

《Neural Machine Translation by Jointly Learning to Align and Translate》阅读笔记
1.摘要
神经网络机器翻译是最新提出的一种机器翻译方法。与传统的基于统计学的机器翻译不同的是,神经网络机器翻译旨在构建一个简单的网络从而使翻译效果最优。最近提出的用于神经网络机器翻译的模型通常属于编码-解码器一类,编码器将源序列编码成固定长度的向量,然后解码器根据该向量生成译文。在本论文中,作者认为encoder-decoder架构性能提升的瓶颈主要在于中间转换的固定纬度大小的向量。因此,作者提出了一种新的解码方式,他们希望构建一种为当前预测词从输入序列中自动搜寻相关部分的机制(soft-search,也就是注意力机制)。作者运用这种新的机制来搭建升级版的神经机器翻译模型,可以与当前的最先进的模型效果相比,并且也通过定量分析证明了这种注意力机制的合理性。
2.解决的问题与解决方法
2.1 存在的问题
(1)传统的encoder-decoder架构在编码输入序列时将所有信息压缩到一个固定长度的向量,这使得网络在处理较长序列的输入(特别是比训练数据要长)时显得十分吃力
(2)随着序列的增长,句子前面的词的信息丢失,由于解码当前预测词时需要对应输入词的上下文信息,而输入序列的位置信息等基本丢失,因此造成翻译结果不准确
2.2 解决方法
引入注意力机制。在预测目标词时,计算权重系数(相关系数)(表示是目标词的相关系数,j的值为[1,$T_{x}$],表示输入序列长度),权重系数也即和的相关系数。根据可以获得输入源序列中与当前目标词的相关部分(权重系数较大的部分),也即在翻译的时候知道着重注意哪些部分,保留了位置信息,并实现了输入与输出之间的对齐,从而实现更好的翻译结果。
3.模型与实验
3.1 模型
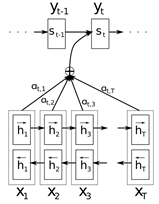
The graphical illustration of the proposed model trying to generate the t-th target word yt given a source sentence (x1, x2, . . . , xT).
(1)编码部分
编码部分采用双向RNN模型获取上下文信息。
$h_{t}=\tanh \left(A *\left[\begin{array}{l}h_{T-1} \\x_{T}\end{array}\right]\right)$
其中A为参数矩阵,维度为$a *(a+b)$,$h_{t-1}$的维度为a,$x_{t}$的维度为b
(2)译码部分
译码部分采用带有注意力机制的RNN模型。
预测目标词$o_{i}$的权重系数向量矩阵$c_{i-1}=\alpha_{i 1} h_{1}+\alpha_{i 2} h_{2}+\cdots+\alpha_{i t} h_{T}$,$\alpha_{i t}$计算方法如下:
$\alpha_{i j}=\operatorname{softmax}\left(e_{i j}\right)$
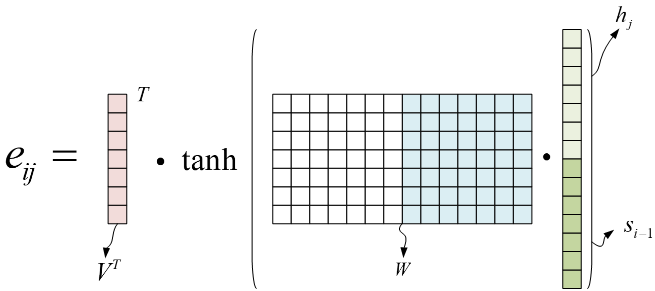
其中V和W是参数矩阵,通过训练数据的训练学习所得,j的取值范围为[1,$T_{x}$],$T_{x}$表示输入序列的长度,$h_{j}$表示编码器中的隐藏状态,$s_{i-1}$表示译码器中目标词$o_{i}$之前的所有预测的得到的译文信息。$h_{j}$和$s_{i-1}$的维度为$\mathrm{m} \times 1$,W的维度为$\mathrm{m} \times 2 \mathrm{~m}$,V的维度为$\mathrm{m} \times 1$,$V^{T}$的维度为$1 \times \mathrm{m}$
译码器中$s_{i}$的计算公式如下:
$s_{i}=\tanh \left(B *\left[\begin{array}{c}y_{i} \\s_{i-1} \\c_{i-1}\end{array}\right]+b\right)$
B为参数矩阵,通过训练数据的训练学习所得,b为偏移向量,$s_{i-1}$表示译码器之前得到的所有信息,$c_{i-1}$是权重系数向量矩阵。参数矩阵的更新采用随机梯度下降SGD。
3.2 实验
本文在English-French翻译任务中验证了所提出的模型和方法的正确性和有效性,且控制实验条件和采用相同的数据与最新提出的RNN Encode-Decoder方法进行了对比。
4.个人总结与感悟
这篇论文提出了一个新颖的带有注意力机制的神经网络翻译模型,也是首次提出注意力机制,该模型在翻译目标词时只关注源序列中和当前目标词相关的部分,在长序列的翻译中可以得到更加正确的结果。但是注意力模型参数多,计算量大。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号