局部敏感哈希LSH算法: MinHash、SimHash与Klongsent 指纹生成/文本查重/高效相似度计算等优劣对比
文本的相似性可以分为两类:一类是机械/物理相似性;一类是语义相似性。
机械相似性代表着,两个文本内容上的相关程度,比如“你好吗”和“你好”的相似性,纯粹代表着内容上字符是否完全共现,应用场景在:文档去重;
语义相似性代表着,两个文本语义上的相似程度,比如“苹果”和“公司”的相似性,本篇不做这一讨论,可参考笔者的另外一篇博客:NLP︱句子级、词语级以及句子-词语之间相似性(相关名称:文档特征、词特征、词权重)
简介:本文深入浅出地介绍了三种流行的文本去重算法——MinHash、SimHash和Klongsent,通过实例和图表解析其原理、应用场景及优缺点,帮助读者选择最适合自己需求的文本去重方案。
MinHash、SimHash、ssdeep、SDHash、TLSH,后续补充。
引言
矢量搜索算法的两个主要类别是 k-最近邻 (kNN) 和近似最近邻(ANN,不要与人工神经网络混淆)。工作原理:https://learn.microsoft.com/zh-cn/azure/cosmos-db/gen-ai/knn-vs-ann
kNN 很精确,但是计算量很大,不太适合大型数据集。 另一方面,ANN 提供了准确性和效率之间的平衡,使其更适合大规模应用程序。
近似最近邻搜索(ANN, Approximate Nearest Neighbor Search),是一种在高维向量空间中寻找与给定查询向量相近向量的技术。
在精确的最近邻搜索(NNS)中,目标是找到距离查询向量最近的一个或多个向量。然而,随着数据维度的增加和数据规模的扩大,精确搜索在计算上变得非常昂贵。
近似最近邻搜索(ANN) 是一种为了提升高维数据相似性搜索效率的技术,它在牺牲一定精度的前提下,大大提升了搜索速度。
它被广泛应用于推荐系统、图像检索、文本相似性搜索(自然语言处理NLP)、嵌入向量的快速检索等实际场景。
常见的ANN算法包括:分区树方法 {KD树(k-dimensional tree)球树(Ball tree)}、局部敏感哈希(LSH)、图嵌入法(如HNSW)、矢量量化(VQ)等,
它们通过不同的方式优化搜索过程,解决了高维数据中的“维度灾难”问题。
例如,在一个包含数百万张图像特征向量的数据库中,使用ANNS可以快速找到与给定图像特征向量近似最近的图像,虽然找到的可能不是绝对最近的邻居,但在很多实际应用场景中,这种近似结果已经足够满足需求
为了解决高维数据的近似最近邻搜索ANNS问题,局部敏感哈希(Locality Sensitive Hash,LSH)算法是近似最近邻搜索ANNS算法中最流行的一种方法被提出。
其核心思想是通过哈希函数将高维空间的数据映射到低维空间,使得在高维空间相邻的数据在低维空间落入同一个桶的概率较大,
从而将欧式空间的距离计算转化到汉明空间,提高检索速度。
在大数据时代,文本数据的处理与分析变得尤为重要。然而,随着数据量的激增,文本去重成为了一个不可忽视的问题。有效的文本去重不仅能减少存储空间的浪费,还能提升数据处理和分析的效率。
本文将详细介绍三种主流的文本去重算法:MinHash、SimHash和Klongsent,帮助读者理解其原理并应用于实际项目中。
一、MinHash算法
原理概述:
MinHash是一种用于估计两个集合相似度的概率算法。在文本去重领域,它通过将文本转换为特征集合(如shingling后的哈希集合),然后利用哈希函数随机选择特征集合中的最小哈希值来估计两个文本的Jaccard相似度。
应用场景:
- 网页去重
- 文档相似度检测
- 社交网络中的用户行为分析
优点:
- 计算效率高,适用于大规模数据集
- 能够有效估计集合间的相似度
缺点:
- 依赖于哈希函数的随机性,可能产生哈希碰撞
- 相似度估计存在误差
实例说明:
假设有两个文本集合A和B,通过shingling和哈希转换后,我们得到两个哈希集合。然后,使用多个哈希函数对这两个集合进行哈希,记录每次哈希后的最小值。通过比较这些最小值集合的相似度,可以估算出原始文本集合的相似度。
二、SimHash算法
原理概述:
SimHash是一种用于快速计算文本指纹的算法,通过降维技术将高维的文本特征向量映射成一个低维的哈希值(指纹)。该算法在保持文本相似度信息的同时,大大降低了数据的维度。
应用场景:
- 搜索引擎中的重复网页检测
- 垃圾邮件过滤
- 文本内容推荐系统
优点:
- 生成的哈希值短,便于存储和比较
- 能够有效保持文本的相似度信息
缺点:
- 依赖于特征提取的质量
- 相似度阈值的设定需要经验
实例说明:
SimHash算法首先将文本转换为特征向量,然后通过一系列哈希和位运算操作,最终得到一个固定长度的哈希值(指纹)。在比较两个文本的相似度时,只需比较它们的哈希值即可。
三、Klongsent算法(假设性算法,用于对比说明)
注意: Klongsent并非一个实际存在的广泛认知算法,这里作为对比说明,假设其是一种结合了MinHash和SimHash思想的混合算法。
假设原理:
Klongsent算法可能结合了MinHash的随机哈希选择和SimHash的降维技术,通过先对文本进行MinHash处理以快速筛选相似候选集,再对候选集应用SimHash算法生成短指纹进行精确匹配。
假设应用场景:
- 需要高度精确且高效的文本去重场景
- 实时性要求较高的系统
假设优点:
- 兼具MinHash和SimHash的优点,既快速又精确
- 适用于大规模且对实时性有要求的文本去重任务
假设缺点:
- 算法复杂度较高,实现难度较大
- 需要更多的计算资源和存储空间
结论
参考链接:https://zhuanlan.zhihu.com/p/43640234
1. 算法步骤
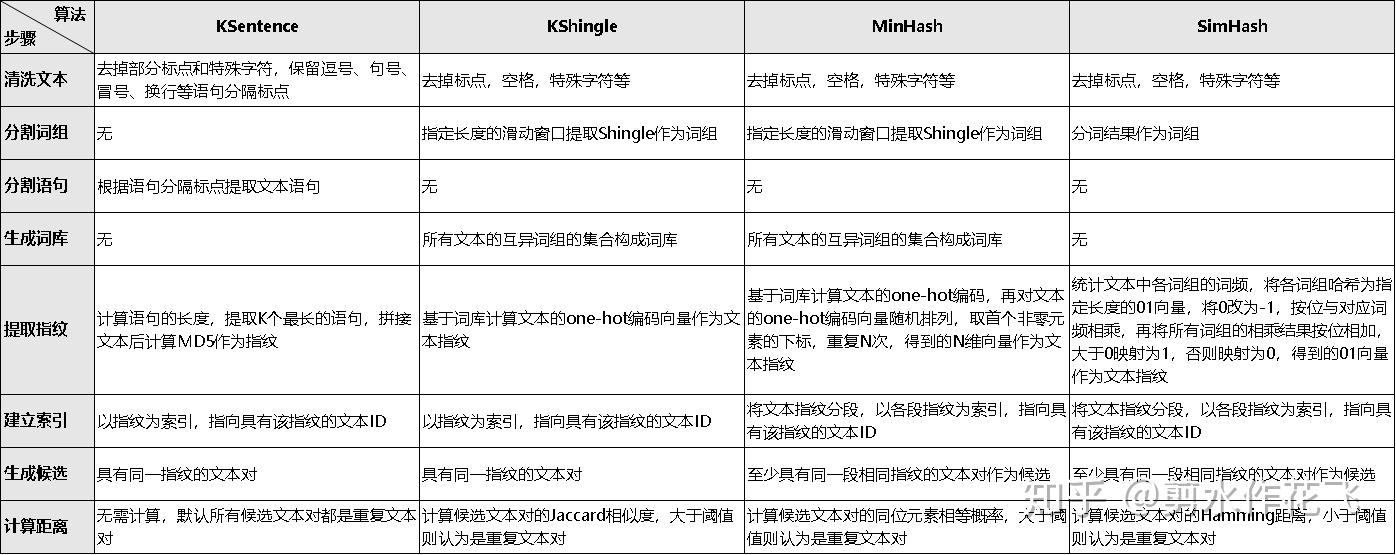
2. 算法评估
实验对比 Minhash、Simhash、KSentence的性能,结果如下:
运行速度:KSentence > Simhash > Minhash
准确率: KSentence > Minhash > Simhash
召回率: Simhash > Minhash > KSentence
工程应用上,海量文本用 Simhash,短文本用Minhash,追求速度用KSentence。
MinHash、SimHash和(假设的)Klongsent算法各有千秋,适用于不同的文本去重场景。在选择算法时,应根据具体需求、数据规模、实时性要求等因素综合考虑。通过合理应用这些算法,我们可以有效地解决文本去重问题,提升数据处理和分析的效率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号