作业一
作业一
1) 实验一内容
代码如下:
from bs4 import BeautifulSoup
from re import match
import re
print("102102154董奇")
url = 'http://www.shanghairanking.cn/rankings/bcur/2020'
request = urllib.request.urlopen(url)
data = request.read().decode()
soup = BeautifulSoup(data)
tags = soup.find_all('tr', attrs={"data-v-4645600d": ""})
for i in tags:
t = i.find('div', attrs={'class': 'ranking'})
n = i.find('a', attrs={'class': 'name-cn'})
c = i.find_all('td', attrs={'data-v-4645600d': ''})
if t != None and n != None:
name = match('.+[大学,学院]', n.text)[0]
rank = str(t.string).strip()
province = ''.join(re.findall('[\u4e00-\u9fa5]', c[2].text))
type = ''.join(re.findall('[\u4e00-\u9fa5]', c[3].text))
point = ''.join(re.findall('[0-9\.]', c[4].text))
print(rank + ':' + name + ',' + province + "," + type + ',' + point)
结果如下:
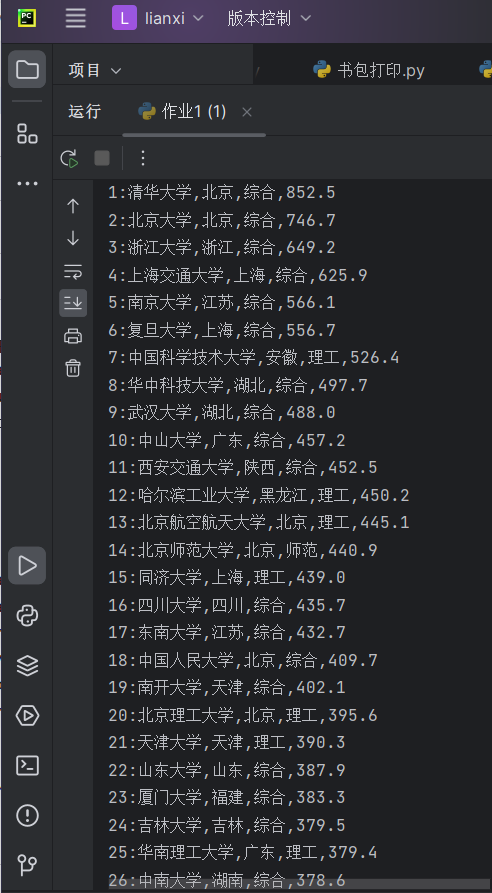
2) 心得体会
实验一锻炼了用requests和BeautifulSoup库方法定向爬取给定网址的方法,同时还需要熟悉查找网页信息标签的方法,由于个人能力有限,没有翻页,有待提高
作业二
1) 实验二内容
代码如下:
import re
def crawl_product_info():
url = "http://search.dangdang.com/?key=%CA%E9%B0%FC&act=input"
keyword = "书包"
response = requests.get(url)
if response.status_code == 200:
page_content = response.text
pattern = r'<li ddt-pit=.*?class=.*?alt=(.*?)>.*?<span class="price_n">¥(.*?)</span>'
items = re.findall(pattern, page_content, re.S)
product_info = []
for i, item in enumerate(items, 1):
product_name = item[0].strip()
product_price = item[1].strip()
product_info.append((i, product_price, product_name))
return product_info
else:
print("请求失败")
return None
product_info = crawl_product_info()
if product_info:
for item in product_info:
print(f"序号:{item[0]} 价格:{item[1]} 商品名:{item[2]}")
else:
print("未获取到商品信息")
结果如下:
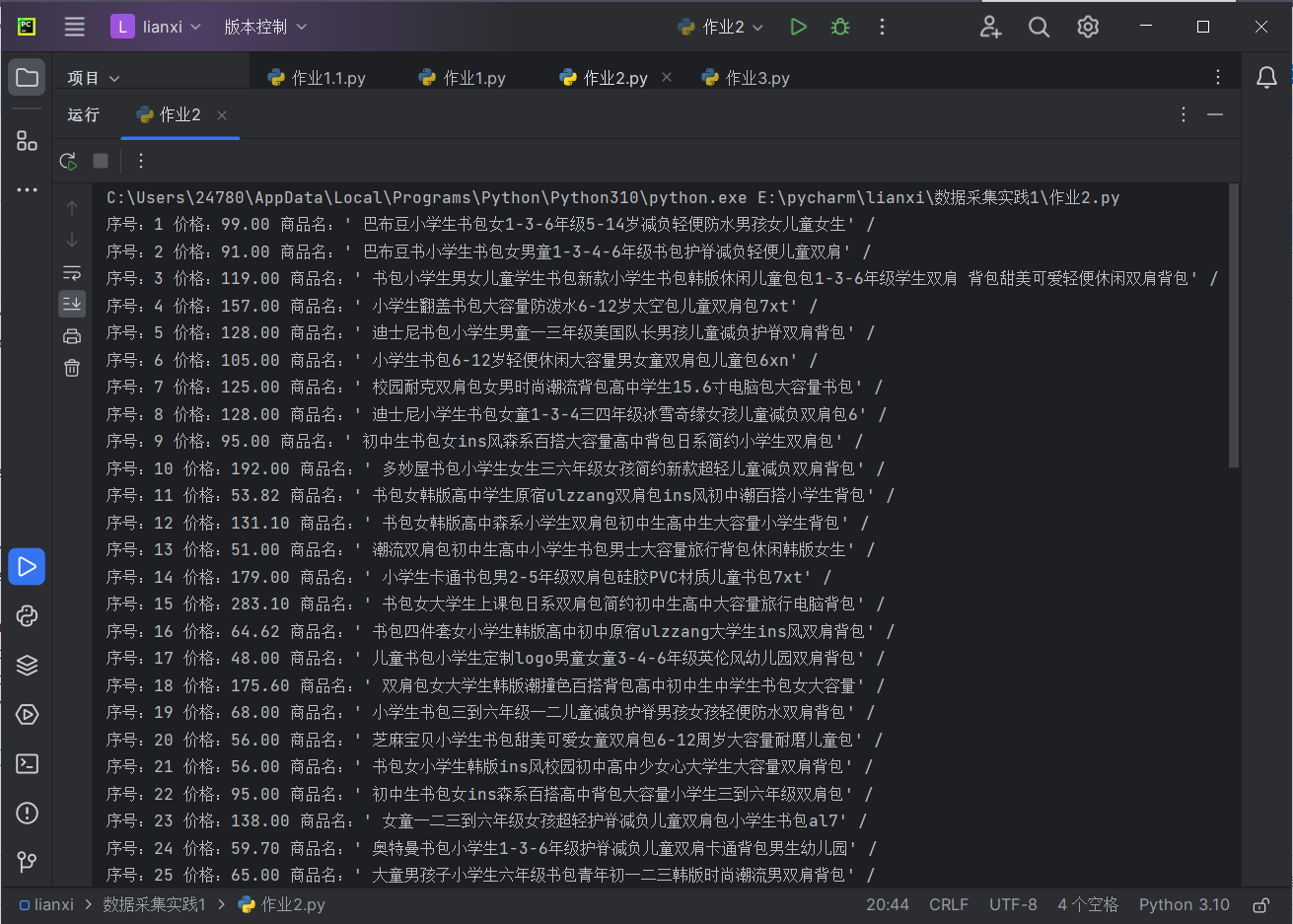
2)心得体会
这个实验一开始正则表达式使用错误,一直不能爬取需要的信息,需要加强对正则表达式的熟悉
作业三
1)实验三内容
代码如下:
import requests
import urllib.request as req
import os
from bs4 import BeautifulSoup
url = "https://xcb.fzu.edu.cn/info/1071/4481.htm"
response = req.urlopen(url).read().decode()
soup = BeautifulSoup(response, 'lxml')
img_tags = soup.find_all('img')
count = 0
for img in img_tags:
img_url = 'https://xcb.fzu.edu.cn/'+img['src']
req.urlretrieve(img_url,r'E:\pycharm\lianxi\数据采集实践1\images\img'+str(count)+'.jpg')
count+=1
结果如下:
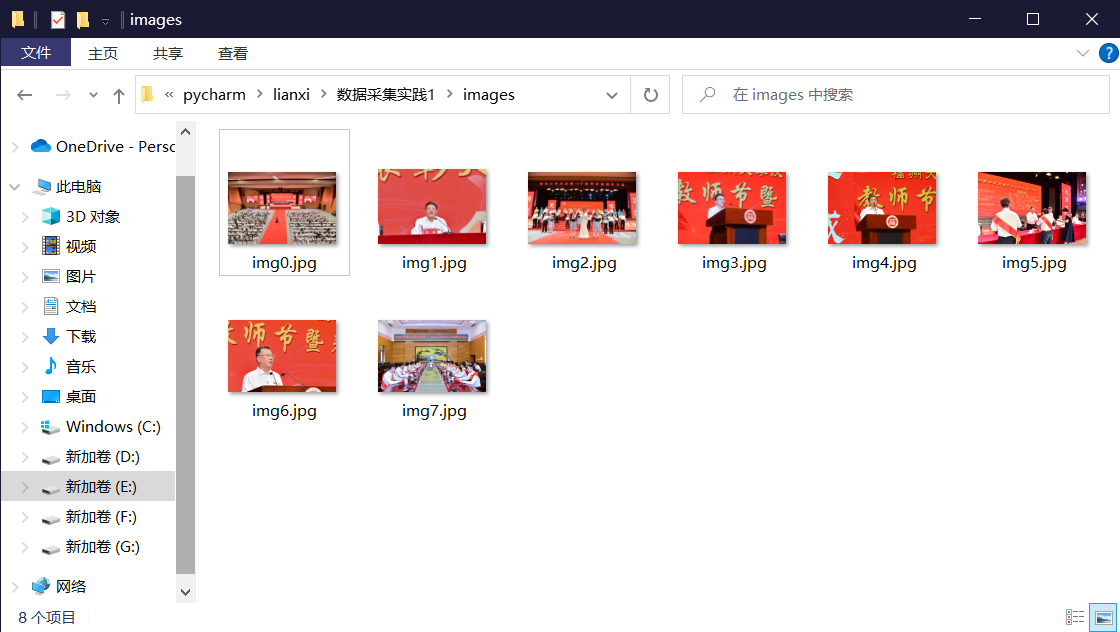
2)心得体会
这个实验帮助我将之前的爬虫知识融合实践,也让我对下载图片更加熟练,掌握了部分方法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号