AB测试-产品增长的利器
在谈AB测试之前,忍不住先说一说另外一个概念:Growth Hacking
这个词目前为止仍没有一个确切的中文翻译,直译过来就叫“增长黑客”。最早在2010年,由Qualaroo创始人兼首席执行官肖恩 埃利斯(Sean Ellis)提出这一概念,随后安德鲁 陈(Andrew Chen)在2012年4月发表一篇文章叫《Growth Hacker is the new VP Marketing》后引起业界广泛关注与交流。在硅谷很多知名的初创企业如Facebook、Twitter、LinkedIn等等专门为Growth Hacking这个角色成立独立的部门,全权负责用户增长。
“Growth Hacking”拆分开来看,“Growth(增长)”指的便是产品增长这一核心目标,不仅包括用户量的增加,更是囊括了产品各个声明周期各个阶段的核心指标(日活,月活,留存等等),增长的目标可以拆分为“AARRR”漏斗转化模型,即:Acquisition(获取用户)、Activation(激发活跃)、Retenition(提高留存)、Revenue(增加收入)、Referral(传播推荐)。之所以称为漏斗是因为每个环节都将会有一些流失,而剩下的那部分用户则在继续使用中流向下一个环节,在层层深入中实现最终转化。
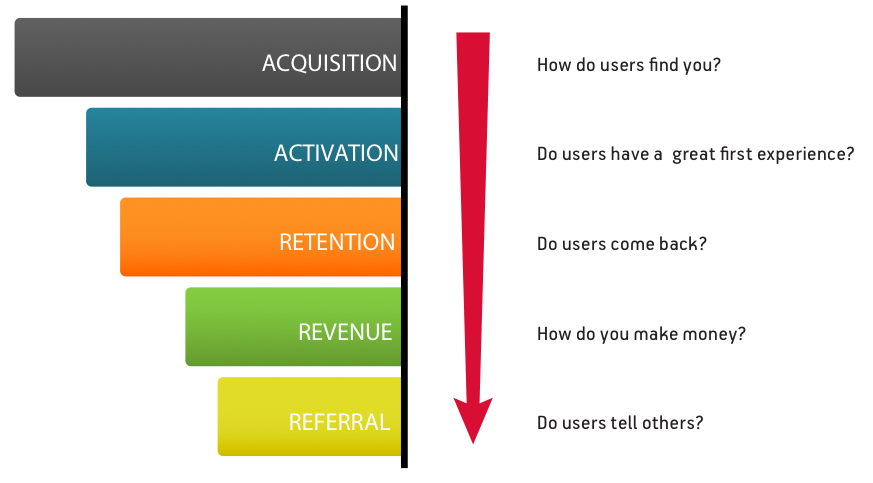
从“用户获取”到“传播推荐”在整个AARRR模型中,增长黑客在不断的“指标分析--提出目标--头脑风暴--AB测试”来提出产品优化策略,减少每个环节的损耗,提高转化率,从而不断的扩大自己用户群体的数量和质量。
而“Hacking(黑客)”我们可以理解为用创造性思维分析解决AARRR模型中每个阶段存在的问题。
关于“增长黑客”有兴趣的同学可以关注范冰著的《增长黑客》一书。
现在回到我们的AB测试,A/B测试概念简单概括就是,将用户分为两组,一组使用旧产品(或旧功能),一组使用新的。然后对比两个用户组,通过数据来分析,新的功能究竟是好是坏。没错,就跟小学的时候做的那些有控制组、实验组的自然科学实验一样一样的。
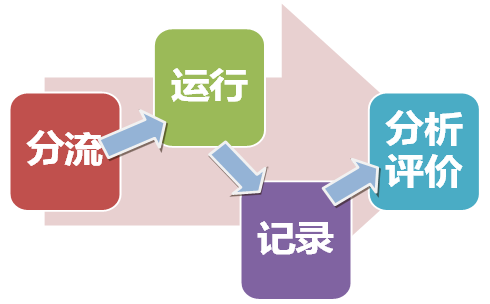
AB测试可以说是增长黑客分析和解决问题过程中最重要的武器。要实现产品优化,首先我们找到产品在AARRR模型中具体某个周期存在的问题,例如我们发现很多用户来到了产品注册页面,却没有产生注册的行为,那我们就可以得出一个简单的结论:注册页面转化效率比较低。之后提出我们的优化目标,即:提高注册页面的转化率。然后发动产品经理进行头脑风暴,提出优化方案。最后利用AB测试来验证方案是否可行。总结一下可以概括为“发现问题 - 提出目标 - 建立假设(提出优化方案)- AB试验 - 验证假设”若假设成立则上线新方案,若不成立则继续头脑风暴提出新方案。
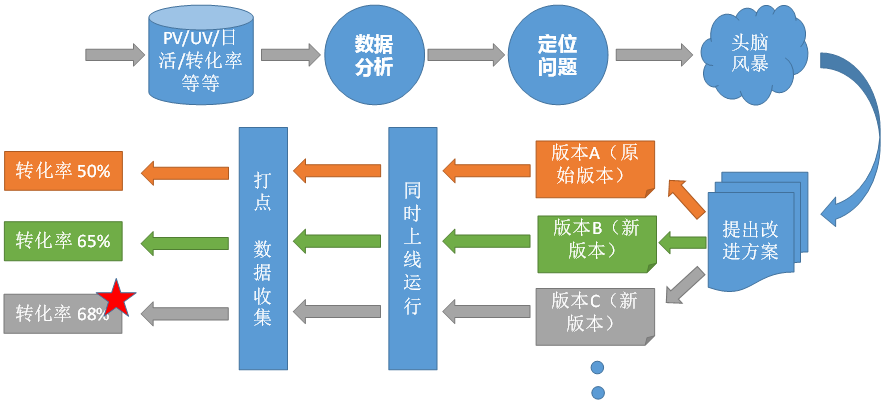
经过一番头脑风暴提出产品改进方案后,接下来就需要用AB测试来验证改进方案是否正确了,接下来我们来探讨一下具体的AB测试解决方案。
架构设计
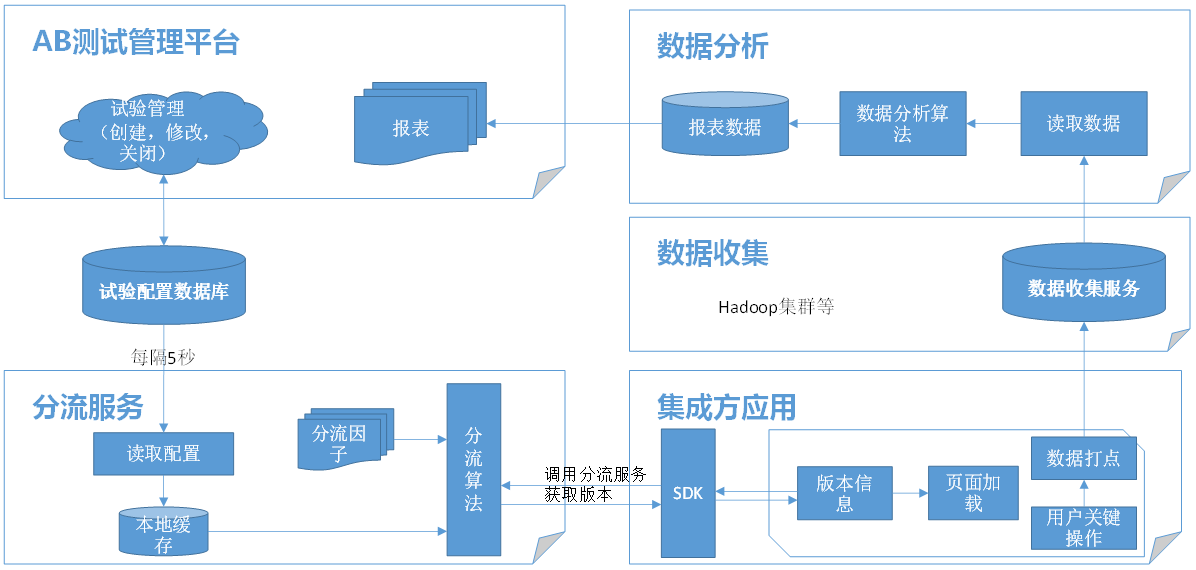
整个架构包括以下几个部分:
- AB测试管理平台:产品经理在管理平台上创建、修改、关闭试验,并查看试验结果报表。
- 试验配置数据库:AB试验管理平台后台数据库,主要存储AB试验配置信息。
- 分流服务:执行具体的分流算法的Web服务,客户端通过请求分流服务来获取具体加载哪个版本。
- 集成方应用:集成了AB测试SDK的应用程序,真正的AB测试需求方,可以是Web、Android、IOS、Windows客户端等。
- SDK:负责跟分流服务进行交互。
- 数据收集:收集应用程序打点数据。
- 数据分析:分析打点数据,通过一定的数据分析算法,得出能够判断版本优劣的报表数据。
AB测试管理平台
要开始AB试验,产品经理首先在【AB测试管理平台】上创建AB试验,填写AB试验的关键信息:
- 版本开关(集成方应用写死在代码里的,用于区分AB试验的依据)
- 优化指标(数据统计时收集的关键指标)
- 分流比例(将百分之多少的用户作为试验用户)
关于这三个属性暂时不理解没关系,稍后会再次介绍。
集成方应用
应用程序应为每个用户都生成一个唯一标识(通常随机生成一个uuid),用来区分用户,这个标识不应随着用户重启应用等行为而发生改变,我们姑且称这个唯一标识叫puid。分流服务会根据“puid”运行分流算法。
Tips:Web端可以在页面加载之前,运行一段JS代码生成并存储在cookie中最好一次生成永不过期,Android和IOS可以取设备号来作为puid。
当用户访问应用时,在页面加载之前首先利用SDK访问分流服务获取版本信息,再根据不同版本信息加载不同的版本。
当用户在使用过程中产生一些关键操作时,进行数据收集,发送相关统计数据到数据收集服务。
//全局唯一的puid,用户终端的唯一标识 String puid; //从分流服务获取到的版本信息 String versionInfo; //在页面加载之前执行此操作 void onPageLoad() { //版本开关 Stirng versionSwitch="android_client_purchase_button_color_test"; //将用户终端唯一标识,以及版本开关传递给分流服务,获取分流版本 versionInfo = getVersionInfo(puid,versionSwitch);
if(versionInfo=="版本A") { //运行版本A的初始化代码 } else if(versionInfo=="版本B") { //运行版本B的初始化代码 } } //在用户产生关键操作时打点统计数据 void onPurchase() { //将优化指标"purchase",版本信息,puid发送给数据收集服务 punchData("purchase",versionInfo,puid); }
观察上面的代码,假设我要做的AB试验是在安卓端测试“购买按钮的颜色对产品购买率的影响”。
我们首先设立一个版本开关叫做“android_client_purchase_button_color_test”,在创建在AB测试管理平台上创建AB实验之前,产品经理和产品开发人员约定好版本开关的值,分流服务根据版本开关的值判断请求来自于哪个AB实验,以便读取AB实验配置。
在应用程序页面加载之前,将“puid”和“版本开关”作为参数请求分流服务,分流服务根据“版本开关”判断请求来自哪个AB试验,并把“puid”作为参数运行分流算法,最终返回“版本信息”给客户端。客户端以分流服务返回的“版本信息”作为条件判断该加载哪个版本。
在用户产生购买行为时,将优化指标“purchase”,当前版本信息以及puid发送给数据收集服务。数据统计时通过计算在哪个版本上“purchase”这个指标被发送了多少次,以及用户量等。
那么puid的作用是什么呢?puid代表着客户终端的唯一性,代表着单个用户,在版本开关固定的情况下,用同一个puid去请求分流服务,只会产生同一个版本信息,也就是说用户第一次启动应用时看到的是版本A,下次启动看到的也是版本A,避免了“有时看到版本A,有时看到版本B”这种非常不好的用户体验。
SDK
上面架构设计图中,在集成方应用里面通过SDK与分流服务进行交互,简单的服务调用为何要专门一个SDK呢?
设想一下,当用户基数非常大的时候,每次用户打开页面都去调用分流服务来获取版本信息,这样的操作将会给分流服务带来非常大的压力。但其实我们并不需要每次重新请求分流服务,只需将上一次的请求结果写入缓存中,下一次打开应用时复制过来即可。 什么情况下需要重新请求分流服务?那就是当我们的AB试验有所更改,比如分流比例的更改,最初用5%的用户作为试验用户,后期为了进一步验证实验结果,需要将试验用户扩大到10%,也就是说有额外5%的用户需要从版本A切换到版本B,那么就需要重新请求分流服务了。
解决方案是,设定一个请求过期时间,假设一个小时(设定为一天也没有关系,通常一个AB试验至少运行几天,或几周才能得出一个比较靠谱的结果),再次调用分流服务之前,先观察一下缓存中有没有之前的请求结果,若之前的请求结果有没有过期,那么直接把上次的请求结果作为结果返回。
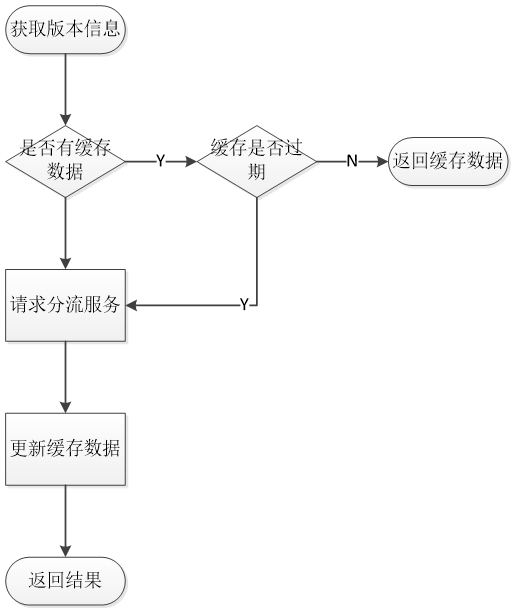
分流服务
分流服务的主要功能就是响应来自集成方应用的获取版本信息的请求。并每隔5秒钟同步一下最新的AB试验信息。
分流服务的逻辑:
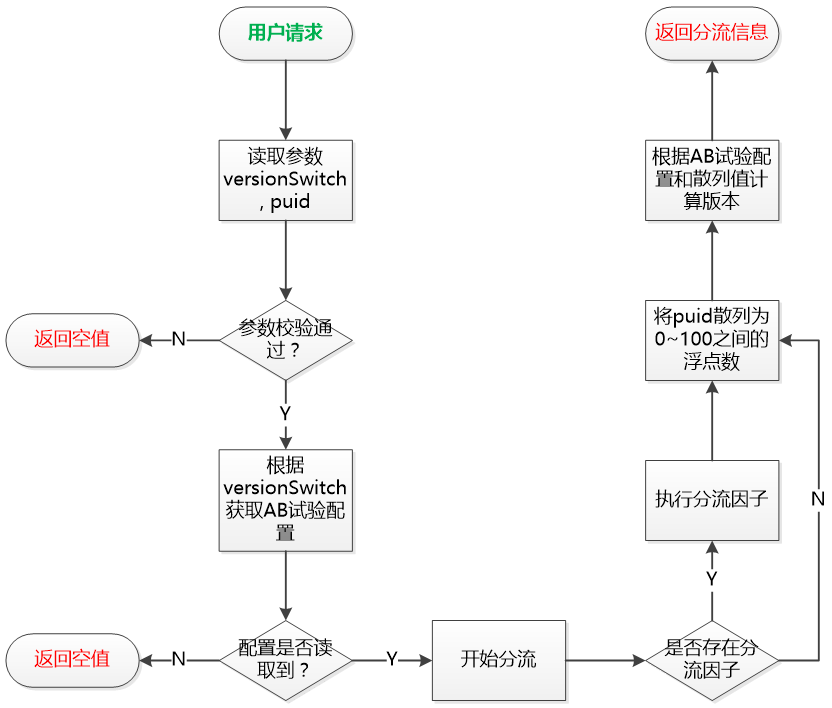
首先从用户请求中读取参数,然后对参数进行校验,根据versionSwtich(版本开关)的值从本地缓存中读取AB实验配置,然后开始执行分流算法,首先判断以下是否需要执行分流因子,若不需要则直接执行散列分流,若需要执行分流因子后再进行散列分流。
什么是分流因子?
有时候我们的AB实验并不是面向所有的用户展开,例如只对VIP用户进行AB实验,或者只在对上海的用户做AB实验,或者我们也可以只对上海和北京两个城市的用户做AB实验,于是我们把会员、地域等等划分条件成为分流因子。当需要按照分流因子分流的时候我们先按照分流因子对流量进行归类(需要客户端请求分流服务的时候将地域、是否会员必要的信息通过cookie或session等传递给分流服务),然后再执行散列分流。
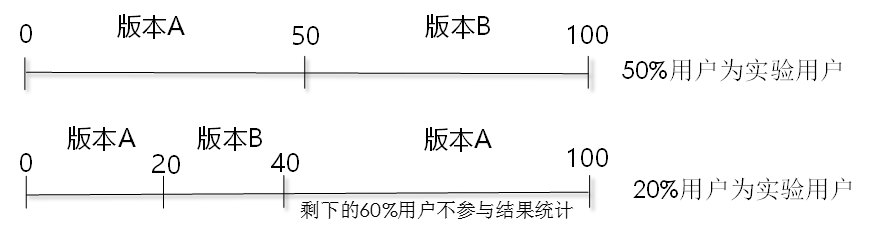
散列分流
“散列”就是将puid按照一个算法散列为0~100之间的小数,为了方便说明,我们暂时称散列后的值为K。前面说过,产品经理创建AB实验的时候,会填写一个分流比例,这个分流比例就决定了具体给用户分配哪个版本。假设拿50%的用户作为实验用户,那当K值落到0~50之间时,就会为用户分配版本A,当K值落到50~10之间时,就会为用户分配版本B。再假设拿20%的用户为实验用户,那么K值落在0~20之间时,为用户分配原始版本A,20~40之间则为用户分配版本B,另外60%的用户将不参与结果统计,返回原始版本A。
数据统计分析
在数据分析中我们用到了两个统计学的概念,即:“显著性”和“置信区间”。篇幅有限,这里就只介绍个大概。
A/B 测试是一种对比试验,而试验就是从总体中抽取一些样本进行数据统计,进而得出对总体参数的一个评估。
统计显著性。在假设检验中,如果样本数据拒绝原假设,我们说检验的结果是显著的;反之,我们则说结果是不显著的。
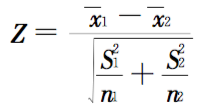
置信区间。置信水平代表了估计的可靠度,一般来说,我们使用 95% 的置信水平来进行区间估计。简单地讲,置信区间就是我们想要找到的这么一个均值区间范围,此区间有 95% 的可能性包含真实的总体均值。
数据举例
|
版本 |
用户总量 |
总值 |
平均 |
变化[95%置信区间] |
变化显著性 |
|
版本A |
42470 |
92990 |
2.19 |
|
|
|
版本B |
42674 |
108468 |
2.54 |
+16.09%[14.98%, 17.20%] |
显著 |
观察上面的表格
版本A一共有42470个用户,产生的打点数据量是92990,平均每个用户产生打点2.19次。
版本B一共有42670个用户,产生的打点数据量是108468,平均每个用户产生打点2.54次,比版本A提高了16.09%,我们有95%的概率相信,最差的情况下版本B比版本A好14.98%,最好的情况下版本B比版本A好17.20%,变化显著性为显著,代表版本B比版本A好这个命题是真的。
Tips: 除了上面提到的数据,在真实的事情情况中,还可以针对不用的版本分别统转化率,回访率,日活等等常用指标,观察用户活跃度、转化率等等的变化情况。
AB测试结合灰度发布
在一轮实验后我们发现版本B确实要比版本A更优秀,那么我们就可以在AB测试管理平台上结束这个实验,并设置最终版本为版本B,分流服务接到这个通知后就会改变分流策略,所有的请求都将返回版本B,这样就实现了一键发版。
AB测试的意义不只是验证改版策略是否正确,结合灰度发布来说,每一次新版本的发布都首先经历过小流量的 A/B 测试验证,所以可以保证确定性的提升。每一版更新都比老版要更好一些,日积月累就会大幅度超过 “裸奔” 的竞争对手。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号