决策树的分类过程和人的决策过程比较相似,就是先挑“权重”最大的那个考虑,然后再往下细分。比如你去看医生,症状是流鼻涕,咳嗽等,那么医生就会根据你的流鼻涕这个权重最大的症状先认为你是感冒,接着再根据你咳嗽等症状细分你是否为病毒性感冒等等。决策树的过程其实也是基于极大似然估计。那么我们用一个什么标准来衡量某个特征是权重最大的呢,这里有信息增益和基尼系数两个。ID3算法采用的是信息增益这个量。
根据《统计学习方法》中的描述,G(D,A)表示数据集D在特征A的划分下的信息增益。具体公式:
G(D,A)=H(D)-H(D|A)。其中H(D)表示数据集D的熵,熵可以用来描述其混乱度,计算公式为
H(D)=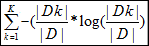 可见对于数据集D而言,|Dk|表示类别为k的数量,其类别越多,越混乱。
可见对于数据集D而言,|Dk|表示类别为k的数量,其类别越多,越混乱。
而H(D|A)表示数据集D在A的划分下的的不确定性。他们的差也即是信息增益,表示由于特征A使得数据集D的分类的不确定减少的差,所以这个值越大说明A的分类对D越有效,也就是权重越大。
H(D|A)=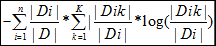 |Dik|表示在特征A中value为i的划分下数据集类别为k的数量。
|Dik|表示在特征A中value为i的划分下数据集类别为k的数量。
有了这两个公式,接下来就可以写代码了。这里为了清晰的表示这个结果,采用了xml来输出。由于刚开始学java所以只能即学即用(java和python简直不能比,python写ID3一百行代码妥妥的搞定,java用了将近300行。。。)
算法步骤:
输入:数据集D,特征集A(这里也可以输入一个阀值,如果信息增益小于该阀值就直接作为叶节点,这样可以避免过拟合)
输出:xml文件
1 如果D中的类别是同一类,则作为叶节点,标记为该类Ck
2 如果特征集A中没有特征了,那么作为叶节点,并且用数据集D中类别最多的类作为类标记
3 对D的各个特征求最大信息增益,选择信息增益最大的特征Ag
4 对特征Ag中各个值ai继续对数据集进行分割为Di
5 以Di为数据集,A-Ag为特征集为输入进行1-4步骤
具体代码:
1 import java.io.BufferedReader; 2 import java.io.FileInputStream; 3 import java.io.FileWriter; 4 import java.io.IOException; 5 import java.io.InputStreamReader; 6 import java.util.ArrayList; 7 import java.util.HashMap; 8 import java.util.HashSet; 9 import java.util.Map; 10 import java.util.Set; 11 12 import org.dom4j.Document; 13 import org.dom4j.DocumentHelper; 14 import org.dom4j.Element; 15 import org.dom4j.io.XMLWriter; 16 17 18 19 20 21 22 class Utils{ 23 //用于从文件中获取数据集 24 public static ArrayList<ArrayList<String>> loadDataSet(String file) throws IOException{ 25 ArrayList<ArrayList<String>> dataSet=new ArrayList<ArrayList<String>>(); 26 FileInputStream fis=new FileInputStream(file); 27 InputStreamReader isr=new InputStreamReader(fis,"UTF-8"); 28 BufferedReader br=new BufferedReader(isr); 29 String line=""; 30 line=br.readLine(); 31 while((line=br.readLine())!=null){ 32 String[] words=line.split(","); 33 ArrayList<String> data=new ArrayList<String>(); 34 for(int i=0;i<words.length;i++){ 35 data.add(words[i]); 36 } 37 dataSet.add(data); 38 } 39 br.close(); 40 isr.close(); 41 fis.close(); 42 return dataSet; 43 } 44 //用于从文件中获取特征 45 public static ArrayList<String> loadFeature(String file) throws IOException{ 46 FileInputStream fis=new FileInputStream(file); 47 InputStreamReader isr=new InputStreamReader(fis,"UTF-8"); 48 BufferedReader br=new BufferedReader(isr); 49 50 String[] line=br.readLine().split(","); 51 ArrayList<String> feature=new ArrayList<String>(); 52 for(int i=0;i<line.length-1;i++){ 53 feature.add(line[i]); 54 } 55 br.close(); 56 isr.close(); 57 fis.close(); 58 return feature; 59 } 60 //用于获得数据集中的类别列表 61 public static ArrayList<String> getClassList(ArrayList<ArrayList<String>> dataSet){ 62 ArrayList<String> classList=new ArrayList<String>(); 63 int length=dataSet.get(0).size(); 64 for(ArrayList<String> data:dataSet){ 65 String label=data.get(length-1); 66 classList.add(label); 67 } 68 return classList; 69 } 70 //返回数据集中的特征数 71 public static int featureNum(ArrayList<ArrayList<String>> dataList){ 72 int len=dataList.get(0).size()-1; 73 return len; 74 } 75 76 77 // public static void writeToXML(String fileName) throws IOException{ 78 // Document document = DocumentHelper.createDocument(); 79 // Element root = document.addElement("DecisionTree"); 80 // Element outlook=root.addElement("outlook"); 81 // outlook.addAttribute("value","sunny"); 82 // Element humidity1=outlook.addElement("humidity"); 83 // humidity1.addAttribute("value","high"); 84 // humidity1.addText("no"); 85 // Element humidity2=outlook.addElement("humidity"); 86 // humidity2.addAttribute("value","normal"); 87 // humidity2.addText("yes"); 88 // 89 // XMLWriter writer=new XMLWriter(new FileWriter(fileName)); 90 // writer.write(document); 91 // writer.close(); 92 // } 93 //用于获得数据集中第index列的map映射,方便后续的遍历value和计算熵 94 public static Map<String,Integer> getSubMap(ArrayList<ArrayList<String>> dataSet,int index){ 95 int total=dataSet.size(); 96 Map<String,Integer> subMap=new HashMap(); 97 for(ArrayList<String> data:dataSet){ 98 String lable=data.get(index); 99 if(subMap.get(lable)==null){ 100 subMap.put(lable,1); 101 }else{ 102 subMap.put(lable,subMap.get(lable)+1); 103 } 104 } 105 return subMap; 106 } 107 //打印map,用于debug的时候 108 public static void showMap(Map<String,Integer> map){ 109 for(Map.Entry<String,Integer> entry:map.entrySet()){ 110 System.out.println(entry.getKey()+":"+entry.getValue()); 111 } 112 } 113 //求熵 114 public static double getEntropy(ArrayList<ArrayList<String>> dataSet,int index){ 115 int total=dataSet.size(); 116 Map<String,Integer> subMap=getSubMap(dataSet,index); 117 double entropy=0; 118 for(Map.Entry<String,Integer> entry:subMap.entrySet()){ 119 double temp=entry.getValue()*1.0/total; 120 entropy+=temp*(Math.log(temp)/Math.log(2)); 121 } 122 return -entropy; 123 } 124 //求信息增益最大的分割点 125 public static String bestFeatureSplit(ArrayList<ArrayList<String>> dataSet,ArrayList<String> featureList){ 126 int length=dataSet.get(0).size(); 127 double totalEntropy=getEntropy(dataSet,length-1); 128 129 130 131 int featureNum=dataSet.get(0).size()-1; 132 int index=-1; 133 double maxInfoGain=-1; 134 for(int i=0;i<featureNum;i++){ 135 double entropy=getEntropy(dataSet,i); 136 Map<String,Integer> map=getSubMap(dataSet,i);//获得该特征下的map 137 ArrayList<String> lableList=new ArrayList<String>(); 138 double entropySum=0; 139 140 for(Map.Entry<String,Integer> entry:map.entrySet()){//这里的Di就是map中的特征的value值 141 Map<String,Integer> subMap=new HashMap(); 142 143 144 for(ArrayList<String> data:dataSet){ 145 if(data.get(i).compareTo(entry.getKey())==0){ 146 if(subMap.get(data.get(length-1))==null){ 147 148 subMap.put(data.get(length-1),1); 149 }else{ 150 subMap.put(data.get(length-1),subMap.get(data.get(length-1))+1); 151 } 152 } 153 } 154 double x=0; 155 for(Map.Entry<String,Integer> subEntry:subMap.entrySet()){ 156 double temp=subEntry.getValue()*1.0/entry.getValue(); 157 x+=temp*(Math.log(temp)/Math.log(2)); 158 } 159 160 entropySum+=-x*(entry.getValue())/dataSet.size(); 161 } 162 entropySum=totalEntropy-entropySum; 163 if(entropySum>maxInfoGain){ 164 index=i; 165 maxInfoGain=entropySum; 166 } 167 } 168 return featureList.get(index); 169 } 170 //分割数据集,index为特征的下标 171 public static ArrayList<ArrayList<String>> splitDataSet(ArrayList<ArrayList<String>> dataSet,int index,String value){ 172 ArrayList<ArrayList<String>> subDataSet=new ArrayList<ArrayList<String>>(); 173 for(ArrayList<String> data:dataSet){ 174 if(data.get(index).compareTo(value)==0){ 175 ArrayList<String> temp=new ArrayList<String>(); 176 for(int i=0;i<data.size();i++){ 177 if(i!=index){ 178 temp.add(data.get(i)); 179 } 180 } 181 subDataSet.add(temp); 182 } 183 } 184 return subDataSet; 185 } 186 //list-》map 187 public static Map<String,Integer> arrayToMap(ArrayList<String> list){ 188 Map<String,Integer> map=new HashMap(); 189 for(String word:list){ 190 if(map.get(word)==null){ 191 map.put(word,1); 192 }else{ 193 map.put(word,map.get(word)+1); 194 } 195 } 196 return map; 197 } 198 //求label中某个数量最多的类别 199 public static String major(ArrayList<String> labelList){ 200 Map<String,Integer> map=arrayToMap(labelList); 201 int max=0; 202 String label=""; 203 for(Map.Entry<String,Integer> entry:map.entrySet()){ 204 if(entry.getValue()>max){ 205 label=entry.getKey(); 206 } 207 } 208 return label; 209 } 210 211 public static Set<String> getValueFromDataSet(ArrayList<ArrayList<String>> dataSet,int index){ 212 ArrayList<String> values=new ArrayList<String>(); 213 for(ArrayList<String> data:dataSet){ 214 try{ 215 values.add(data.get(index)); 216 }catch(Exception e){ 217 218 System.out.println("index is "+index); 219 } 220 } 221 Set<String> set=new HashSet(); 222 for(String value:values){ 223 set.add(value); 224 } 225 return set; 226 } 227 228 public static ArrayList<String> copyArrayList(ArrayList<String> src){ 229 ArrayList<String> dest=new ArrayList<String>(); 230 for(String s:src){ 231 dest.add(s); 232 } 233 return dest; 234 } 235 236 237 public static void showArrayList(ArrayList<ArrayList<String>> dataSet){ 238 for(ArrayList<String> data:dataSet){ 239 System.out.println(data); 240 } 241 } 242 243 } 244 245 246 public class DecisionTree { 247 248 249 public static int createTree(ArrayList<ArrayList<String>> dataSet,ArrayList<String> featureList,Element e){ 250 ArrayList<String> labelList=Utils.getClassList(dataSet);//获取数据集中label的列表 251 if(Utils.arrayToMap(labelList).size()==1){//表示label中只有一种类别,所以此时不需要再分类了 252 e.addText(labelList.get(0)); 253 return 1; 254 } 255 if(dataSet.get(0).size()==1){//表示此时已经没有特征了,所以也不需要再继续了,此时以label中最多的类别为该节点的类别 256 e.addText(Utils.major(labelList)); 257 return 1; 258 } 259 260 ArrayList<String> subFeatureList=Utils.copyArrayList(featureList); 261 262 263 264 String feature=Utils.bestFeatureSplit(dataSet,featureList); 265 subFeatureList.remove(feature); 266 int index=featureList.indexOf(feature); 267 268 Set<String> valueSet=Utils.getValueFromDataSet(dataSet,index); 269 // Element next=e.addElement(feature);//原来的代码位置 270 for(String value:valueSet){ 271 Element next=e.addElement(feature);//后来放到这里之后,xml的输出就正确了,原因在于每递归一次就需要创建一个element,所以应该在for内创建。 272 next.addAttribute("value",value); 273 ArrayList<ArrayList<String>> subDataSet=Utils.splitDataSet(dataSet,index,value); 274 createTree(subDataSet,subFeatureList,next); 275 } 276 return 1; 277 } 278 279 public static void main(String[] args) throws IOException { 280 // TODO Auto-generated method stub 281 String file="C:/Users/Administrator/Desktop/upload/DT.txt"; 282 String xml="C:/Users/Administrator/Desktop/upload/DT1.xml"; 283 ArrayList<ArrayList<String>> dataSet=Utils.loadDataSet(file); 284 ArrayList<String> featureList=Utils.loadFeature(file); 285 Document document = DocumentHelper.createDocument(); 286 Element root = document.addElement("DecisionTree"); 287 createTree(dataSet,featureList,root); 288 XMLWriter writer=new XMLWriter(new FileWriter(xml)); 289 writer.write(document); 290 writer.close(); 291 System.out.println("finished"); 292 } 293 294 }
这次除了算法上的理解更加深刻了外,在java上也学到了些关于xml解析,读写等方法。
另外对递归的使用也更加形象些,对于递归一个容易错的点就是函数上的参数,一定要认真对待,要清楚该参数该在什么时候初始化,什么时候被用到。我一开始在第269行上就出现错误了,一开始没有考虑清楚这个next该在什么时候分配,后来发现每次创建节点的时候我们在xml就要创建一个相应的节点用来描述他,所以应该是在for循环里面创建,如果在for外面创建就表示,该特征下的所有值都只有一个element。
当然对于set,map的遍历啥的也更加清晰了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号