数据采集-实践3
作业①:
·要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网( http://www.weather.com.cn )。使用scrapy框架分别实现单线程和多线程的方式爬取。
-务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
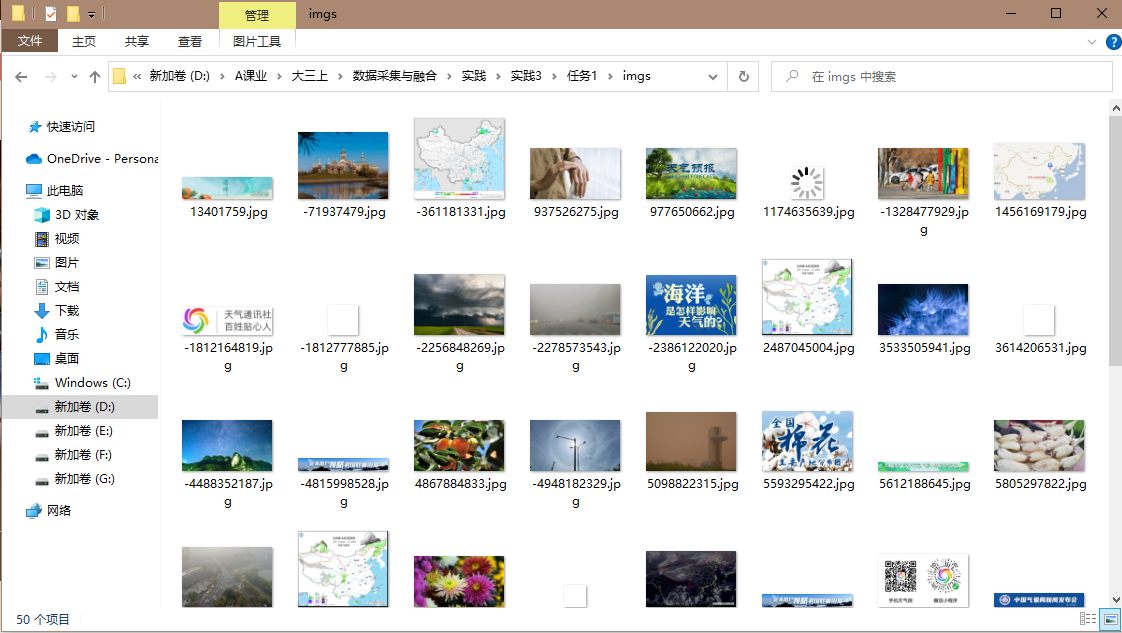
·输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
·Gitee文件夹链接: [https://gitee.com/dong-qi168/sjcjproject/tree/master/作业3/任务1]
关键代码与结果展示
·s1.py
import scrapy
from s1.items import S1Item
from bs4 import BeautifulSoup
class DangSpider(scrapy.Spider):
name = "s1"
allowed_domains = ["weather.com.cn"]
start_urls = ["http://www.weather.com.cn/"]
def parse(self, response):
print('=====================================================================')
items = []
soup = BeautifulSoup(response.text, "html.parser")
for img_tag in soup.find_all("img"):
url = img_tag["src"]
item = S1Item(url=url)
items.append(item)
print(url)
print('=====================================================================')
return items
结果展示
·代码运行情况
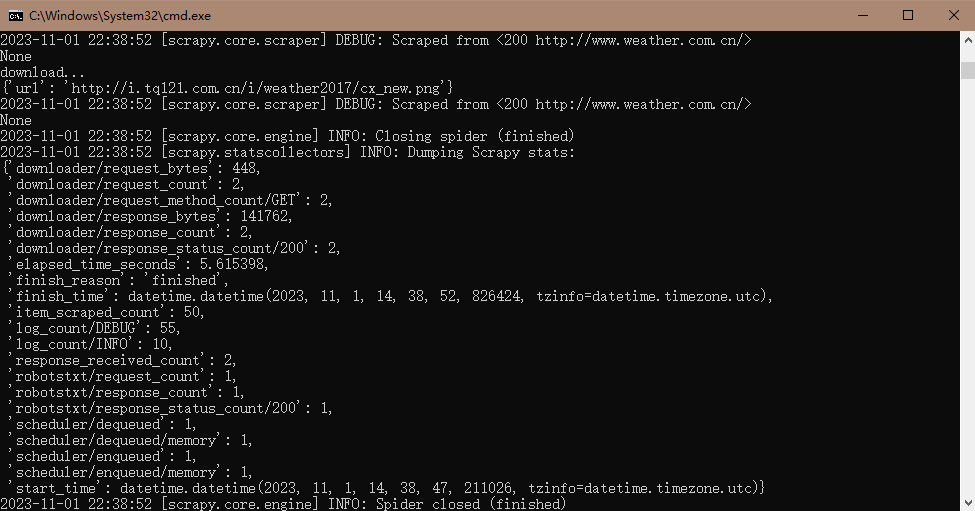
·查看
作业心得
这个任务不算难,但是一开始耽误了很多时间,通过这次作业加深了对scrapy框架下单线程与多线程这两种方式爬取的熟练程度
作业②
·要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
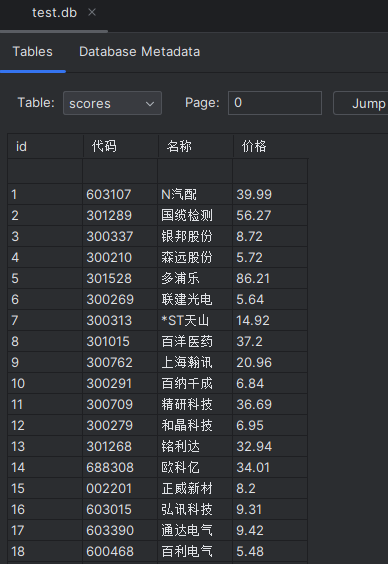
·输出信息:MySQL数据库存储和输出格式如下:
表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计
·Gitee文件夹链接: [https://gitee.com/dong-qi168/sjcjproject/tree/master/作业3/任务2]
关键代码与结果展示
s2.py
import scrapy
from s2.items import S2Item
from bs4 import BeautifulSoup
import json
import re
class DangSpider(scrapy.Spider):
name = "s2"
allowed_domains = ["eastmoney.com"]
start_urls = [" http://54.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124015380571520090935_1602750256400&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6 ,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1602750256401"]
count = 1
def parse(self, response):
data = response.text
start = data.index('{')
data = json.loads(data[start:len(data) - 2])
if data['data']:
for stock in data['data']['diff']:
item = self.create_item(stock)
yield item
url = self.get_next_page_url(response.url)
yield scrapy.Request(url=url, callback=self.parse)
def create_item(self, stock):
item = S2Item()
item['id'] = str(self.count)
self.count += 1
item["number"] = str(stock['f12'])
item["name"] = stock['f14']
item["value"] = None if stock['f2'] == "-" else str(stock['f2'])
return item
def get_next_page_url(self, url):
pn = re.compile("pn=[0-9]*").findall(url)[0]
page = int(pn[3:])
return url.replace("pn=" + str(page), "pn=" + str(page + 1))
结果展示
·代码运行情况

·查看
作业心得
爬取动态网页时需要格外注意。加深了对于整个过程的熟练度。
作业③:
·要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
·Gitee文件夹链接: [https://gitee.com/dong-qi168/sjcjproject/tree/master/作业3/任务3]
关键代码与结果展示
s3.py
import scrapy
from s3.items import S3Item
from bs4 import BeautifulSoup
class DangSpider(scrapy.Spider):
name = "s3"
allowed_domains = ["boc.cn"]
start_urls = ["https://www.boc.cn/sourcedb/whpj/"]
count = 0
def parse(self, response):
print('==============================begin=======================================')
bs_obj = BeautifulSoup(response.body, features='lxml')
table = bs_obj.find_all('table')[1]
rows = table.find_all('tr')[1:]
for row in rows:
item = S3Item()
cells = row.find_all('td')
item['currency'] = cells[0].text
item['tbp'] = cells[1].text
item['cbp'] = cells[2].text
item['tsp'] = cells[3].text
item['csp'] = cells[4].text
item['time'] = cells[6].text
print(cells)
yield item
self.count += 1
url = f"http://www.boc.cn/sourcedb/whpj/index_{self.count}.html"
if self.count != 5:
yield scrapy.Request(url=url, callback=self.parse)
print('===============================end======================================')
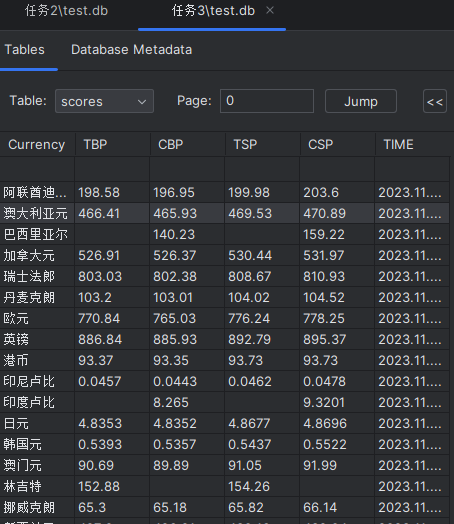
结果展示
·代码运行情况
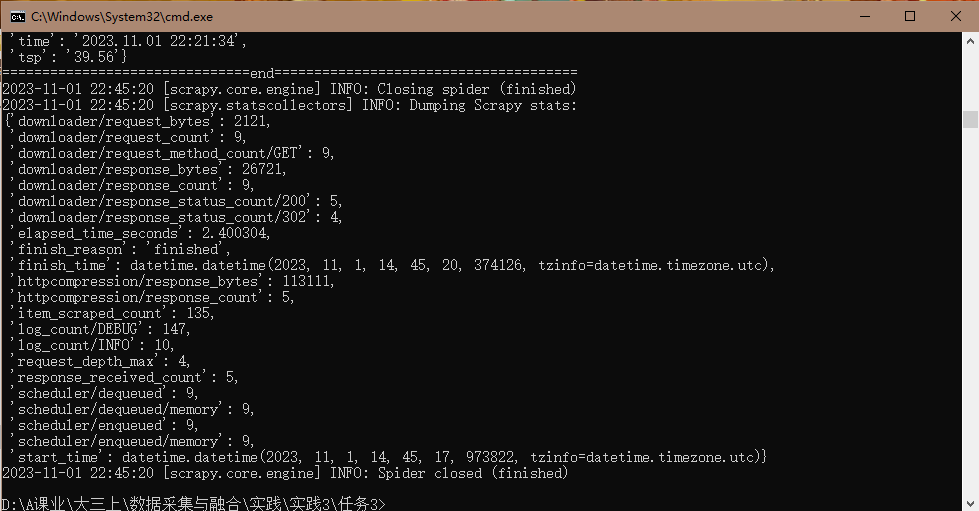
·查看
作业心得
与上一个任务比较类似,加深了对scrapy框架的认识,熟悉了更多内容。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号