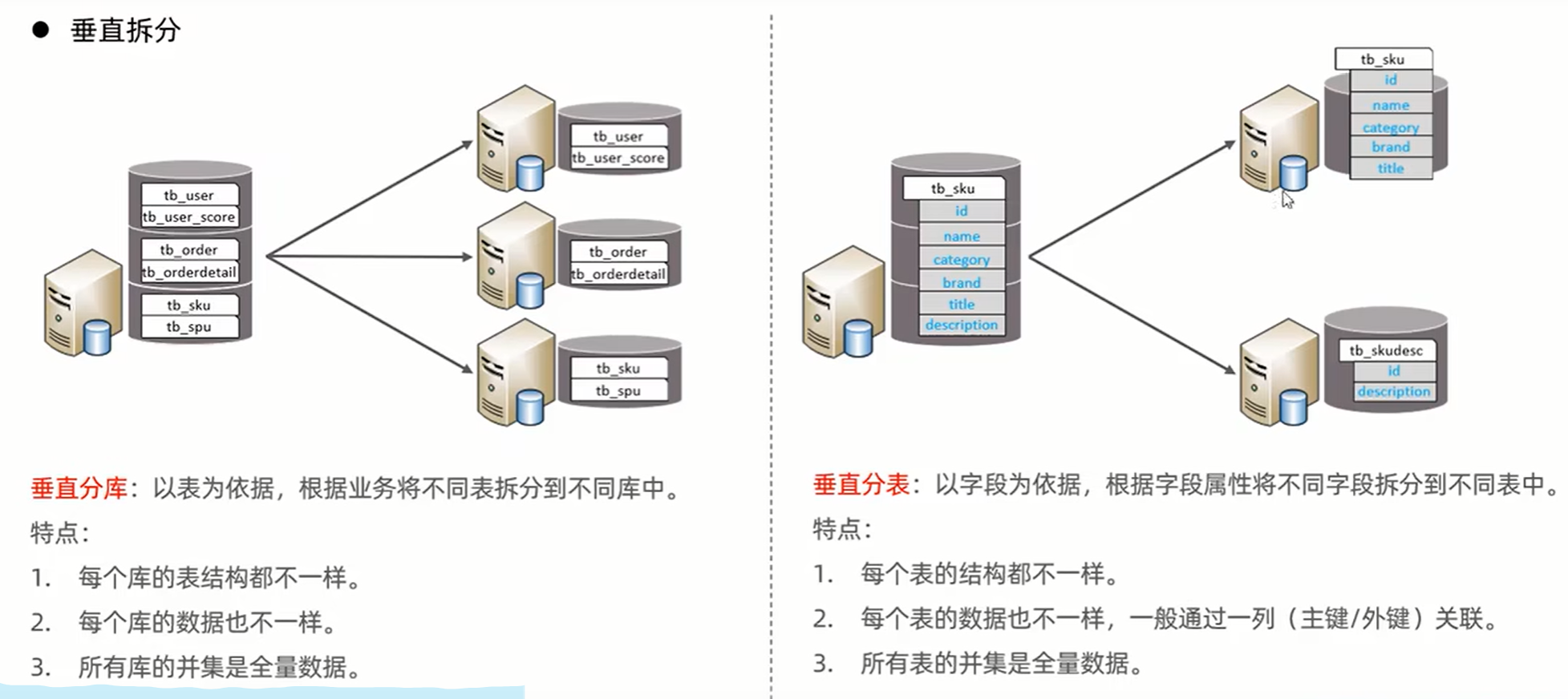

十四、 MyCat
1、 介绍
十五、 读写分离:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号