mysql事务隔离级别详解和实战
A事务做了操作 没有提交 对B事务来说 就等于没做 获取的都是之前的数据
但是 在A事务中查询的话 查到的都是操作之后的数据
没有提交的数据只有自己看得到,并没有update到数据库。
查看InnoDB存储引擎 系统级的隔离级别 和 会话级的隔离级别:

mysql> select @@global.tx_isolation,@@tx_isolation; +-----------------------+-----------------+ | @@global.tx_isolation | @@tx_isolation | +-----------------------+-----------------+ | REPEATABLE-READ | REPEATABLE-READ | +-----------------------+-----------------+ 1 row in set (0.00 sec)
设置innodb的事务级别方法是:set 作用域 transaction isolation level 事务隔离级别,例如~
SET [SESSION | GLOBAL] TRANSACTION ISOLATION LEVEL {READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE}
mysql> set global transaction isolation level read committed; //全局的
mysql> set session transaction isolation level read committed; //当前会话
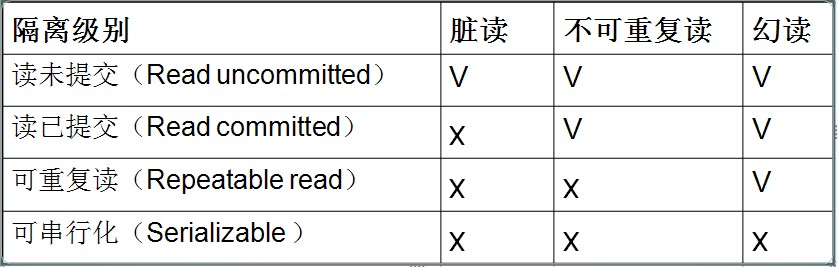
SQL标准定义了4类隔离级别,包括了一些具体规则,用来限定事务内外的哪些改变是可见的,哪些是不可见的。低级别的隔离级一般支持更高的并发处理,并拥有更低的系统开销。
Read Uncommitted(读取未提交内容)
在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少。读取未提交的数据,也被称之为脏读(Dirty Read)。
Read Committed(读取提交内容)
这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)。它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变。这种隔离级别 也支持所谓的不可重复读(Nonrepeatable Read),因为同一事务的其他实例在该实例处理其间可能会有新的commit,所以同一select可能返回不同结果。
Repeatable Read(可重读)
这是MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不过理论上,这会导致另一个棘手的问题:幻读 (Phantom Read)。简单的说,幻读指当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行。InnoDB和Falcon存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题。
Serializable(可串行化)
这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。
这四种隔离级别采取不同的锁类型来实现,若读取的是同一个数据的话,就容易发生问题。例如:
脏读(Drity Read):某个事务已更新一份数据,另一个事务在此时读取了同一份数据,由于某些原因,前一个RollBack了操作,则后一个事务所读取的数据就会是不正确的。
不可重复读(Non-repeatable read):在一个事务的两次查询之中数据不一致,这可能是两次查询过程中间插入了一个事务更新的原有的数据。
幻读(Phantom Read):在一个事务的两次查询中数据笔数不一致,例如有一个事务查询了几列(Row)数据,而另一个事务却在此时插入了新的几列数据,先前的事务在接下来的查询中,就会发现有几列数据是它先前所没有的。
在MySQL中,实现了这四种隔离级别,分别有可能产生问题如下所示:
InnoDB引擎的锁机制
(之所以以InnoDB为主介绍锁,是因为InnoDB支持事务,支持行锁和表锁用的比较多,Myisam不支持事务,只支持表锁)
共享锁(S):允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁。
排他锁(X):允许获得排他锁的事务更新数据,阻止其他事务取得相同数据集的共享读锁和排他写锁。
意向共享锁(IS):事务打算给数据行加行共享锁,事务在给一个数据行加共享锁前必须先取得该表的IS锁。
意向排他锁(IX):事务打算给数据行加行排他锁,事务在给一个数据行加排他锁前必须先取得该表的IX锁。
说明:
1)共享锁和排他锁都是行锁,意向锁都是表锁,应用中我们只会使用到共享锁和排他锁,意向锁是mysql内部使用的,不需要用户干预。
2)对于UPDATE、DELETE和INSERT语句,InnoDB会自动给涉及数据集加排他锁(X);对于普通SELECT语句,InnoDB不会加任何锁,事务可以通过以下语句显示给记录集加共享锁或排他锁。
共享锁(S):SELECT * FROM table_name WHERE ... LOCK IN SHARE MODE。
排他锁(X):SELECT * FROM table_name WHERE ... FOR UPDATE。
3)InnoDB行锁是通过给索引上的索引项加锁来实现的,因此InnoDB这种行锁实现特点意味着:只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁!。
在 MySQL中的行级锁,表级锁,页级锁中介绍过,行级锁是Mysql中锁定粒度最细的一种锁,行级锁能大大减少数据库操作的冲突。行级锁分为共享锁和排他锁两种,本文将详细介绍共享锁及排他锁的概念、使用方式及注意事项等。
共享锁(Share Lock)
共享锁又称读锁,是读取操作创建的锁。其他用户可以并发读取数据,但任何事务都不能对数据进行修改(获取数据上的排他锁),直到已释放所有共享锁。
如果事务T对数据A加上共享锁后,则其他事务只能对A再加共享锁,不能加排他锁。获得共享锁的事务只能读数据,不能修改数据。
用法
SELECT ... LOCK IN SHARE MODE;
在查询语句后面增加 LOCK IN SHARE MODE,Mysql会对查询结果中的每行都加共享锁,当没有其他线程对查询结果集中的任何一行使用排他锁时,可以成功申请共享锁,否则会被阻塞。其他线程也可以读取使用了共享锁的表,而且这些线程读取的是同一个版本的数据。
排他锁(eXclusive Lock)
共享锁又称写锁,如果事务T对数据A加上排他锁后,则其他事务不能再对A加任何类型的锁,其它事务也不能对A做update,insert,delete操作,因为在innodb中这些操作默认加了排他锁,可以进行select 操作因为查询的时候是不加任何锁的。
用法
SELECT ... FOR UPDATE;
在查询语句后面增加 FOR UPDATE,Mysql会对查询结果中的每行都加排他锁,当没有其他线程对查询结果集中的任何一行使用排他锁时,可以成功申请排他锁,否则会被阻塞。
意向锁
InnoDB还有两个表锁:
意向共享锁(IS):表示事务准备给数据行加入共享锁,也就是说一个数据行加共享锁前必须先取得该表的IS锁
意向排他锁(IX):类似上面,表示事务准备给数据行加入排他锁,说明事务在一个数据行加排他锁前必须先取得该表的IX锁。
意向锁是InnoDB自动加的,不需要用户干预。
对于insert、update、delete,InnoDB会自动给涉及的数据加排他锁(X);对于一般的Select语句,InnoDB不会加任何锁,事务可以通过以下语句给显示加共享锁或排他锁。
共享锁: SELECT ... LOCK IN SHARE MODE;
排他锁: SELECT ... FOR UPDATE;
注意事项
行级锁与表级锁
行级锁都是基于索引的,如果一条SQL语句用不到索引是不会使用行级锁的,会使用表级锁。行级锁的缺点是:由于需要请求大量的锁资源,所以速度慢,内存消耗大。
行级锁与死锁
MyISAM中是不会产生死锁的,因为MyISAM总是一次性获得所需的全部锁,要么全部满足,要么全部等待。而在InnoDB中,锁是逐步获得的,就造成了死锁的可能。
在MySQL中,行级锁并不是直接锁记录,而是锁索引。索引分为主键索引和非主键索引两种,如果一条sql语句操作了主键索引,MySQL就会锁定这条主键索引;如果一条语句操作了非主键索引,MySQL会先锁定该非主键索引,再锁定相关的主键索引。 在UPDATE、DELETE操作时,MySQL不仅锁定WHERE条件扫描过的所有索引记录,而且会锁定相邻的键值,即所谓的next-key locking。
当两个事务同时执行,一个锁住了主键索引在等待其他相关索引,一个锁定了非主键索引,在等待主键索引。这样就会发生死锁。
发生死锁后,InnoDB一般都可以检测到,并使一个事务释放锁回退,另一个获取锁完成事务。
有多种方法可以避免死锁,这里只介绍常见的三种
1、如果不同程序会并发存取多个表,尽量约定以相同的顺序访问表,可以大大降低死锁机会。
2、在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁产生概率;
3、对于非常容易产生死锁的业务部分,可以尝试使用升级锁定颗粒度,通过表级锁定来减少死锁产生的概率;
实战:
数据库隔离级别有四种,应用《高性能mysql》一书中的说明:


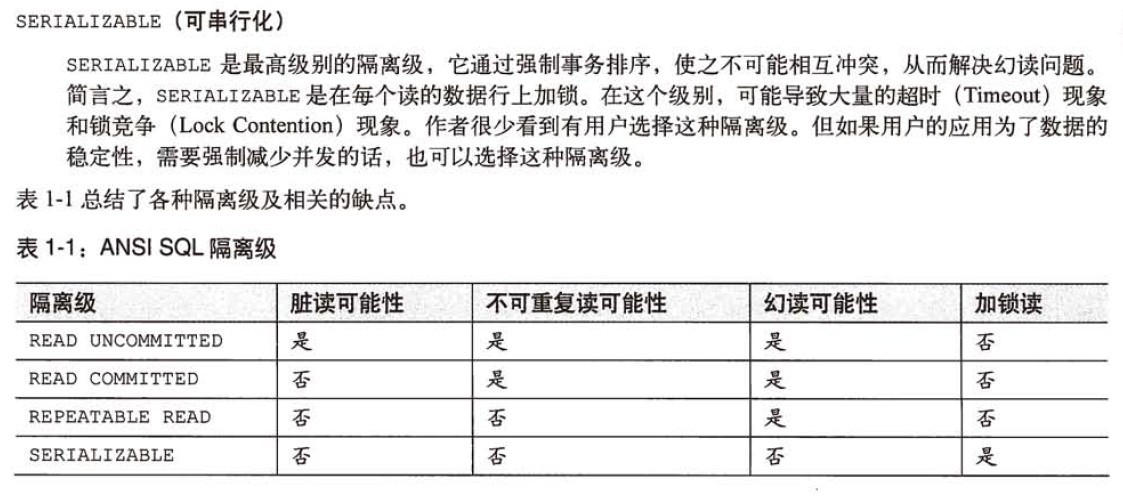
然后说说修改事务隔离级别的方法:
1.全局修改,修改mysql.ini配置文件,在最后加上
#可选参数有:READ-UNCOMMITTED, READ-COMMITTED, REPEATABLE-READ, SERIALIZABLE.
[mysqld]
transaction-isolation = REPEATABLE-READ
这里全局默认是REPEATABLE-READ,其实MySQL本来默认也是这个级别
2.对当前session修改,在登录mysql客户端后,执行命令:
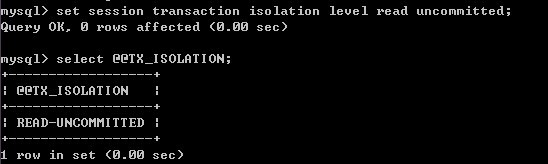
要记住mysql有一个autocommit参数,默认是on,他的作用是每一条单独的查询都是一个事务,并且自动开始,自动提交(执行完以后就自动结束了,如果你要适用select for update,而不手动调用 start transaction,这个for update的行锁机制等于没用,因为行锁在自动提交后就释放了),所以事务隔离级别和锁机制即使你不显式调用start transaction,这种机制在单独的一条查询语句中也是适用的,分析锁的运作的时候一定要注意这一点
再来说说锁机制:
共享锁:由读表操作加上的锁,加锁后其他用户只能获取该表或行的共享锁,不能获取排它锁,也就是说只能读不能写
排它锁:由写表操作加上的锁,加锁后其他用户不能获取该表或行的任何锁,典型是mysql事务中
start transaction;
select * from user where userId = 1 for update;
执行完这句以后
1)当其他事务想要获取共享锁,比如事务隔离级别为SERIALIZABLE的事务,执行
select * from user;
将会被挂起,因为SERIALIZABLE的select语句需要获取共享锁
2)当其他事务执行
select * from user where userId = 1 for update;
update user set userAge = 100 where userId = 1;
也会被挂起,因为for update会获取这一行数据的排它锁,需要等到前一个事务释放该排它锁才可以继续进行
锁的范围:
行锁: 对某行记录加上锁
表锁: 对整个表加上锁
这样组合起来就有,行级共享锁,表级共享锁,行级排他锁,表级排他锁
下面来说说不同的事务隔离级别的实例效果,例子使用InnoDB,开启两个客户端A,B,在A中修改事务隔离级别,在B中开启事务并修改数据,然后在A中的事务查看B的事务修改效果:
1.READ-UNCOMMITTED(读取未提交内容)级别
1)A修改事务级别并开始事务,对user表做一次查询
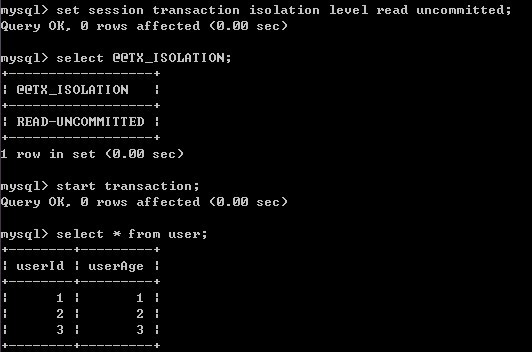
2)B更新一条记录
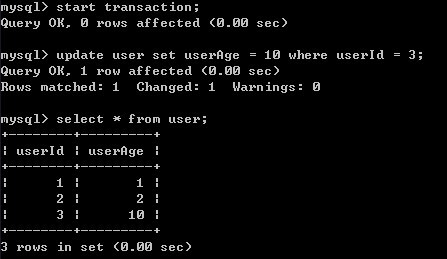
3)此时B事务还未提交,A在事务内做一次查询,发现查询结果已经改变
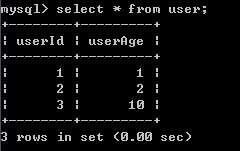
4)B进行事务回滚
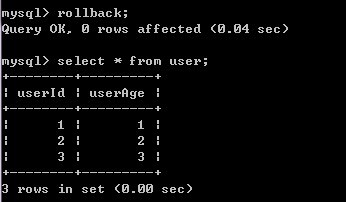
5)A再做一次查询,查询结果又变回去了
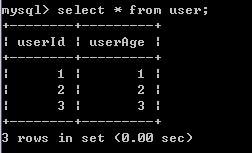
6)A表对user表数据进行修改

7)B表重新开始事务后,对user表记录进行修改,修改被挂起,直至超时,但是对另一条数据的修改成功,说明A的修改对user表的数据行加行共享锁(因为可以使用select)

可以看出READ-UNCOMMITTED隔离级别,当两个事务同时进行时,即使事务没有提交,所做的修改也会对事务内的查询做出影响,这种级别显然很不安全。但是在表对某行进行修改时,会对该行加上行共享锁
2. READ-COMMITTED(读取提交内容)
1)设置A的事务隔离级别,并进入事务做一次查询
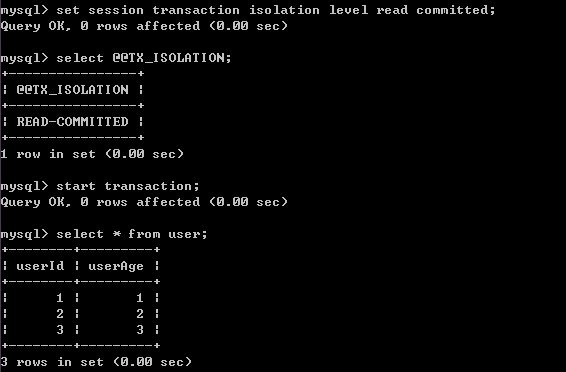
2)B开始事务,并对记录进行修改
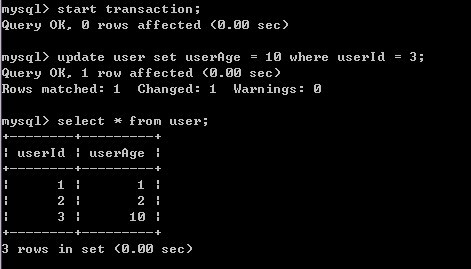
3)A再对user表进行查询,发现记录没有受到影响
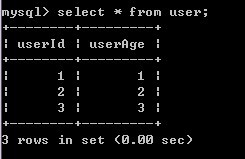
4)B提交事务
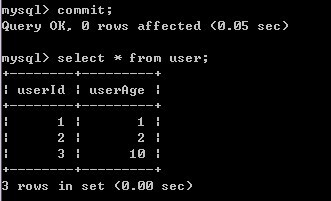
5)A再对user表查询,发现记录被修改
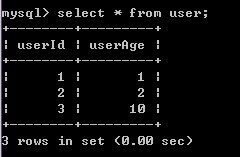
6)A对user表进行修改

7)B重新开始事务,并对user表同一条进行修改,发现修改被挂起,直到超时,但对另一条记录修改,却是成功,说明A的修改对user表加上了行共享锁(因为可以select)


READ-COMMITTED事务隔离级别,只有在事务提交后,才会对另一个事务产生影响,并且在对表进行修改时,会对表数据行加上行共享锁
3. REPEATABLE-READ(可重读)
1)A设置事务隔离级别,进入事务后查询一次
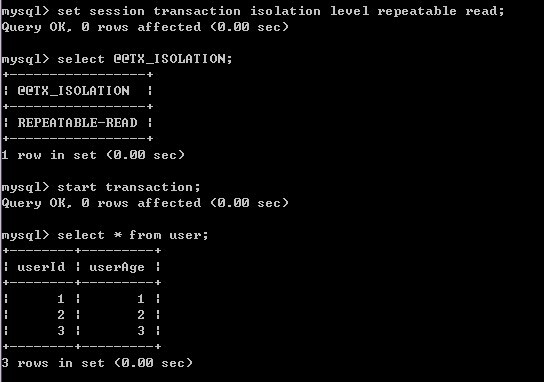
2)B开始事务,并对user表进行修改
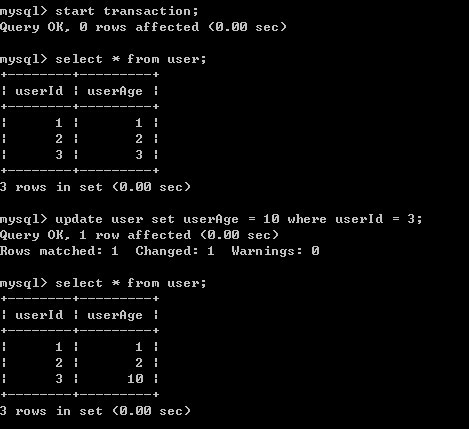
3)A查看user表数据,数据未发生改变
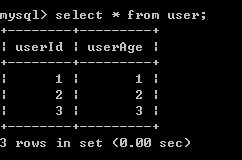
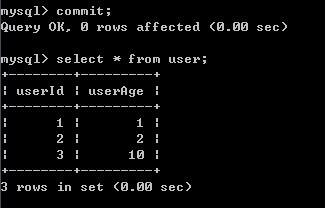
4)B提交事务
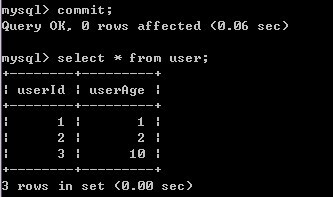
5)A再进行一次查询,结果还是没有变化
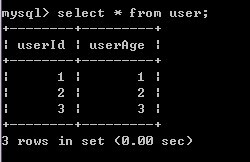
6)A提交事务后,再查看结果,结果已经更新
7)A重新开始事务,并对user表进行修改
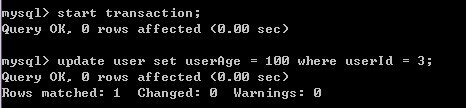
8)B表重新开始事务,并对user表进行修改,修改被挂起,直到超时,对另一条记录修改却成功,说明A对表进行修改时加了行共享锁(可以select)


REPEATABLE-READ事务隔离级别,当两个事务同时进行时,其中一个事务修改数据对另一个事务不会造成影响,即使修改的事务已经提交也不会对另一个事务造成影响。
在事务中对某条记录修改,会对记录加上行共享锁,直到事务结束才会释放。
4.SERIERLIZED(可串行化)
1)修改A的事务隔离级别,并作一次查询
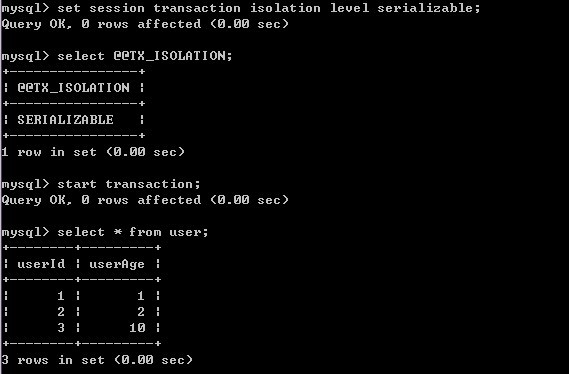
2)B对表进行查询,正常得出结果,可知对user表的查询是可以进行的
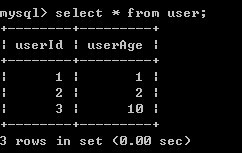
3)B开始事务,并对记录做修改,因为A事务未提交,所以B的修改处于等待状态,等待A事务结束,最后超时,说明A在对user表做查询操作后,对表加上了共享锁

SERIALIZABLE事务隔离级别最严厉,在进行查询时就会对表或行加上共享锁,其他事务对该表将只能进行读操作,而不能进行写操作。
参考:
http://xm-king.iteye.com/blog/770721
http://blog.csdn.net/taylor_tao/article/details/7063639
http://blog.csdn.net/lemon89/article/details/51477497
本文来自博客园,作者:sunsky303,转载请注明原文链接:https://www.cnblogs.com/sunsky303/p/8305031.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号