02.WebMagic
1.WebMagic介绍
架构介绍
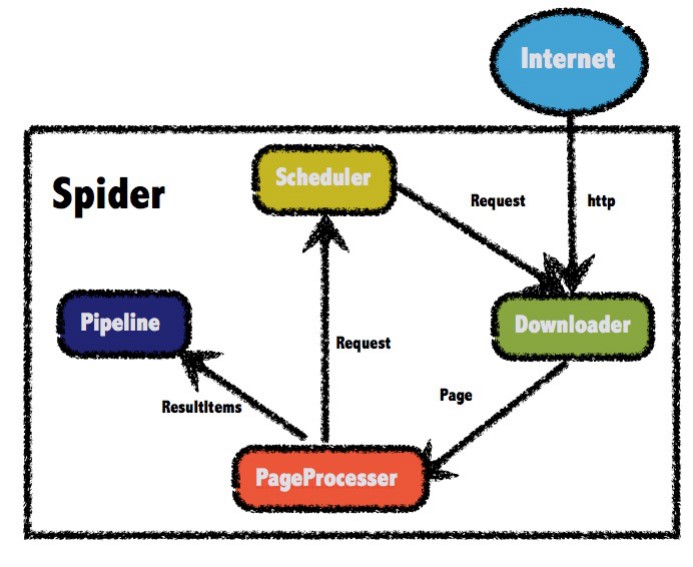
WebMagic的四个组件
- Downloader
- PageProcessor
- Scheduler
- Pipeline
用于数据流转的对象
- Request
- Page
- ResultItems
2.快速入门
<!--WebMagic-->
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.4</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.4</version>
</dependency>- 1.所以直接用0.7.4版本
- 2.直接从github上下载最新的代码,安装到本地仓库
log4j.rootLogger=INFO,A1
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c]-[%p] %m%npublic class JobProcessor implements PageProcessor {
//解析页面
public void process(Page page) {
//解析返回的数据page,并且把解析的结果放到ResultItems中
//css选择器
page.putField("div", page.getHtml().css("div.mt h2").all());
}
private Site site = Site.me()
.setCharset("utf8");//设置编码
public Site getSite() {
return site;
}
//主函数,执行爬虫
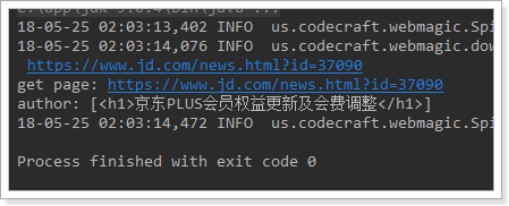
public static void main(String[] args) {
Spider spider = Spider.create(new JobProcessor())
.addUrl("https://www.jd.com/moreSubject.aspx")//设置爬取数据的页面
.run();
}
}
3.WebMagic功能
实现PageProcessor
抽取元素Selectable
page.getHtml().xpath("//div[@class=mt]/h1/text()")page.getHtml().css("div.mt>h1").toString()page.getHtml().css("div#news_div > ul > li:nth-child(1) a").toString()//正则表达式 获取 有江苏的元素element
page.putField("div3", page.getHtml().css("div#news_div a").regex(".*江苏.*").all());抽取元素API
方法 | 说明 | 示例 | 方法 | 说明 |
xpath(String xpath) | 使用XPath选择 | html.xpath("//div[@class='title']") | xpath(String xpath) | 使用XPath选择 |
$(String selector) | 使用Css选择器选择 | html.$("div.title") | $(String selector) | 使用Css选择器选择 |
$(String selector,String attr) | 使用Css选择器选择 | html.$("div.title","text") | $(String selector,String attr) | 使用Css选择器选择 |
css(String selector) | 功能同$(),使用Css选择器选择 | html.css("div.title") | css(String selector) | 功能同$(),使用Css选择器选择 |
links() | 选择所有链接 | html.links() | links() | 选择元素的所有链接 |
regex(String regex) | 使用正则表达式抽取 | html.regex("\(.\*?)\") | regex(String regex) | 使用正则表达式抽取 |
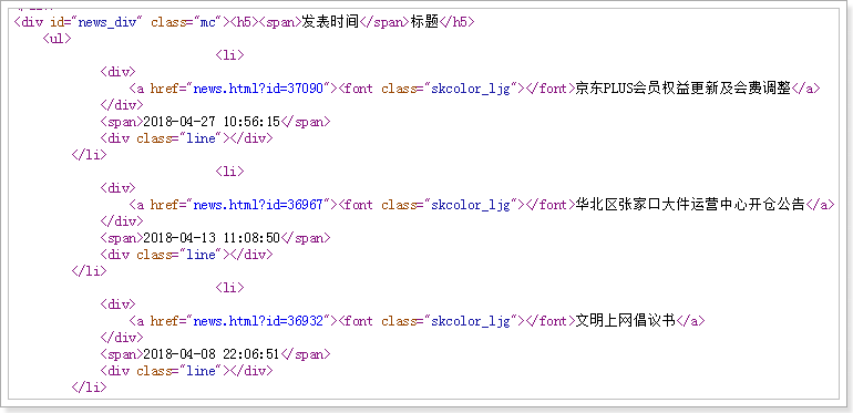
//先获取class为news_div的div
//再获取里面的所有包含文明的元素
List<String> list = page.getHtml()
.css("div#news_div")
.regex(".*文明.*").all();获取结果API
方法 | 说明 | 示例 |
get() | 返回一条String类型的结果 | String link= html.links().get() |
toString() | 同get(),返回一条String类型的结果 | String link= html.links().toString() |
all() | 返回所有抽取结果 | List links= html.links().all() 获取所有链接 |
String str = page.getHtml()
.css("div#news_div")
.links().regex(".*[0-3]$").toString();
String get = page.getHtml()
.css("div#news_div")
.links().regex(".*[0-3]$").get();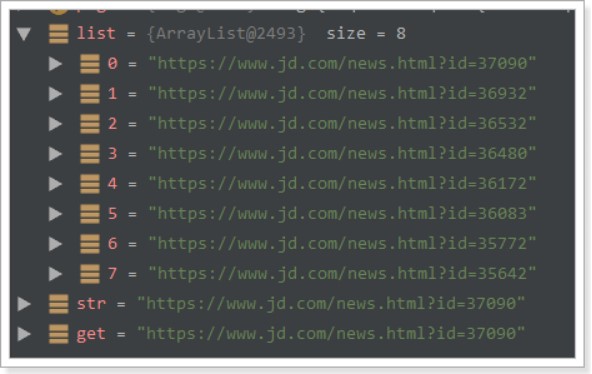
获取链接
public void process(Page page) {
//将获取的链接放进webmagic管理
page.addTargetRequests(page.getHtml().links()
.regex("(https://www.jd.com/news.\\w+?.*)").all());
System.out.println(page.getHtml().css("div.mt>h1").all());
}
public static void main(String[] args) {
Spider.create(new JobProcessor())
.addUrl("https://www.jd.com/moreSubject.aspx")
.run();
}使用Pipeline保存结果
public static void main(String[] args) {
Spider.create(new JobProcessor())
//初始访问url地址
.addUrl("https://www.jd.com/moreSubject.aspx")
.addPipeline(new FilePipeline("D:/webmagic/"))
.thread(5)//设置线程数
.run();
}使用和定制Pipeline
public interface Pipeline {
// ResultItems保存了抽取结果,它是一个Map结构,
// 在page.putField(key,value)中保存的数据,
//可以通过ResultItems.get(key)获取
public void process(ResultItems resultItems, Task task);
}- 为了模块分离
- Pipeline的功能比较固定,更容易做成通用组件
spider.addPipeline(new ConsolePipeline())
.addPipeline(new FilePipeline())类 | 说明 | 备注 |
ConsolePipeline | 输出结果到控制台 | 抽取结果需要实现toString方法 |
FilePipeline | 保存结果到文件 | 抽取结果需要实现toString方法 |
JsonFilePipeline | JSON格式保存结果到文件 | |
ConsolePageModelPipeline | (注解模式)输出结果到控制台 | |
FilePageModelPipeline | (注解模式)保存结果到文件 | |
JsonFilePageModelPipeline | (注解模式)JSON格式保存结果到文件 | 想持久化的字段需要有getter方法 |
持久化到数据库
@Component
public class SpringDataPipeline implements Pipeline {
@Autowired
private JobInfoService jobInfoService;
@Override
public void process(ResultItems resultItems, Task task) {
//获取需要保存到MySQL的数据
JobInfo jobInfo = resultItems.get("jobInfo");
//判断获取到的数据不为空
if(jobInfo!=null) {
//如果有值则进行保存
this.jobInfoService.save(jobInfo);
}
}
}@Autowired
private SpringDataPipeline springDataPipeline;
public void process() {
Spider.create(new JobProcessor())
.addUrl(url)
//将Pipeline设置进去
.addPipeline(this.springDataPipeline)
.thread(5)
.run();
}爬虫的配置、启动和终止
Spider
方法 | 说明 | 示例 |
create(PageProcessor) | 创建Spider | Spider.create(new GithubRepoProcessor()) |
addUrl(String…) | 添加初始的URL | spider .addUrl("http://webmagic.io/docs/") |
thread(n) | 开启n个线程 | spider.thread(5) |
run() | 启动,会阻塞当前线程执行 | spider.run() |
start()/runAsync() | 异步启动,当前线程继续执行 | spider.start() |
stop() | 停止爬虫 | spider.stop() |
addPipeline(Pipeline) | 添加一个Pipeline,一个Spider可以有多个Pipeline | spider .addPipeline(new ConsolePipeline()) |
setScheduler(Scheduler) | 设置Scheduler,一个Spider只能有个一个Scheduler | spider.setScheduler(new RedisScheduler()) |
setDownloader(Downloader) | 设置Downloader,一个Spider只能有个一个Downloader | spider .setDownloader( new SeleniumDownloader()) |
get(String) | 同步调用,并直接取得结果 | ResultItems result = spider .get("http://webmagic.io/docs/") |
getAll(String…) | 同步调用,并直接取得一堆结果 | List<ResultItems> results = spider .getAll("http://webmagic.io/docs/", "http://webmagic.io/xxx") |
爬虫配置Site
private Site site = Site.me()
.setCharset("UTF-8")//编码
.setSleepTime(1)//抓取间隔时间
.setTimeOut(1000*10)//超时时间
.setRetrySleepTime(3000)//重试时间
.setRetryTimes(3);//重试次数方法 | 说明 | 示例 |
setCharset(String) | 设置编码 | site.setCharset("utf-8") |
setUserAgent(String) | 设置UserAgent | site.setUserAgent("Spider") |
setTimeOut(int) | 设置超时时间, 单位是毫秒 | site.setTimeOut(3000) |
setRetryTimes(int) | 设置重试次数 | site.setRetryTimes(3) |
setCycleRetryTimes(int) | 设置循环重试次数 | site.setCycleRetryTimes(3) |
addCookie(String,String) | 添加一条cookie | site.addCookie("dotcomt_user","code4craft") |
setDomain(String) | 设置域名,需设置域名后,addCookie才可生效 | site.setDomain("github.com") |
addHeader(String,String) | 添加一条addHeader | site.addHeader("Referer","https://github.com") |
setHttpProxy(HttpHost) | 设置Http代理 | site.setHttpProxy(new HttpHost("127.0.0.1",8080)) |
Scheduler组件(url去重)
- 对待抓取的URL队列进行管理。
- 对已抓取的URL进行去重。
类 | 说明 | 备注 |
DuplicateRemovedScheduler | 抽象基类,提供一些模板方法 | 继承它可以实现自己的功能 |
QueueScheduler | 使用内存队列保存待抓取URL | |
PriorityScheduler | 使用带有优先级的内存队列保存待抓取URL | 耗费内存较QueueScheduler更大,但是当设置了request.priority之后,只能使用PriorityScheduler才可使优先级生效 |
FileCacheQueueScheduler | 使用文件保存抓取URL,可以在关闭程序并下次启动时,从之前抓取到的URL继续抓取 | 需指定路径,会建立.urls.txt和.cursor.txt两个文件 |
RedisScheduler | 使用Redis保存抓取队列,可进行多台机器同时合作抓取 | 需要安装并启动redis |
类 | 说明 |
HashSetDuplicateRemover | 使用HashSet来进行去重,占用内存较大 |
BloomFilterDuplicateRemover(推荐) | 使用BloomFilter来进行去重,占用内存较小,但是可能漏抓页面 |
<!--WebMagic对布隆过滤器的支持-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>16.0</version>
</dependency>public static void main(String[] args) {
Spider.create(new JobProcessor())
//初始访问url地址
.addUrl("https://www.jd.com/moreSubject.aspx")
.addPipeline(new FilePipeline("D:/webmagic/"))
.setScheduler(new QueueScheduler()
//配置布隆过滤器
//参数设置需要对多少条数据去重
.setDuplicateRemover(new BloomFilterDuplicateRemover(10000000)))
.thread(1)//设置线程数
.run();
}//每次加入相同的url,测试去重
page.addTargetRequest("https://www.jd.com/news.html?id=36480");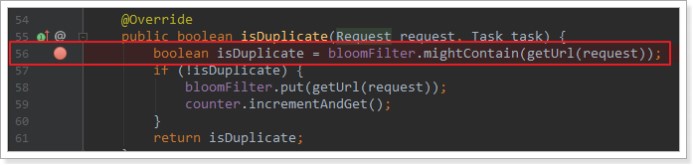
三种去重方式
- HashSet
- Redis去重
- 布隆过滤器(BloomFilter) 建议
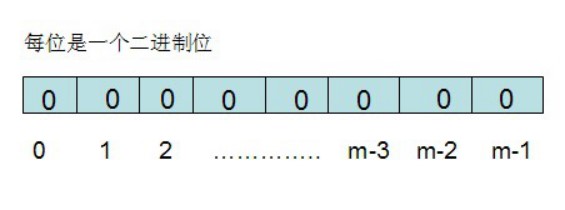
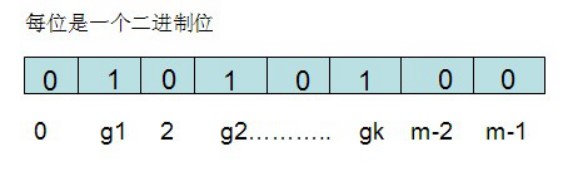
布隆过滤器实现(了解)
//布隆过滤器
public class BloomFilter {
/* BitSet初始分配2^24个bit */
private static final int DEFAULT_SIZE = 1 << 24;
/* 不同哈希函数的种子,一般应取质数 */
private static final int[] seeds = new int[] { 5, 7, 11, 13, 31, 37 };
private BitSet bits = new BitSet(DEFAULT_SIZE);
/* 哈希函数对象 */
private SimpleHash[] func = new SimpleHash[seeds.length];
public BloomFilter() {
for (int i = 0; i < seeds.length; i++) {
func[i] = new SimpleHash(DEFAULT_SIZE, seeds[i]);
}
}
// 将url标记到bits中
public void add(String str) {
for (SimpleHash f : func) {
bits.set(f.hash(str), true);
}
}
// 判断是否已经被bits标记
public boolean contains(String str) {
if (StringUtils.isBlank(str)) {
return false;
}
boolean ret = true;
for (SimpleHash f : func) {
ret = ret && bits.get(f.hash(str));
}
return ret;
}
/* 哈希函数类 */
public static class SimpleHash {
private int cap;
private int seed;
public SimpleHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
// hash函数,采用简单的加权和hash
public int hash(String value) {
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++) {
result = seed * result + value.charAt(i);
}
return (cap - 1) & result;
}
}
}4.网页去重
去重方案介绍
SimHash
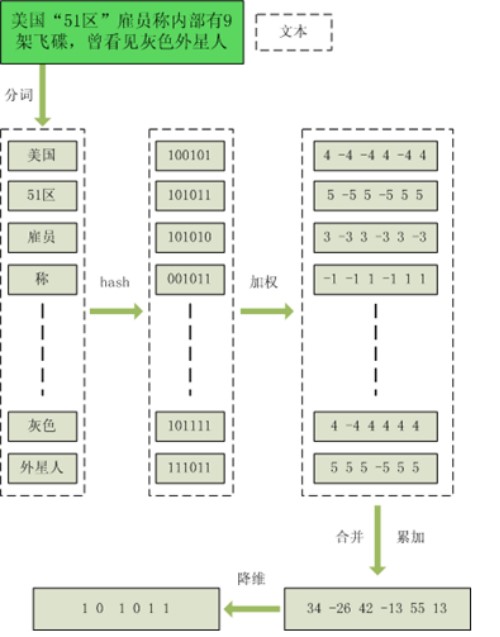
流程介绍
- 分词,把需要判断文本分词形成这个文章的特征单词。
- hash,通过hash算法把每个词变成hash值,比如“美国”通过hash算法计算为 100101,“51区”通过hash算法计算为 101011。这样我们的字符串就变成了一串串数字。
- 加权,通过 2步骤的hash生成结果,需要按照单词的权重形成加权数字串,“美国”的hash值为“100101”,通过加权计算为“4 -4 -4 4 -4 4”
- 合并,把上面各个单词算出来的序列值累加,变成只有一个序列串。
把每一位进行累加, “4+5 -4+-5 -4+5 4+-5 -4+5 4+5”“9 -9 1 -1 1 9”
- 降维,把算出来的 “9 -9 1 -1 1 9”变成 0 1 串,形成最终的simhash签名。
签名(海明)距离计算
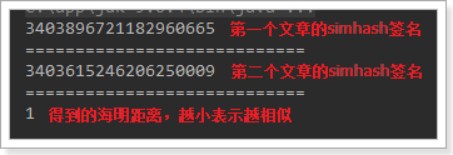
导入本地仓库测试整合
<!--simhash网页去重-->
<dependency>
<groupId>com.lou</groupId>
<artifactId>simhasher</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>@Component
public class TaskTest {
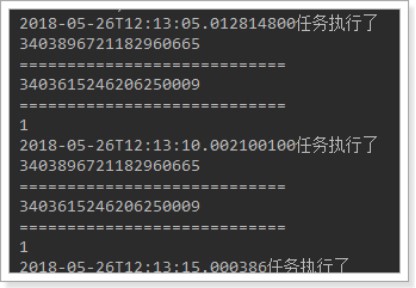
@Scheduled(cron = "0/5 * * * * *")
public void test() {
System.out.println(LocalDateTime.now()+"任务执行了");
String str1 = readAllFile("D:/test/testin.txt");
SimHasher hash1 = new SimHasher(str1);
//打印simhash签名
System.out.println(hash1.getSignature());
System.out.println("============================");
String str2 = readAllFile("D:/test/testin2.txt");
//打印simhash签名
SimHasher hash2 = new SimHasher(str2);
System.out.println(hash2.getSignature());
System.out.println("============================");
//打印海明距离 System.out.println(hash1.getHammingDistance(hash2.getSignature()));
}
public static String readAllFile(String filename) {
String everything = "";
try {
FileInputStream inputStream = new FileInputStream(filename);
everything = IOUtils.toString(inputStream);
inputStream.close();
} catch (IOException e) {
}
return everything;
}
}
5.代理的使用
代理服务器
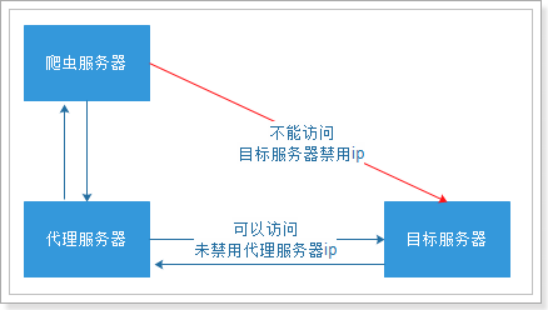
使用代理
API | 说明 |
HttpClientDownloader.setProxyProvider(ProxyProvider proxyProvider) | 设置代理 |
@Component
public class ProxyTest implements PageProcessor {
@Scheduled(fixedDelay = 10000)
public void testProxy() {
//创建HttpClientDownloader
HttpClientDownloader httpClientDownloader = new HttpClientDownloader();
//设置代理
httpClientDownloader.setProxyProvider(SimpleProxyProvider.from(new Proxy("39.137.77.68",80)));
Spider.create(new ProxyTest())
.addUrl("http://ip.chinaz.com/getip.aspx")
.setDownloader(httpClientDownloader)
.run();
}
@Override
public void process(Page page) {
//打印获取到的结果以测试代理服务器是否生效
System.out.println(page.getHtml());
}
private Site site = new Site();
@Override
public Site getSite() {
return site;
}
}6.案例
常用爬取代码模板(模板)
<!--核心依赖 strart-->
<!--WebMagic核心包-->
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.4</version>
<!--springboot有日志,排除wenmagic的依赖-->
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<!--WebMagic扩展-->
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.4</version>
</dependency>
<!--WebMagic对布隆过滤器的支持-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>16.0</version>
</dependency>
<!--核心依赖 end-->@Component
public class JobProcessor implements PageProcessor {
private String url = "";
@Scheduled(initialDelay = 1000, fixedDelay = 1000 * 100)
@Override
public void process(Page page) {
//解析页面
String html = page.getHtml().toString();
}
private Site site = Site.me()
.setCharset("gbk")//设置编码
.setTimeOut(10 * 1000)//设置超时时间
.setRetrySleepTime(3000)//设置重试的间隔时间
.setRetryTimes(3);//设置重试的次数
@Override
public Site getSite() {
return site;
}
@Autowired
private SpringDataPipeline springDataPipeline;
//initialDelay当任务启动后,等等多久执行方法
//fixedDelay每个多久执行方法
//@Scheduled(initialDelay = 1000, fixedDelay = 100 * 1000)
public void process() {
Spider.create(new JobProcessor())
.addUrl(url)//url
.setScheduler(new QueueScheduler().setDuplicateRemover(new BloomFilterDuplicateRemover(100000)))//布隆过滤器
.thread(10)//线程Pipeline
.addPipeline(this.springDataPipeline)//自定义Pipeline
.run();
}
}@Component
public class SpringDataPipeline implements Pipeline {
@Autowired
private JobInfoService jobInfoService;
@Override
public void process(ResultItems resultItems, Task task) {
//获取封装好的招聘详情对象
JobInfo jobInfo = resultItems.get("jobInfo");
}
}
爬取招聘信息

CREATE TABLE `job_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键id',
`company_name` varchar(100) DEFAULT NULL COMMENT '公司名称',
`company_addr` varchar(200) DEFAULT NULL COMMENT '公司联系方式',
`company_info` text COMMENT '公司信息',
`job_name` varchar(100) DEFAULT NULL COMMENT '职位名称',
`job_addr` varchar(50) DEFAULT NULL COMMENT '工作地点',
`job_info` text COMMENT '职位信息',
`salary_min` int(10) DEFAULT NULL COMMENT '薪资范围,最小',
`salary_max` int(10) DEFAULT NULL COMMENT '薪资范围,最大',
`url` varchar(150) DEFAULT NULL COMMENT '招聘信息详情页',
`time` varchar(10) DEFAULT NULL COMMENT '职位最近发布时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='招聘信息'; <dependencies>
<!--核心依赖 strart-->
<!--WebMagic核心包-->
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.4</version>
<!--springboot有日志,排除wenmagic的依赖-->
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<!--WebMagic扩展-->
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.4</version>
</dependency>
<!--WebMagic对布隆过滤器的支持-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>16.0</version>
</dependency>
<!--核心依赖 end-->
<!--SpringMVC-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--SpringData Jpa-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!--MySQL连接包-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!--工具包-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
</dependency>
</dependencies>
@Component
public class JobProcessor implements PageProcessor {
private String url = "https://search.51job.com/list/000000,000000,0000,32%252C01,9,99,java,2," +
"1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99" +
"&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line" +
"=&specialarea=00&from=&welfare=";
@Override
public void process(Page page) {
//解析页面,获取招聘信息详情的url地址
List<Selectable> list = page.getHtml().css("div#resultList div.el").nodes();
//判断获取到的集合是否为空
if (list.size() == 0) {
// 如果为空,表示这是招聘详情页,解析页面,获取招聘详情信息,保存数据
this.saveJobInfo(page);
} else {
//如果不为空,表示这是列表页,解析出详情页的url地址,放到任务队列中
for (Selectable selectable : list) {
//获取url地址
String jobInfoUrl = selectable.links().toString();
//把获取到的url地址放到任务队列中
page.addTargetRequest(jobInfoUrl);
}
//获取下一页的url
String bkUrl = page.getHtml().css("div.p_in li.bk").nodes().get(1).links().toString();
//把url放到任务队列中
page.addTargetRequest(bkUrl);
}
String html = page.getHtml().toString();
}
//解析页面,获取招聘详情信息,保存数据
private void saveJobInfo(Page page) {
//创建招聘详情对象
JobInfo jobInfo = new JobInfo();
//解析页面
Html html = page.getHtml();
//获取数据,封装到对象中
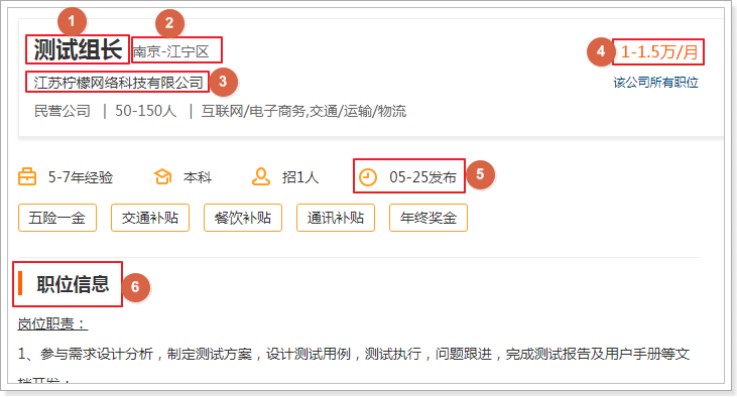
jobInfo.setCompanyName(html.css("div.cn p.cname a","text").toString());
jobInfo.setCompanyAddr(Jsoup.parse(html.css("div.bmsg").nodes().get(1).toString()).text());
jobInfo.setCompanyInfo(Jsoup.parse(html.css("div.tmsg").toString()).text());
jobInfo.setJobName(html.css("div.cn h1","text").toString());
jobInfo.setJobAddr(html.css("div.cn span.lname","text").toString());
jobInfo.setJobInfo(Jsoup.parse(html.css("div.job_msg").toString()).text());
jobInfo.setUrl(page.getUrl().toString());
//获取薪资
Integer[] salary = MathSalary.getSalary(html.css("div.cn strong", "text").toString());
jobInfo.setSalaryMin(salary[0]);
jobInfo.setSalaryMax(salary[1]);
//获取发布时间
String time = Jsoup.parse(html.css("div.t1 span").regex(".*发布").toString()).text();
jobInfo.setTime(time.substring(0,time.length()-2));
//把结果保存起来
page.putField("jobInfo",jobInfo);
}
private Site site = Site.me()
.setCharset("gbk")//设置编码
.setTimeOut(10 * 1000)//设置超时时间
.setRetrySleepTime(3000)//设置重试的间隔时间
.setRetryTimes(3);//设置重试的次数
@Override
public Site getSite() {
return site;
}
@Autowired
private SpringDataPipeline springDataPipeline;
//initialDelay当任务启动后,等等多久执行方法
//fixedDelay每个多久执行方法
//@Scheduled(initialDelay = 1000, fixedDelay = 100 * 1000)
public void process() {
Spider.create(new JobProcessor())
.addUrl(url)
.setScheduler(new QueueScheduler().setDuplicateRemover(new BloomFilterDuplicateRemover(100000)))
.thread(10)
.addPipeline(this.springDataPipeline)
.run();
}
}@Component
public class SpringDataPipeline implements Pipeline {
@Autowired
private JobInfoService jobInfoService;
@Override
public void process(ResultItems resultItems, Task task) {
//获取封装好的招聘详情对象
JobInfo jobInfo = resultItems.get("jobInfo");
//判断数据是否不为空
if (jobInfo != null) {
//如果不为空把数据保存到数据库中
this.jobInfoService.save(jobInfo);
}
}
}
附件列表

 浙公网安备 33010602011771号
浙公网安备 33010602011771号