JVM
1.JVM中有哪几块内存区域?Java 8之后对内存分代做了什么改进?
JVM最常用的内存区域有三块 栈内存,堆内存和永久代。栈内存是线程每个线程独享的,堆内存是共享的,永久代中存储的是类的信息。
java8 之后将永久代中的常量池放到了堆内存中,永久代变成了metaspace(元区域)。
2. heap 和stack 有什么区别?
(1)申请方式
stack:由系统自动分配。例如,声明在函数中一个局部变量 int b; 系统自动在栈中为 b 开辟空间
heap:需要程序员自己申请,并指明大小,在 c 中 malloc 函数,对于Java 需要手动 new Object()的形式开辟
(2)申请后系统的响应
stack:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
heap:首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序。另外,由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。
(3)申请大小的限制
stack:栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在 WINDOWS 下,栈的大小是 2M(默认值也取决于虚拟内存的大小),如果申请的空间超过栈的剩余空间时,将提示 overflow。因此,能从栈获得的空间较小。
heap:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的, 自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见, 堆获得的空间比较灵活,也比较大。
(4)申请效率的比较
stack:由系统自动分配,速度较快。但程序员是无法控制的。
heap:由 new 分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便。
(5)heap和stack中的存储内容
stack:在函数调用时,第一个进栈的是主函数中后的下一条指令(函数调用语句的下一条可执行语句)的地址, 然后是函数的各个参数,在大多数的 C 编译器中,参数是由右往左入栈的,然后是函数中的局部变量。注意静态变量是不入栈的。
当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行。
heap:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容有程序员安排。
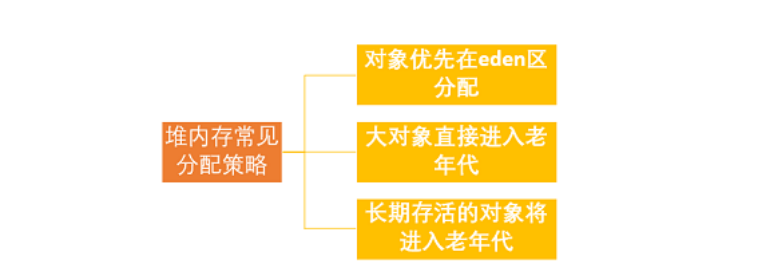
2.你知道JVM是如何运行起来的吗?堆内存中对象的分配的基本策略?
堆空间的基本结构:

新生代:eden区、s0区、s1区 默认大小分配8:1:1
老年代:tentired区
Minor Gc(新生代垃圾回收)和Full/Major Gc(老年代垃圾回收)有什么不同?
大多数情况下,对象在新生代中eden区分配。当Eden区没有足够的空间进行分配时,虚拟机将发起一次Minor Gc。
- 新生代GC:指发生新生代的垃圾收集动作,Minor GC非常频繁,回收速度一般比较快
- 老年代Gc:指发生在老年代的GC,出现Major GC经常会伴随至少一次Minor GC(并非绝对),Major GC的速度一般会比MinorGC慢10倍以上。
3.说说JVM在哪些情况下会触发垃圾回收可以吗?
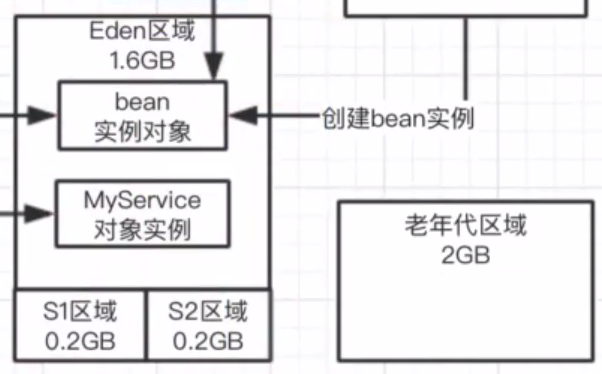
我们的jvm的内存其实是有限制的,不可能是无限的,昂贵的资源,2核4G的机器,堆内存也就2GB左右,4核8G的机器堆内存也就4G左右,栈内存也需要空间,metaspace区域放类信息也需要空间。
jvm中有一个内存分代模型,年轻代和老年代,加在一起是堆内存,其中年轻代又分为三部分。年轻代和老年代的比例是我们可以设置的。
比如说年轻代一共是2GB内存,给老年代是2GB内存,默认情况下eden和2个s的比例是:8:1:1,eden是1.6GB, s是0.2GB
如果eden区域满了,此时必然触发垃圾回收,young gc ,ygc。谁是可以回收的垃圾对象?没有被引用的对象就是可以被回收的对象。
4.说说JVM的年轻代垃圾回收算法?对象什么时候转移到老年代?
垃圾回收有一个概念,叫做stop the world,停止你的jvm里的工作线程的运行,然后扫描所有的对象,判断哪些可以回收,哪些不可以回收。
年轻代,大部分情况下,对象生存周期是很短的,可能0.01ms之内,线程执行了3个方法,创建了几个对象,0.01ms之后方法就都执行结束了,此时那几个对象就会在0.01ms之内变成垃圾,可以回收了。
复制算法,一次young gc,年轻代的垃圾回收。将eden中存活的对象复制到s1中,清空eden:
将s1和eden中存活的复制到s2中,清空eden和s1;将s2和eden存活的复制到s1中,清空eden和s2.
三种场景,第一种场景,有的对象在年轻代里面熬过了很多次的垃圾回收,例如15次垃圾回收,此时会认为这个对象是要长期存活的对象。例如Spring容器中的bean对象。
第二种情况就是s区放不下存活的对象。
第三种情况就是特别大的对象。反复移动大对象消耗性能。
5.说说老年代的垃圾回收算法?常用的垃圾回收器都有什么?
老年代对象越来越多,老年代内存空间也会满,是不是可以使用类似的年轻代的复制算法?
答案是否定的,因为在老年代的对象中,很多都是长期引用的,spring容器管理的各种bean。
长期存活的对象是比较多的,可能甚至都有几百mb
对老年代而言,他里面的垃圾对象可能是没有那么多的。一开始采用标记-清理的方式,找出那些垃圾对象,然后直接把垃圾对象在老年代里清理掉,这样就会产生内存 碎片的问题。
后来采用标记-整理的方法,把老年代里的存活对象标记出来,移动到一起,存活对象压缩到一片内存空间去
剩余的空间都是垃圾整个给清理掉,剩余的都是连续的可用的内存空间,解决了内存碎片的问题。
垃圾回收器
parnew (新生代)+ cms(老年代)的组合, g1 直接分代回收 。g1可以实现新生代和老年代的垃圾一起回收。新版本,慢慢的就是主推g1垃圾回收器了,以后会淘汰掉parnews+cms组合,但是现在使用jdk8~jdk9居多,所以还是parnew+cms组合居多。
cms分成好几个阶段,初始标记,并发标记,并发清理等等,老年代垃圾回收是比较慢的,一般起码比年轻代垃圾回收慢个10倍以上。所以将它拆分成几个阶段,尽可能得让其和运行的其它线程并发执行。
6.谈谈你对java跨平台性的理解?为什么java可以一次编译到处运行?
不是说java语言可以跨平台,而是各个不同的平台都可以有让java语言运行的环境而已。
程序从源码到运行可以分为以下几个阶段,编码-编译-运行-调试。java在编译阶段体现了跨平台的特性。编译的过程大概是这样的:首先将java源码转化成class字节码文件,这是第一次编译,class字节码文件就是可以到处运行的文件。然后java字节码会被转化为目标机器的机器代码,这是由JVM来执行的,就是java的第二次编译。
“到处运行”的关键和前提就是JVM。因为在第二次编译的过程中JVM起着至关重要的作用。在可以运行java虚拟机的地方都内含着一个JVM操作系统。从而实现到处运行的效果。需要强调的是,java不是编译机制,而是解释机制。java字节码的设计充分考虑了JIT这一及时编译方式,可以将字节码直接转化成高性能的本地机器码,这同样是虚拟机的一个构成部分。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号