SQLite架构解析与关键函数
SQLite中的B-tree | SQlite源码分析 (huili.github.io)
数据库技术 - 随笔分类(第2页) - YY哥 - 博客园 (cnblogs.com)
SQLite权威指南 - 《SQLite权威指南》 - 书栈网 · BookStack
编程参考:
SQLite学习手册(目录) - OrangeAdmin - 博客园 (cnblogs.com)
一、SQLite 简介
SQLite是一个开源的嵌入式关系数据库,它在2000年由D. Richard Hipp发布,它的减少应用程序管理数据的开销,SQLite可移植性好,很容易使用,很小,高效而且可靠。
SQLite嵌入到使用它的应用程序中,它们共用相同的进程空间,而不是单独的一个进程。从外部看,它并不像一个RDBMS,但在进程内部,它却是完整的,自包含的数据库引擎。
嵌入式数据库的一大好处就是在你的程序内部不需要网络配置,也不需要管理。因为客户端和服务器在同一进程空间运行。SQLite 的数据库权限只依赖于文件系统,没有用户帐户的概念。SQLite 有数据库级锁定,没有网络服务器。它需要的内存,其它开销很小,适合用于嵌入式设备。你需要做的仅仅是把它正确的编译到你的程序。
SQLite 具有以下特点(SQLite’s Features and Philosophy)
1.1、零配置(Zero Configuration)
1.2、可移植(Portability):
它是运行在Windows,Linux,BSD,Mac OS X和一些商用Unix系统,比如Sun的Solaris,IBM的AIX,同样,它也可以工作在许多嵌入式操作系统下,比如QNX,VxWorks,Palm OS, Symbin和Windows CE。
1.3、Compactness:
SQLite是被设计成轻量级,自包含的。one header file, one library, and you’re relational, no external database server required
1.4、简单(Simplicity)
1.5、灵活(Flexibility)
1.6、可靠(Reliability):
SQLite的核心大约有3万行标准C代码,这些代码都是模块化的,很容易阅读。
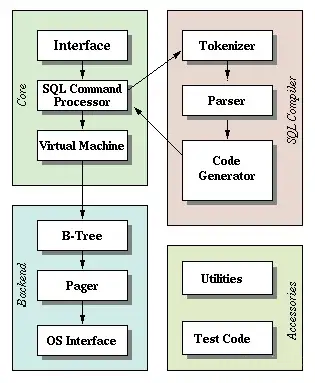
二、架构(architecture)
SQLite采用了模块的设计,它由三个子系统,包括8个独立的模块构成。
SQLite拥有一个精致的、模块化的体系结构,并引进了一些独特的方法进行关系型数据库的管理。
它由被组织在 3 个子系统中的 8 个独立的模块组成,这些模块又被分割为两个部分: 前端解析系统和后端引擎,如图所示。
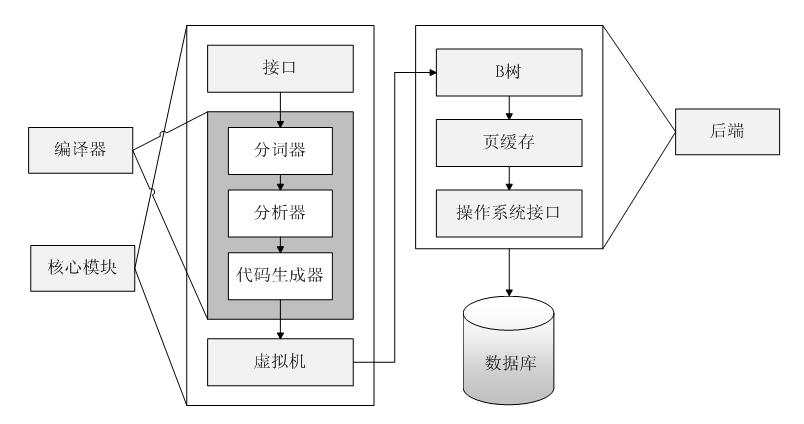
前端预处理应用程序传递过来的SQL语句和SQLite命令,对获取的编码分析、优化,并转换为后端能够执行的SQLite内部字节编码。
前端可分为三个模块:<1> 标示分析;<2>语法分析;<3> 代码生成器。
后端是用来解释字节编码程序的引擎,这个引擎做的才是真正的数据库处理工作。
后端部分由四个模块组成:<1>虚拟机(VM);<2> B/B+树;<3> 页面调度程序(pager);<4>操作系统交界面。
后端实现了 sqlite3_bind_*,sqlite3_setp,sqlite3_coloumn_*,sqlite3_reset和sqlite3_finalize API函数。
这个模型将查询过程划分为几个不连续的任务,就像在流水线上工作一样。在体系结构栈的顶部编译查询语句,在中部执行它,在底部处理操作系统的存储和接口。
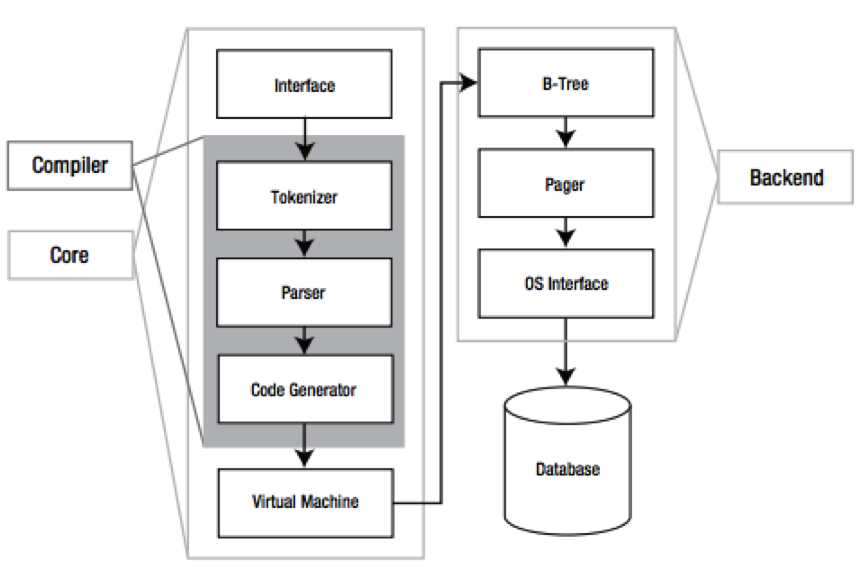
2.1、接口(Interface)
接口由SQLite C API组成,也就是说不管是程序、脚本语言还是库文件,最终都是通过它与SQLite交互的(我们通常用得较多的ODBC/JDBC最后也会转化为相应C API的调用)。
2.2、编译器(Compiler)
在编译器中,分词器(Tokenizer)和分析器(Parser)对SQL进行语法检查,然后把它转化为底层能更方便处理的分层的数据结构---语法树,然后把语法树传给代码生成器(code generator)进行处理。而代码生成器根据它生成一种针对SQLite的汇编代码,最后由虚拟机(Virtual Machine)执行。
2.3、虚拟机(Virtual Machine)
架构中最核心的部分是虚拟机,或者叫做虚拟数据库引擎(Virtual Database Engine,VDBE)。它和Java虚拟机相似,解释执行字节代码。VDBE的字节代码由128个操作码(opcodes)构成,它们主要集中在数据库操作。它的每一条指令都用来完成特定的数据库操作(比如打开一个表的游标)或者为这些操作栈空间的准备(比如压入参数)。总之,所有的这些指令都是为了满足SQL命令的要求(关于VM,后面会做详细介绍)。
2.4、后端(Back-End)
后端由B-树(B-tree),页缓存(page cache,pager)和操作系统接口(即系统调用)构成。B-tree和page cache共同对数据进行管理。B-tree的主要功能就是索引,它维护着各个页面之间的复杂的关系,便于快速找到所需数据。而pager的主要作用就是通过OS接口在B-tree和Disk之间传递页面。
二、编译器(Compiler)
2.1、分词器(Tokenizer)
接口把要执行的SQL语句传递给分词器 (Tokenizer) Tokenizer按照SQL的词法定义把它切分一个一个的词,并传递给分析器 (Parser) 进行语法分析。分词器是手工写的,主要在 Tokenizer.c 中实现。
2.2、分析器(Parser)
SQLite的语法分析器是用 Lemon—— 一个开源的LALR(1)语法分析器的生成器,生成的文件为 parser.c。
一个简单的语法树:
SELECT rowid, name, season FROM episodes WHERE rowid=1 LIMIT 1
2.3、代码生成器(Code Generator)
代码生成器是SQLite中最庞大,最复杂的部分。它与Parser关系紧密,根据语法分析树 生成VDBE程序执行SQL语句的功能。
由诸多文件构成:trigger.c, update.c, insert.c, delete.c, select.c, where.c等文件。这些文件生成相应的VDBE程序指令,比如SELECT语句就由select.c生成。下面是一个读操作中打开表的代码的生成实现:
/* Generate code that will open a table for reading.
*/
void sqlite3OpenTableForReading(
Vdbe *v, /* Generate code into this VDBE */
int iCur, /* The cursor number of the table */
Table *pTab /* The table to be opened */
){
sqlite3VdbeAddOp(v, OP_Integer, pTab->iDb, 0);
sqlite3VdbeAddOp(v, OP_OpenRead, iCur, pTab->tnum);
VdbeComment((v, "# %s", pTab->zName));
sqlite3VdbeAddOp(v, OP_SetNumColumns, iCur, pTab->nCol);
}
Sqlite3vdbeAddOp* 函数有三个参数:(1)VDBE实例(它将添加指令),(2)操作码(一条指令),(3)两个操作数。
Sqlite3vdbeAddOp0/1/2/3/4
2.4、查询优化
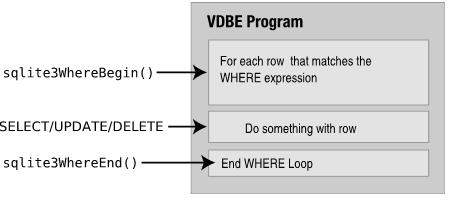
代码生成器不仅负责生成代码,也负责进行查询优化。主要的实现位于where.c中,生成的WHERE语句块通常被其它模块共享,比如select.c,update.c以及delete.c。
这些模块调用 sqlite3WhereBegin() 开始WHERE语句块的指令生成,然后加入它们自己的VDBE代码返回,最后调用 sqlite3WhereEnd() 结束指令生成,如下:
三、SQLite数据库的存储机制
SQLite文件格式分析_v102 - 百度文库 (baidu.com)
SQLite是一种轻量级的嵌入式数据库系统,被广泛应用于各种移动设备和桌面应用程序中。下面学习SQLite数据库的存储机制,并介绍其相对于其他数据库系统的优势。通过深入了解SQLite的存储机制,我们可以更好地理解它在实际应用中的表现和优势。
文件存储结构:SQLite数据库以单个文件的形式存储,这个文件包含了所有的表、索引、触发器等数据库对象。这种文件存储结构使得SQLite非常适合嵌入式设备和桌面应用程序,因为它不需要独立的服务器进程和额外的配置。
数据页:SQLite将数据分成固定大小的数据页(通常为4KB(4096)),每个数据页中包含了多个数据行。这种数据页的存储方式使得SQLite能够高效地处理大规模数据集,同时还能够减少磁盘IO的次数,提高数据库性能。
B树索引与表:B-Tree树用于存储索引, B+Tree树用于存储表。SQLite使用B树索引来加速数据的检索。B树索引以平衡树的形式存储索引数据,可以快速定位到特定的数据行。SQLite支持多种类型的索引,包括普通索引、唯一索引和全文索引等。
数据编码:SQLite使用变长整数编码、浮点数编码和字符串编码等方式来存储数据。这种数据编码方式既节省了存储空间,又提高了数据访问的效率。
B-tree和Pager
B-Tree使得VDBE可以在O(logN)下查询,插入和删除数据,以及O(1)下双向遍历结果集。B-Tree不会直接读写磁盘,它仅仅维护着页面(pages)之间的关系。当B-TREE需要页面或者修改页面时,它就会调用Pager。当修改页面时,pager保证原始页面首先写入日志文件,当它完成写操作时,pager根据事务状态决定如何做。B-tree不直接读写文件,而是通过page cache这个缓冲模块读写文件对于性能是有重要意义的(注:这和操作系统读写文件类似,在Linux中,操作系统的上层模块并不直接调用设备驱动读写设备,而是通过一个高速缓冲模块调用设备驱动读写文件,并将结果存到高速缓冲区)。
3.1、数据库文件格式(Database File Format)
数据库中所有的页面都按从1开始顺序标记。一个数据库由许多B-tree构成——每一个表和索引都有一个B-tree
(注:索引采用B-tree,而表采用B+tree,这主要是表和索引的需求不同以及B-tree和B+tree的结构不同决定的:B+tree的所有叶子节点包含了全部关键字信息,而且可以有两种顺序查找——具体参见《数据结构》,严蔚敏。而B-tree更适合用来作索引)。所有表和索引的根页面都存储在sqlite_master表中。
数据库中第一个页面(page 1)有点特殊,page 1的前100个字节包含一个描述数据库文件的特殊的文件头。它包括库的版本,模式的版本,页面大小,编码等所有创建数据库时设置的参数。这个特殊的文件头的内容在btree.c中定义,page 1也是sqlite_master表的根页面。
3.2、页面重用及回收(Page Reuse and Vacuum )
SQLite利用一个空闲列表(free list)进行页面回收。当一个页面的所有记录都被删除时,就被插入到该列表。当运行VACUUM命令时,会清除free list,所以数据库会缩小,本质上它是在新的文件重新建立数据库,而所有使用的页在都被拷贝过去,而free list却不会,结果就是一个新的,变小的数据库。当数据库的autovacuum开启时,SQLite不会使用free list,而且在每一次commit时自动压缩数据库。
3.3、B-Tree记录(索引和表)
B-tree中页面由B-tree记录组成,也叫做payloads。每一个B-tree记录,或者payload有两个域:关键字域(key field)和数据域(data field)。Key field就是ROWID的值,或者数据库中表的关键字的值。从B-tree的角度,data field可以是任何无结构的数据。数据库的记录就保存在这些data fields中。B-tree的任务就是排序和遍历,它最需要就是关键字。Payloads的大小是不定的,这与内部的关键字和数据域有关,当一个payload太大不能存在一个页面内进便保存到多个页面。
B+Tree按关键字排序,所有的关键字必须唯一。表采用B+tree,内部页面不包含数据,如下:
B+tree中根页面(root page)和内部页面(internal pages)都是用来导航的,这些页面的数据域都是指向下级页面的指针,仅仅包含关键字。所有的数据库记录都存储在叶子页面(leaf pages)内。在叶节点一级,记录和页面都是按照关键字的顺序的,所以B-tree可以水平方向遍历,时间复杂度为O(1)。
3.3.1 B-Tree 与 B+-Tree
SQLite 使用 B-Tree 存储索引,一个 B-Tree 对应一个索引;使用 B+-Tree 存储表,一个 B+-Tree 对应一个表。Tree 创建时就会为其分配一个根 Page(对应一个 Page Number),Page 标识了该 Tree,Tree 的根 Page 在 其生命周期内不会发生变更。
3.3.2 B-tree 索引
在基于 DBMSs 的外存储领域中,B-tree 在一个非常重要的索引结构,即索引采用B-treee,按键所对应的值有序地存储记录集合。B-tree 是一种特殊的高度平衡树,n-ary, n > 2,所有叶子节点必须在统一层上。
实体(Entries[*])和搜索信息(如 key values)可存储在 B-tree 的内部节点和叶子节点。B-tree在所有的树操作(即插入、删除、搜索和下一个搜索)中,提供了近乎最佳的性能。
为了避免混淆,我在这里使用术语“entry”表示元组或记录。entry 由键和其它可选数据组成。
B-tree页面由B-tree记录组成,B-tree记录也叫做payloads。每一个B-tree记录(payload)有两个域:关键字域(key field)和数据域(data field)。Key field就是rowid的值,或者数据库中表的关键字的值。
从B-tree的角度,data field可以是任何无结构的数据。数据库的记录就保存在这些data fields中。B-tree的任务就是排序和遍历,它最需要的是关键字。Payloads的大小是不定的,这与内部的关键字和数据域有关,当一个payload太大不能存在一个页面内,便保存到多个页面。
3.3.3 B+-Tree 表
B+-Tree 是 B-tree 的变种。B+Tree按关键字排序,所有的关键字必须唯一。表采用B+tree,内部页面不包含数据,如下:
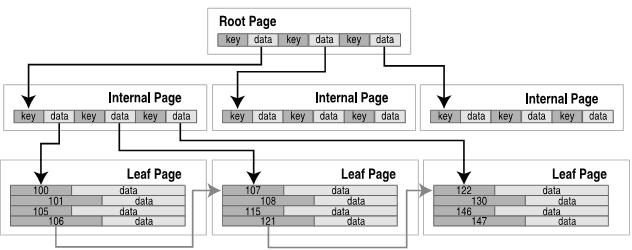
B+tree中根页面(root page)和内部页面(internal pages)都是用来导航的,这些页面的数据域都是指向下级页面的指针,仅仅包含关键字。
所有的数据库记录都存储在叶子页面(leaf pages)内。在叶节点一级,记录和页面都是按照关键字的顺序的,所以B+tree可以水平方向遍历,时间复杂度为O(1)。
所有的实体 entries 都在叶子节点上,内部节点只包含有序的搜索信息(key values)和子节点指针。entries 是 (key value, data value) 对,按 key 值排序。
B-Tree 和 B+-Tree 的内部页节点的子指针数量,在一个预设的范围内[lower, upper](2 * lower >= upper),都是可变的。根页节点可能不符合这个规则,可能有任何数量的子指针即[0, upper]。所有的叶子节点都在同一个最低层上,可以构成一个有序的链表。
upper = n +1 的 B+-Tree ,内部节点最多有n 个 keys,n+1 个子节点指针。对于任何内部节点,其对空间划为为 [<= Key(0), Key (0) < & <=Key(1), ..., Key (n - 1)<]。这样查询任何一条记录只需要遍历 O(log m) (m 是树中所有实体的数量)个节点。
3.4、记录和域(Records and Fields)
位于叶节点页面的数据域的记录(Payload) 由VDBE管理,数据库记录以二进制的形式存储,但有一定的数据格式。
在VDBE虚拟机引擎中创建记录,调用关系:sqlite3_step() -> sqlite3VdbeExec(操作码:OP_MakeRecord) ->
zHdr = (u8 *)pOut->z;
zPayload = zHdr + nHdr;
记录(Payload)格式包括一个逻辑头(logical header)和一个数据区(data segment),header segment包括header的大小和一个数据类型数组,数据类型用来在data segment的数据的类型,如下:


sqlite3_column_type()函数返回第N列的值的数据类型. 具体的返回值如下: #define SQLITE_INTEGER 1 #define SQLITE_FLOAT 2 #define SQLITE_TEXT 3 #define SQLITE_BLOB 4 #define SQLITE_NULL 5 sqlite3_column_count()函数返回结果集中包含的列数
3.5、层次数据组织(Hierarchical Data Organization)

从上往下,数据越来越无序,从下向上,数据越来越结构化.
3.6、B-Tree API
B-Tree模块有它自己的API,它可以独立于C API使用。另一个特点就是它支持事务。由pager处理的事务,锁和日志都是为B-tree服务的。根据功能可以分为以下几类:
2.6.1、访问和事务函数
sqlite3BtreeOpen: Opens a new database file. Returns a B-tree object. sqlite3BtreeClose: Closes a database. sqlite3BtreeBeginTrans: Starts a new transaction. sqlite3BtreeCommit: Commits the current transaction. sqlite3BtreeRollback: Rolls back the current transaction. sqlite3BtreeBeginStmt: Starts a statement transaction. sqlite3BtreeCommitStmt: Commits a statement transaction. sqlite3BtreeRollbackStmt: Rolls back a statement transaction.
3.6.2、表函数
sqlite3BtreeCreateTable: Creates a new, empty B-tree in a database file. sqlite3BtreeDropTable: Destroys a B-tree in a database file. sqlite3BtreeClearTable: Removes all data from a B-tree, but keeps the B-tree intact.
3.6.3、游标函数(Cursor Functions)
sqlite3BtreeCursor: Creates a new cursor pointing to a particular B-tree. sqlite3BtreeCloseCursor: Closes the B-tree cursor. sqlite3BtreeFirst: Moves the cursor to the first element in a B-tree. sqlite3BtreeLast: Moves the cursor to the last element in a B-tree. sqlite3BtreeNext: Moves the cursor to the next element after the one it is currently pointing to. sqlite3BtreePrevious: Moves the cursor to the previous element before the one it is currently pointing to. sqlite3BtreeMoveto: Moves the cursor to an element that matches the key value passed in as a parameter.
3.6.4、记录函数(Record Functions)
sqlite3BtreeDelete: Deletes the record that the cursor is pointing to. sqlite3BtreeInsert: Inserts a new element in the appropriate place of the B-tree. sqlite3BtreeKeySize: Returns the number of bytes in the key of the record that the cursor is pointing to. sqlite3BtreeKey: Returns the key of the record the cursor is currently pointing to. sqlite3BtreeDataSize: Returns the number of bytes in the data record that the cursor is currently pointing to. sqlite3BtreeData: Returns the data in the record the cursor is currently pointing to.
3.6.5、配置函数(Configuration Functions)
sqlite3BtreeSetCacheSize: Controls the page cache size as well as the synchronous writes (as defined in the synchronous pragma). sqlite3BtreeSetSafetyLevel: Changes the way data is synced to disk in order to increase or decrease how well the database resists damage due to OS crashes and power failures. Level 1 is the same as asynchronous (no syncs() occur and there is a high probability of damage). This is the equivalent to pragma synchronous=OFF. Level 2 is the default. There is a very low but non-zero probability of damage. This is the equivalent to pragma synchronous=NORMAL. Level 3 reduces the probability of damage to near zero but with a write performance reduction. This is the equivalent to pragma synchronous=FULL. sqlite3BtreeSetPageSize: Sets the database page size. sqlite3BtreeGetPageSize: Returns the database page size. sqlite3BtreeSetAutoVacuum: Sets the autovacuum property of the database. sqlite3BtreeGetAutoVacuum: Returns whether the database uses autovacuum. sqlite3BtreeSetBusyHandler: Sets the busy handler
3.7、实例分析
最后以sqlite3_open的具体实现结束本节的讨论(参见Version 3.6.10的源码):

由上图可以知道,SQLite的所有IO操作,最终都转化为操作系统的系统调用(一名话:DBMS建立在痛苦的OS之上)。同时也可以看到SQLite的实现非常的层次化,模块化,使得SQLite更易扩展,可移植性非常强。
附录 A: 源代码文件结构
|
Version 3.3.6源代码文件结构 ——整理: 2009-2-19 https://www.cnblogs.com/hustcat |
|||
|
文件名称 |
大小byte |
函数 |
|
|
API部分 |
|||
|
main.c |
35414 |
SQLite Library的大部分接口 |
数据库连接对象:sqlite3
预编译语句对象:sqlite3_stmt |
|
legacy.c |
3734 |
sqlite3_exec()的实现 |
严格来说,不需要预编译语句对象,因为可以使用便捷包装器接口 sqlite3_exec() 或 sqlite3_get_table(),这些便捷包装器封装并隐藏了预编译语句对象。但是,需要了解预编译语句才能充分利用 SQLite。 |
|
table.c |
5464 |
sqlite3_get_table() and sqlite3_free_table()的实现, 它们是sqlite3_exec的包装 |
数据库连接和预编译语句对象由下面列出的少量 C/C++ 核心接口例程控制。
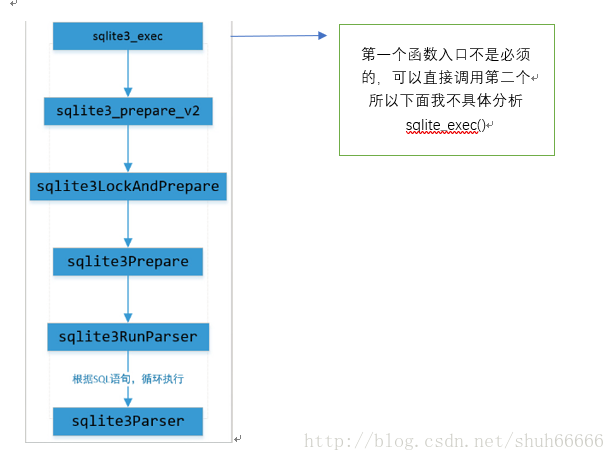
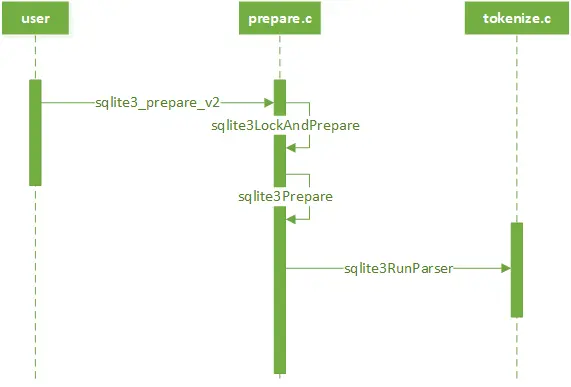
1. main.c::sqlite3_open() //创建单个数据库连接 2. 使用 prepare.c::sqlite3_prepare() 创建一个预编译语句(vdbe字节程序)。 |
|
preprare.c |
17983 |
主要实现sqlite3_prepare_v2(): 预处理语句对象 sqlite3_stmt 的构造函数, 将SQL语句 编译成字节码程序: 一个语句(sqlite_stmt)会编译为一个完整的VDBE程序,执行一条单独的SQL命令。 字节代码在内存中被封装成 sqlite3_stmt 对象 注意:sqlite3_prepare()工作于开始阶段,用于产生VDBE代码,它不参与执行。 所有SQL命令的VDBE程序,都可以通过EXPLAIN命令得到; |
SQLite 把 SQL 语句在运行时编译成字节码 bytecode,然后使用虚拟机,控制字节码的执行。 使用 sqlite3_prepare_v2() 将编译好的vdbe字节码程序,封装在 sqlite3_stmt 结构体中。 一个 sqlite3_stmt 结构体对应一个 SQL 语句,可使用 sqlite3_reset() 终结当前语句的执行并重置语句到初始状态、通过绑定函数(sqlite3_bind_*)和步进函数(sqlite3_step)实现编译字节码复用。不再使用的sqlite3_stmt 可使用 sqlite3_finalize 销毁。 |
|
|
|
|
|
|
分词器部分(Tokenizer) |
|||
|
tokenize.c |
14495 |
分词器的实现 sqlite3RunParser() -> sqlite3GetToken() |
|
|
解析器部分(Parser),语法分析器 Parser 根据上下文,把语义给予 Tokenizer 产生的各个标号,并构建解析树。SQLite 中的 Parser 是使用 Lemon parser generator 生成的。Lemon 所做的工作与 YACC/BISON 相同,但使用一个出错少的输入语法。Tokenizer 也是使用 Lemon 产生的,可重入且线程安全。
|
|||
|
parser.c |
116917 |
分析器的实现,由Lemon实现 sqlite3Parser() |
|
|
parser.h |
6847 |
分析器内部定义的关键字 |
|
|
|
|
|
|
|
代码生成器部分(Code Generator) 字节码产生器会分析 Parser 产生的解析树,产生 bytecode (存储在 prepared statement 中),进而把各个独立的字节码传递给虚拟机,由虚拟机控制字节码的执行,完成 SQL 语句所表示的行为。
|
|||
|
update.c |
23878 |
处理UPDATTE语句 sqlite3Update() |
|
|
delete.c |
21978 |
处理DELETE语句 sqlite3DeleteFrom() |
|
|
insert.c |
62026 |
处理INSERT语句 sqlite3Insert() |
|
|
trigger.c |
29065 |
处理TRIGGER语句 |
|
|
attach.c |
15941 |
处理ATTACHT 和DEATTACH语句 |
文件 attach.c, delete.c, insert.c, select.c, trigger.cupdate.c, 和 vacuum.c 处理对应名称的语句的字节码产生(可能调用expr.c 和 where.c) |
|
where.c |
75826 |
处理WHERE语句, |
where*.c 处理SELECT, UPDATE 和 DELETE的 WHERE 子句的字节码生成;此外还有“查询优化” |
|
select.c |
112084 |
处理SELECT语句,sqlite3Select() |
代码产生器中,尤其是 where*.c 和 select.c 中的逻辑,有时被称为查询优化器 query planner。
对于特定 SQL 语句,可能有成百上千种不同的算法去实现。query planner 可为特定的 SQL 语句选择最好的算法。 |
|
vacuum.c |
11005 |
处理VACUUM语句 |
|
|
pragma.c |
34289 |
处理PRAGMA命令 |
|
|
expr.c |
73963 |
处理SQL语句中的表达式 |
|
|
auth.c |
7496 |
主要实现 sqlite3_set_authorizer() |
|
|
analyze.c |
13149 |
实现ANALYZE命令 |
|
|
alter.c |
18414 |
实现ALTER TABLE功能 |
|
|
build.c |
104052 |
处理以下语法: CREATE TABLE DROP TABLE CREATE INDEX DROP INDEX creating ID lists BEGIN TRANSACTION COMMIT ROLLBACK |
其它语句都由 build.c 控制生成字节码 |
|
func.c |
34335 |
实现SQL语句的函数语句 |
|
|
date.c |
24031 |
与日期和时间转换有关的函数 |
|
|
虚拟机部分(Virtual Machine) 字节码引擎 Bytecode Engine:bytecode程序运行在字节码虚拟机上 |
|||
|
vdbeapi.c |
23300 |
虚拟机提供上层模块调用的API实现部分, |
vdbeapi.c 定义外部使用虚拟机的接口 sqlite3_step() 负责评估和执行预编译语句(VDBE字节程序)
|
|
vdbe.c |
143552 |
虚拟机的主要实现部分 |
vdbe.c 虚拟机主体实现文件,调用关系如下 sqlite3_step() -> sqlite3VdbeExec() |
|
vdbe.h |
5309 |
定义了VDBE的接口,VdbeOp结构体(代表一条指令) |
vdbe.h 虚拟与 SQLite 库之间的接口, |
|
vdbeaux.c |
58741 |
Vdbe.h的接口的实现 |
vdbeaux.c 包含被其它 SQLite library(如虚拟机和接口模块)使用的工具,用来构建 VM 程序 |
|
vdbeInt.h |
17595 |
Vdbe.c的私有头文件,定义了VDBE常用的数据结构: Cursor——虚拟机中使用的游标 Mem——vdbe在内部把所有的SQL值当作一个Mem数据结构来处理 Vdbe——虚拟机数据结构 |
vdbeInt.h 定义虚拟机私有的接口和结构体 |
|
vdbemem.c |
26375 |
操作”Mem”数据结构的函数 |
vdbemem.c 各种数据类型(strings, integer, floating point numbers, and BLOBs) 在虚拟机中的存储对象,"Mem" |
|
vdbefifo.c |
2927 |
|
vdbe*.c 定义各种虚拟机帮助函数 func.c SQLite 使用 C 历程实现的 SQL 函数,如abs(), count(), substr() |
|
|
|
|
|
|
B-Tree部分 |
|||
|
btree.h |
5260 |
头文件,定义了B-tree提供的操作接口: 供VDBE调用,关系如下: |
B-tree 模块以固定大小的页,向磁盘请求信息,在磁盘上,SQLite 使用 B-tree 维护数据(btree.c),一个表或索引对应一个独立 B-tree,所有的 B-tree 都在一个库文件中。 数据库文件格式 file format 定义十分稳定,具有非常好的兼容性。B-tree 子系统接口和 SQLite 库的其它接口在 btree.h 中。 |
|
btree.c |
215570 |
B-Tree部分的主要实现,并定义了以下数据结构: Btree——Btree handler BtCursor——使用的游标 BtLock——锁 BtShared——包含了一个打开的数据库的所有信息 MemPage——文件在内存存放在该数据结构中 CellInfo ——btreeParseCellPtr () 函数使用之间从磁盘读出来的信息填充该字段 |
struct Btree:一个数据库连接(sqlite3 指针)对应一个 struct Btree 对象,指向共享的struct BtShared 对象。 struct BtShared:一个对象代表一个数据库文件 sqlite3.mutex 为其各个字段的访问提供线程安全。如果开启共享缓存,使用 BtLock lock 字段控制首页的安全。 struct MemPage:页加载到内存中后,pager 会创建一个 MemPage 对象并把其前8个字节设置为0,使用磁盘上的原始页的内容信息填充该对象。通过 BtShared *pBt 互斥信号为其提供线程安全;DbPage *pDbPage 字段是控制页的具柄。 struct BtLock:存储在 BtShared.pLock 中的锁列表。使用表 BtShared.iTable 的根页打开游标时,向 BtShared.pLock列表添加一个 BtLock 对象,事物提交、回滚后或 Btree 关闭后移除该对象 BtCursor:一个指向 b-tree 中的特定记录 (entry) 的指针。通过 MemPage 和 MemPage 中记录的下标识别记录。一个 BtCursor 对应一个 Btree,BtCursor 列表存储在 BtShared 中;BtShared.mutex 为字段访问提供安全; |
|
|
|
|
|
|
Pager部分 |
|||
|
pager.h |
4161 |
定义sqlite page cache子系统提供的接口 |
默认为 4096 字节,域值为 {512,65536}。Page Cache 负责页的读、写和缓存,提供回滚和原子提交抽象,负责库文件锁操作。 B-tree 驱动器向 Page Cache 请求特定的页,并当它想修改页、提交或是回滚页时通知 Page Cache 。Page Cache 处理所有的细节,确保快速、安全且高效的完成请求。 |
|
pager.c |
127490 |
Pager模块的主要实现,并定义了以下数据结构: PgHdr——每一个内存中的页面的页面头 Pager——该模块中最重要的数据结构 PgHistory |
Page Cache 主要在 pager.c 文件中实现;WAL mode 逻辑在 wal.c 中;内存缓存由 pcache.c 和 pcache1.c 共同实现;page cache子系统和SQLite 其它模块之间的接口定义在 pager.h 中。B-tree 模块以固定大小的页,向磁盘请求信息,默认为 4096 字节,域值为 {512,65536}。Page Cache 负责页的读、写和缓存,提供回滚和原子提交抽象,负责库文件锁操作。
B-tree 驱动器向 Page Cache 请求特定的页,并当它想修改页、提交或是回滚页时通知 Page Cache 。Page Cache 处理所有的细节,确保快速、安全且高效的完成请求。 Page Cache 主要在 pager.c 文件中实现;WAL mode 逻辑在 wal.c 中;内存缓存由 pcache.c 和 pcache1.c 共同实现;page cache子系统和SQLite 其它模块之间的接口定义在 pager.h 中。 |
|
|
|
|
|
|
OS Interface部分 |
|||
|
os.h |
18355 |
定义了为上层模块提供的操作函数,并定义了以下数据结构: OsFile——描述一个文件 IoMethod——OsFile所支持的操作函数(对所有架构都适用的OS Interface) |
SQLite 使用抽象对象 VFS,保证跨系统的移植性。VFS 提供的方法有:opening, read, writing, 和 closing 磁盘上的文件; 其它系统特定的任务,如 finding the current time, obtaining randomness to initialize the built-in pseudo-random number generator。 |
|
os.c |
2866 |
对IoMethod中的函数的包装 |
|
|
os_win.c |
42975 |
Windows平台下的OS Interface |
|
|
os_unix.c |
60831 |
Unix平台下的OS Interface |
|
|
os_os2.c |
28451 |
OS2平台下的OS Interface |
|
|
|
|
|
|
|
实用工具部分 |
|||
|
utf.c |
20891 |
与UTF编码、Unicode 转换子程序 |
|
|
util.c |
43575 |
一些实用函数,比如: sqlite3Malloc(),sqlite3FreeX() |
|
|
sqlite3.h |
63873 |
SQLite的头文件,定义了提供给应用使用的API和数据结构。 |
|
|
sqliteInt.h |
78886 |
定义了SQLite内部使用的接口和数据结构 |
|
|
printf.c |
29556 |
主要实现与自定义 printf 有关函数 |
|
|
random.c |
3078 |
伪随机数 PRNG 生成器 |
|
|
hash.c |
11896 |
解析器使用的hash表 |
|
|
hash.h |
4033 |
Hash 表头文件 |
|

 浙公网安备 33010602011771号
浙公网安备 33010602011771号