综合设计——多源异构数据采集与融合应用综合实践
综合设计——多源异构数据采集与融合应用综合实践
码云地址
[码云地址](多源异构数据采集与融合应用综合实践: Call of Silence数据采集与融合综合实验 (gitee.com))
| 这个项目属于哪个课程 | 2023数据采集与融合技术 |
|---|---|
| 组名、项目简介 | 组名:Call of Silence 项目需求:设计出一个交互友好的多源异构数据的采集与融合的小应用 项目目标:通过在web端输入文本、图片、视频等多源数据进行内容提取并对其进行概括 技术路线:前端3件套(html、css、js)、flask、 |
| 团队成员学号 | 052103117、102102142、102102148、102102149、102102150、102102154、102102155、172109005 |
| 这个项目目标 | 对获取的多模态信息进行分析概括 |
| 其他参考文献 | [1]梁永侦.基于深度学习的图像风格迁移方法研究[J].计算机时代,2023,(08):107-112.DOI:10.16644/j.cnki.cn33-1094/tp.2023.08.024 [2]熊文楷.基于深度学习的中国画风格迁移[J].科技与创新,2023,(13):176-178.DOI:10.15913/j.cnki.kjycx.2023.13.054 [3]郑卓.基于深度学习的风格迁移技术研究[D].浙江工商大学,2023.DOI:10.27462/d.cnki.ghzhc.2023.001362 |
项目整体介绍
1、项目名称:多模态内容概括
2、项目背景:
在当今社会,随着数字化时代的来临,信息呈现爆炸式增长,而这些信息涵盖了多种形态,本项目主要功能就是对获取的多模态信息进行分析概括,帮助用户从信息中快速获取主要内容。
3、项目意义:
面对互联网时代的信息过载,用户更需要一种智能化的工具来过滤、提炼信息,以便更快速地获取关键信息。多模态信息分析程序的功能满足了这一需求,帮助用户从海量信息中快速获取主要内容。
4、技术路线:
-
数据采集
- 采用selenium框架对bilibili中视频、封面、音频等数据进行爬取
-
前端开发:
- 使用HTML、CSS和JavaScript进行界面设计,实现用户与系统的交互。
- 用于上传文本、图片和视频等文件。
-
后端开发:
- 利用flask框架进行后端搭建。
- 用于接收前端发送的请求,对收到的数据进行保存和处理,最后返回文本结果。
-
数据处理与分析:
- 文本分析:采用星火的接口对输入的文本内容进行分析概括。
- 图片分析:
- 采用星火的接口对输入的图片进行概括,将概括后的文本进行分析概括返回图片概括后的结果。
- 视频分析:对于视频分析,没有找到合适的模型和接口进行概括,因此我们采用提取视频中的音频,对音频内容进行概括。
- 采用百度的接口对输入的视频提取主要内容并返回给用户。
-
风格迁移:
- 输入两张图片,一张作为被学习的风格图片,一张作为学习的融合图片,通过VGG19神经网络进行训练,得到的模型,可以将任意俩张图片进行风格迁移
5、项目部分功能展示
①项目页面展示


②文本概括功能展示

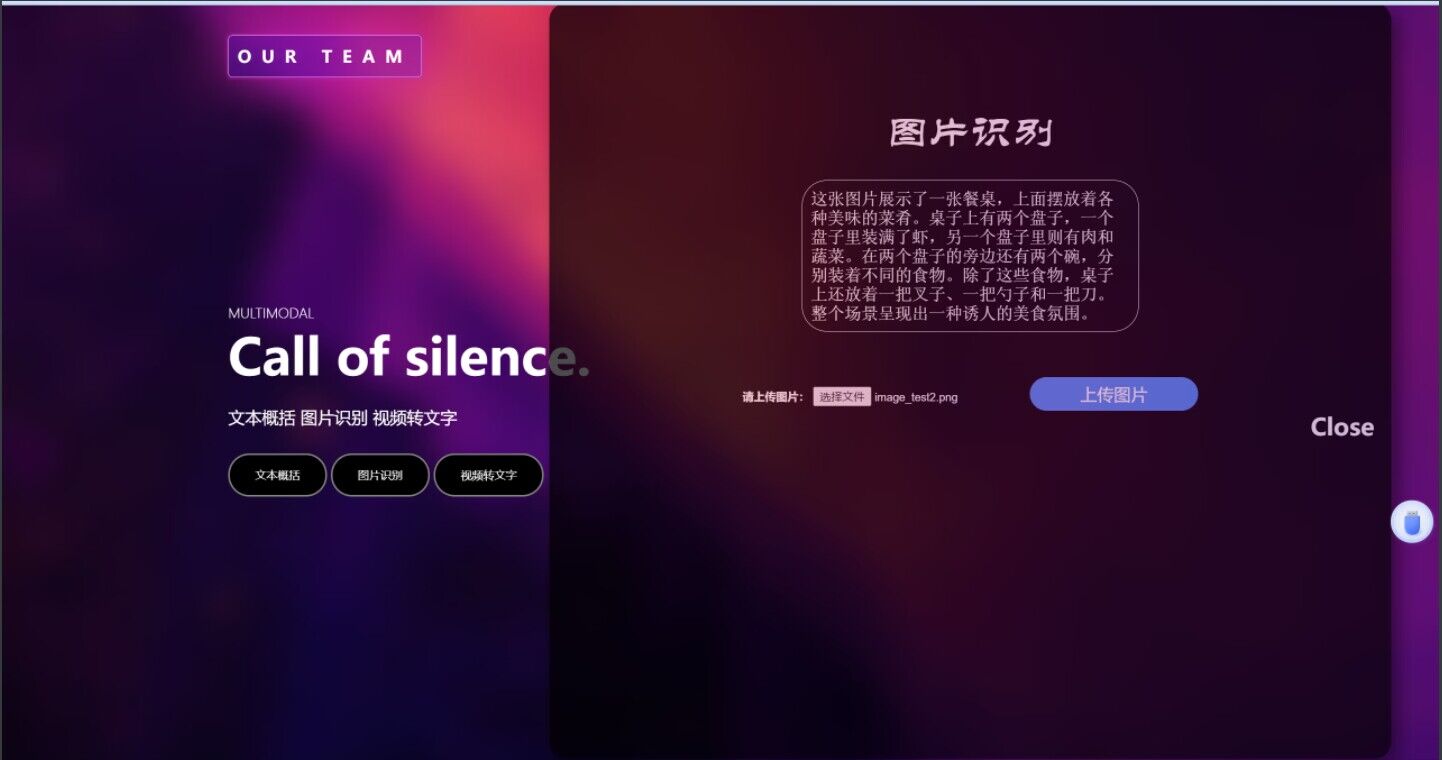
③图片概括功能展示
④视频概括功能展示

个人分工部分
- 1.协助爬虫部分完成
·部分代码展示
import time
import urllib.request
import re
from selenium import webdriver
from scrapy.selector import Selector
browser = webdriver.Chrome()
url = 'https://www.bilibili.com/'
browser.get(url)
time.sleep(5)
js_height = 'return document.body.scrollHeight'
height = browser.execute_script(js_height)
for i in range(200):
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(5)
new_height = browser.execute_script(js_height)
height = new_height
content = browser.page_source
browser.quit()
selector = Selector(text=content)
rows = selector.xpath("//div[@class='bili-video-card is-rcmd']")
with open(r'C:\Users\陈宏森\Desktop\picture_name.txt', 'w', encoding='utf-8') as f:
for row in rows:
name=row.xpath(".//h3/@title").extract_first()
# 使用正则表达式将文件名中的特殊字符替换为下划线
name = re.sub('[\/:*?"<>|]', '_', name)
img=row.xpath(".//img/@src").extract_first()
url_img = 'https:'+img
urllib.request.urlretrieve(url_img,r'C:\Users\陈宏森\Desktop\picture\\'+name+'.jpg')
print(name)
f.write(name + '\n')
·部分代码展示
# 纯视频的url
video_url = re.findall(r'"video":\[{"id":\d+,"baseUrl":"(.*?)"', url_list_str)[0]
# 纯音频的url
audio_url = re.findall(r'"audio":\[{"id":\d+,"baseUrl":"(.*?)"', url_list_str)[0]
# 设置跳转字段的headers
headers_ = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36',
'Referer': url_
}
# 获取纯视频的数据
response_video = requests.get(video_url, headers=headers_, stream=True)
bytes_video = response_video.content
# 获取纯音频的数据
response_audio = requests.get(audio_url, headers=headers_, stream=True)
bytes_audio = response_audio.content
# 获取文件大小, 单位为KB
video_size = int(int(response_video.headers['content-length']) / 1024)
audio_size = int(int(response_audio.headers['content-length']) / 1024)
# 保存纯视频的文件
title_1 = title_ + '!' # 名称进行修改,避免重名
title_1 = title_1.replace(':', '_')
with open(f'D:/python/exercise/数据采集大作业/video/{title_1}.mp4', 'wb') as f:
f.write(bytes_video)
with open(f'D:/python/exercise/数据采集大作业/audio/{title_1}.mp3', 'wb') as f:
f.write(bytes_audio)
ffmpeg_path = r".\ffmpeg.exe"
command = f'{ffmpeg_path} -i audio/{title_1}.mp3 -i video/{title_1}.mp4 -c copy ./video/{title_}/{title_}.mp4 -loglevel quiet'
os.system(command)
# 显示合成文件的大小
print(f'{title_} 下载完成')
except Exception as e:
print(f"下载失败: {e}")
return # 跳过当前视频的下载
browser = webdriver.Chrome()
url = 'https://www.bilibili.com/'
browser.get(url)
time.sleep(5)
js_height = 'return document.body.scrollHeight'
height = browser.execute_script(js_height)
for i in range(15):
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(5)
new_height = browser.execute_script(js_height)
height = new_height
content = browser.page_source
browser.quit()
selector = Selector(text=content)
rows = selector.xpath("//div[@class='bili-video-card is-rcmd']")
for row in rows:
href = row.xpath('.//a/@href').extract_first()
if href and href.startswith("https"):
videoDownload1(href)
- 2.项目市场分析与需求调研
①摘要:
在当今社会,随着数字化时代的来临,信息呈现爆炸式增长,而这些信息涵盖了多种形态,包括文本、图像、视频、等。传统的信息处理方式逐渐显得力不从心,
因为单一模态的分析已经无法满足对信息全面理解的需求,如果能够对这些海量的繁杂的信息进行概括,就能够站在事件更多元的视角,更全面地把握社会动态,以
一种更加综合、深入的信息理解方式,进行更明智的决策,提高决策的准确性和效率。因此我们小组的实践项目决定在这个方向努力,我们的程序主要功能就是对获
取的多模态信息进行分析概括,下面将从社会需求和选题意义两个大方向进行详细分析:
②社会需求:
1.信息汇聚与整合:
随着信息来源的多样化,社会对于信息的汇聚和整合需求愈发迫切。多模态信息分析程序的功能,能够通过获取并融合来自不同媒体的信息,提供更全面、一体化
的视角。这满足了用户对于高效获取、整理大量信息的迫切需求。
2.决策支持的精准性:
企业、政府、组织等在制定决策时,需要依赖于各类信息。而多模态信息分析程序通过对获取的信息进行主要内容的概况分析,提供了决策者一个更为精准、全面
的信息基础,从而支持更明智的决策制定。
3.应对信息过载:
面对互联网时代的信息过载,用户更需要一种智能化的工具来过滤、提炼信息,以便更快速地获取关键信息。多模态信息分析程序的功能满足了这一需求,帮助用
户从海量信息中快速获取主要内容。
③选题意义:
1.提高信息利用效率:
多模态信息分析程序通过对获取的信息进行主要内容的概况分析,将信息高效地呈现给用户。这不仅提高了信息的利用效率,还减轻了用户在信息理解上的认知负
担,使信息更易于消化和应用。
2.强化决策的科学性:
决策者在制定战略和计划时需要充分了解各种信息,而多模态信息分析程序的概览功能有助于提供信息的科学总结,为决策者提供更为准确、全面的信息基础,从
而强化决策的科学性和可靠性。
3.促进社会创新:
通过更全面的信息概览,多模态信息分析程序有助于发现隐藏在信息背后的模式和趋势。这为创新提供了可能性,不仅可以在决策领域创造新的方法,还可能为企
业、科研机构等提供创新的方向。
4.改善用户体验:
面对复杂的多模态信息,用户通常需要花费大量时间和精力进行理解。多模态信息分析程序通过提供主要内容的概况,使用户能够更快速地获取信息的核心,从而
改善了用户体验,使信息处理更加高效。
5.应对信息混淆和虚假信息:
通过对获取的信息进行主要内容的概况分析,程序有望识别和过滤掉一些虚假信息,提高信息的可信度和准确性,有力地应对信息混淆的问题,为用户提供更为可
靠的信息服务。
④总结:
在社会需求与选题意义的层面上,我们的多模态信息分析程序的核心功能不仅满足了信息获取和处理的实际需求,更在于通过主要内容的概况分析,为用户提供更
高效、精准、可信的信息服务,减轻用户的分析负担,帮助用户识别和过滤虚假信息,提高信息的可信度和准确性,为公众提供更为可靠的信息源,因此对于推动社
会信息智能化、决策科学化具有一定的影响。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号