
数据结构与算法——十个排序算法之九 · 桶排序
1.桶排序说明
桶排序是计数排序的升级版。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。为了使桶排序更加高效,我们需要做到这两点:
- 在额外空间充足的情况下,尽量增大桶的数量
- 使用的映射函数能够将输入的 N 个数据均匀的分配到 K 个桶中
同时,对于桶中元素的排序,选择何种比较排序算法对于性能的影响至关重要。
最快的时候:当输入的数据可以均匀的分配到每一个桶中。
最慢的时候:当输入的数据被分配到了同一个桶中。
2. 示意图
元素分布在桶中:
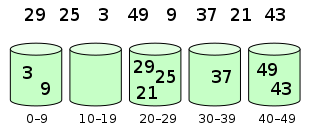
然后,元素在每个桶中排序:

3.代码实现
1 #include<iterator> 2 #include<iostream> 3 #include<vector> 4 5 using namespace std; 6 7 const int BUCKET_NUM = 10; 8 9 struct ListNode 10 { 11 explicit ListNode(int i=0):mData(i),mNext(NULL){} 12 ListNode* mNext; 13 int mData; 14 }; 15 16 ListNode* insert(ListNode* head,int val) 17 { 18 ListNode dummyNode; 19 ListNode *newNode = new ListNode(val); 20 ListNode *pre,*curr; 21 dummyNode.mNext = head; 22 pre = &dummyNode; 23 curr = head; 24 25 while(NULL!=curr && curr->mData<=val) 26 { 27 pre = curr; 28 curr = curr->mNext; 29 } 30 31 newNode->mNext = curr; 32 pre->mNext = newNode; 33 34 return dummyNode.mNext; 35 } 36 37 38 ListNode* Merge(ListNode *head1,ListNode *head2) 39 { 40 ListNode dummyNode; 41 ListNode *dummy = &dummyNode; 42 while(NULL!=head1 && NULL!=head2) 43 { 44 if(head1->mData <= head2->mData) 45 { 46 dummy->mNext = head1; 47 head1 = head1->mNext; 48 } 49 else 50 { 51 dummy->mNext = head2; 52 head2 = head2->mNext; 53 } 54 dummy = dummy->mNext; 55 } 56 57 if(NULL!=head1) dummy->mNext = head1; 58 if(NULL!=head2) dummy->mNext = head2; 59 60 return dummyNode.mNext; 61 } 62 63 void BucketSort(int n,int arr[]) 64 { 65 vector<ListNode*> buckets(BUCKET_NUM,(ListNode*)(0)); 66 for(int i=0;i<n;++i) 67 { 68 int index = arr[i]/BUCKET_NUM; 69 ListNode *head = buckets.at(index); 70 buckets.at(index) = insert(head,arr[i]); 71 } 72 ListNode *head = buckets.at(0); 73 for(int i=1;i<BUCKET_NUM;++i) 74 { 75 head = Merge(head,buckets.at(i)); 76 } 77 for(int i=0;i<n;++i) 78 { 79 arr[i] = head->mData; 80 head = head->mNext; 81 } 82 }
====================================================================================================================

 浙公网安备 33010602011771号
浙公网安备 33010602011771号