/*
* Redis应用之Hash数据类型
* 问题1:操作命令
* 问题2:存储实现原理和数据结构
* 问题3:应用场景
* */
先了解下什么是hash,什么是hash碰撞:
hash:是包含键值对的kv的数据结构,是一个无序的散列表。
碰撞:任意一个字符串经过hash算法之后都会输出一个固定长度的字符串,当发现输出的固定长度字符串的值一样的时候我们称之为hash碰撞(发生的概率很小)
1、操作命令:
存:
hset h1 f 6
hset h1 e 5
hmset h1 a 1 b 2 c 3 d 4
取:
hget h1 a
hmget h1 a b c d
hkeys h1
hvals h1
hgetall h1
key操作:
hget exists h1
hdel h1
hlen h1
2、存储原理:Redis的Hash是一个KV的结构,类似java中的hashMap,外层的hash只用到了hashtable。当存储hash数据类型的时候我们称之为内层hash,
内层hash由两种数据结构来实现:ziplist(压缩列表)和hashtable(hash表)。
ziplist:特殊编码实现的双向链表(时间换空间的方式节约内存,也就是牺牲部分读写性能来换取高效的内存空间利用率)只用在字段个数少,字段值小的场景中。
hash表:被称之为字典dict。
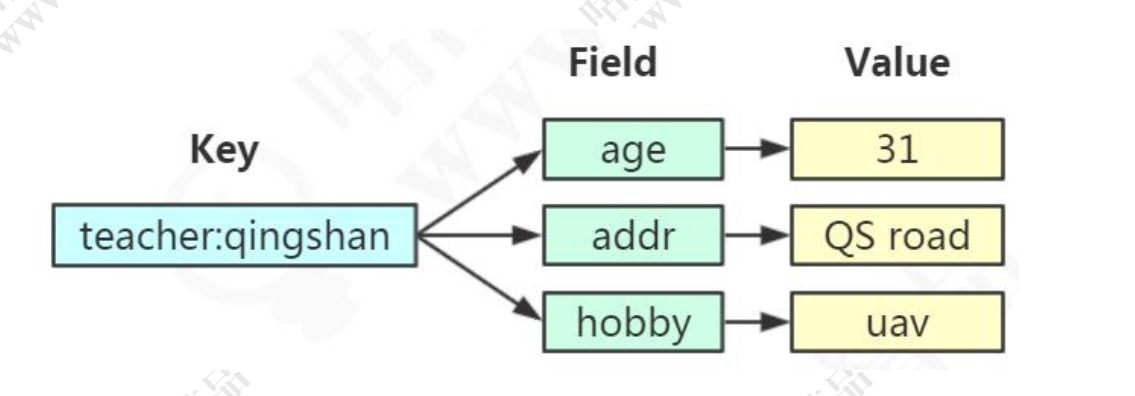
下面是hash数据结构图:
![]()
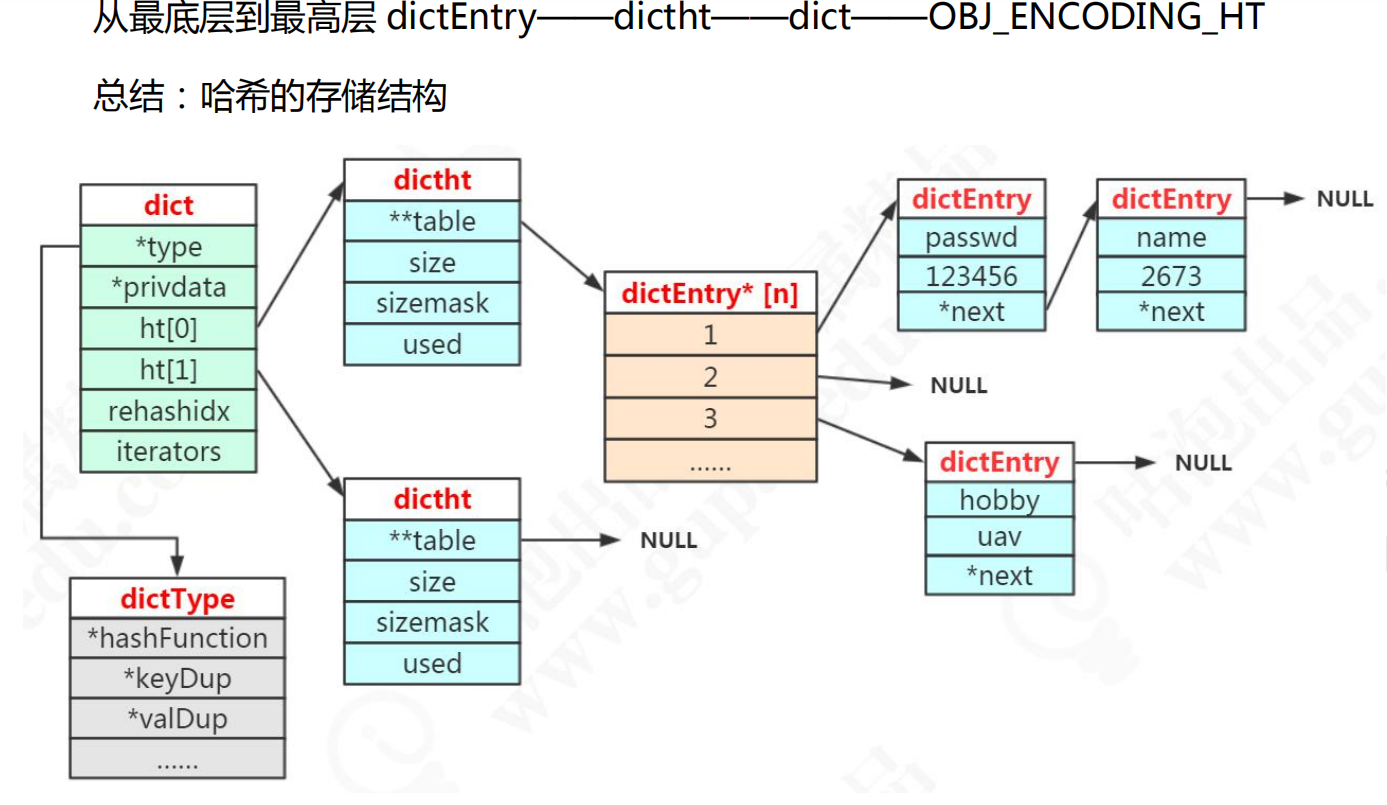
2、存储结构:KV的数据结构=数组+链表的结构。看一下hash的存储结构图:
![]()
文字说明:
在redis中把hash放到了一个dict字典中,字典里面又有两个dictht(hash表),两个hash表中分别有两个数组存取dictEntry,每个数组都是以链表的形式来存储的,为什么要用链表呢?
是因为数据存储的时候可能会发生了hash碰撞他是用链表的拉链法来解决的,当hash碰撞达到5次的时候,这个时候他就失去了hash本身的效率他就变成了一个链表了,所以他有两个hash表来存储,只不过第二个hash表
他是空的,当他发现hash碰撞达到5次的时候就会自动将数据放到第二个hash表中,也就是常说的rehash,第二个hahs表的作用就是为了进行rehash来实现自动扩容,防止dictEntry[*]中挂载的dictEntry多的时候失去hash本身的性能。
说明一下dictE[*]中每一个数组挂载的节点数为一个的时候性能最高。(链地址法:每一个及节点下面只有一个dictEntry的时候效率最高。)
3、应用场景:
string可以做的东西,hash基本上都可以,除了bit(位)操作。
购物车(增加、删除、全选商品,以及商品数)
课题之外总结:
根据上节的String来比对一下hash,分析两者的区别:
1)、String和hash都是用字符串存储的,那么他们俩有什么区别呢?
当存储一张表的数据的时候String存储是使用mset student:1:sno:aaa将多个列放在key中存储的,key是通过SDS来存储的,如果表的数据字段比较多的时候那么他的key就会比较长,这样是很占用内存空间的。
hash优势:hash会把key聚合起来这样key就很短节省内存空间,并且会减少key的冲突,批量取值的时候可以充分利用cpu并且减少io的操作。
hash的弊端:不支持单个列的过期时间,value过大不支持分布式存取(不支持分片)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号