
JAVA集合
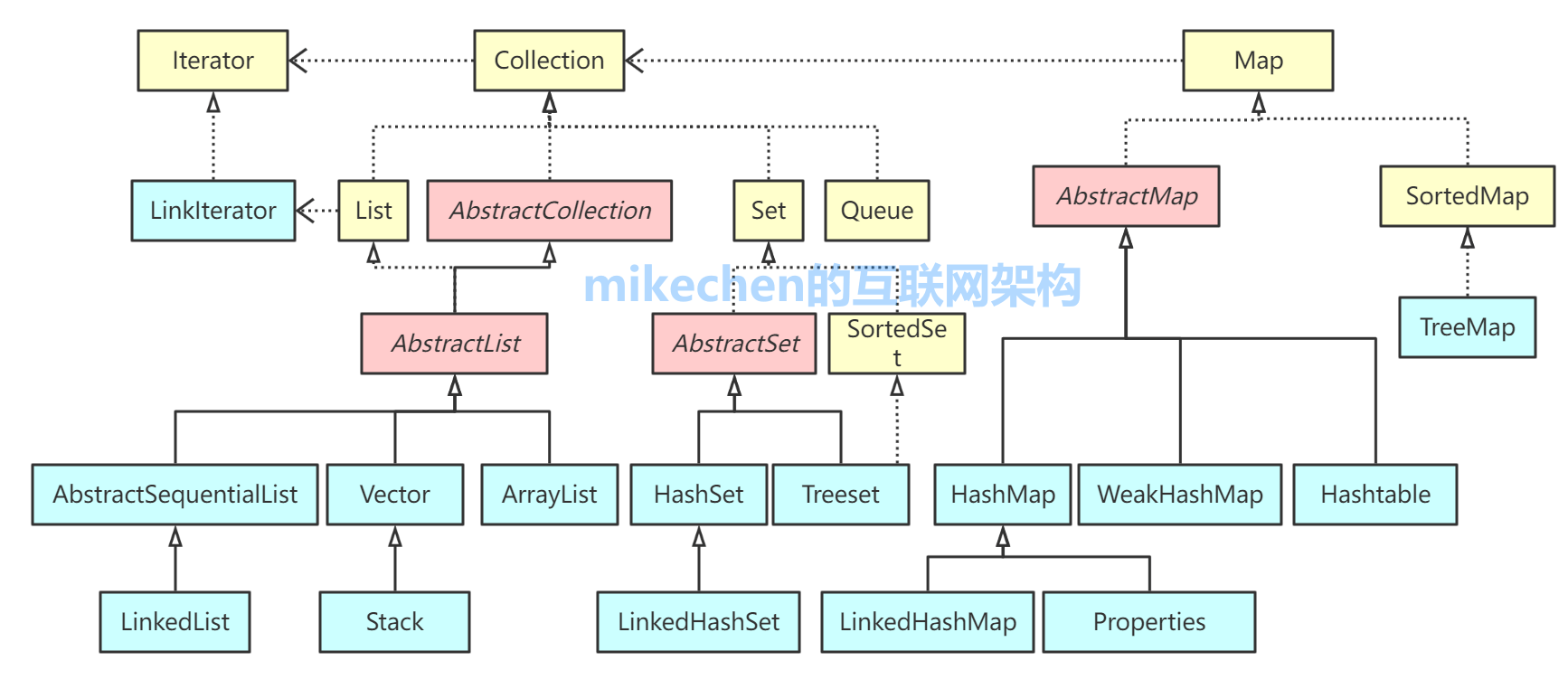
Java 容器分为 Collection 和 Map 两大类,Collection集合的子接口有Set、List、Queue三种子接口。我们比较常用的是Set、List,Map接口不是collection的子接口。
Collection集合主要有List和Set两大接口
List:一个有序(元素存入集合的顺序和取出的顺序一致)容器,元素可以重复,可以插入多个null元素,元素都有索引。常用的实现类有 ArrayList、LinkedList 和 Vector。
Set:一个无序(存入和取出顺序有可能不一致)容器,不可以存储重复元素,只允许存入一个null元素,必须保证元素唯一性。Set 接口常用实现类是 HashSet、LinkedHashSet 以及TreeSet。
Map是一个键值对集合,存储键、值和之间的映射。 Key无序,唯一;value 不要求有序,允许重复。Map没有继承于Collection接口,从Map集合中检索元素时,只要给出键对象,就会返回对应的值对象。
Map 的常用实现类:HashMap、TreeMap、HashTable、LinkedHashMap、ConcurrentHashMap
ArrayList
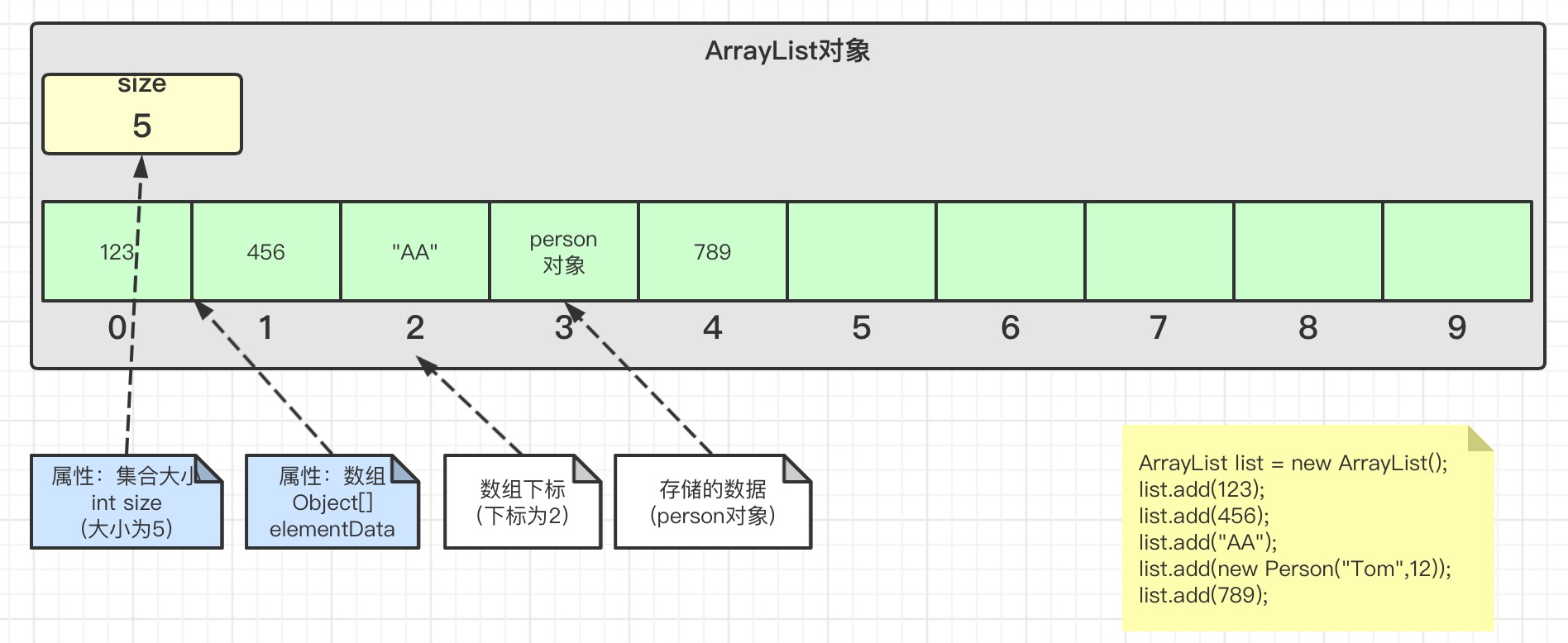
ArrayList是一个有序、可重复、有索引的数据结构,线程不安全,底层是动态数组,查询效率高,非尾的增加和删除效率低于LinkedList,因为涉及数组数据的迁移或者扩容缩容
ArrayList的默认容量是10,扩容倍数是1.5倍,扩容的触发机制是 当前元素数 + 1 > 当前容量.
ArrayList的倍数1.5倍主要有两个原因
1.空间效率:太小会频繁扩容,态度会造成空间浪费。
2.计算效率:通过位运算 oldCapacity + (oldCapacity >> 1) 实现,右移一位相当于除以2,计算速度快
Vector
Vector是线程安全的,其所有公共方法都使用synchronized关键字修饰,确保多线程环境下的数据一致性
Vector默认初始容量为10,扩容策略为原容量的2倍(newCapacity = oldCapacity * 2)
LinkedList
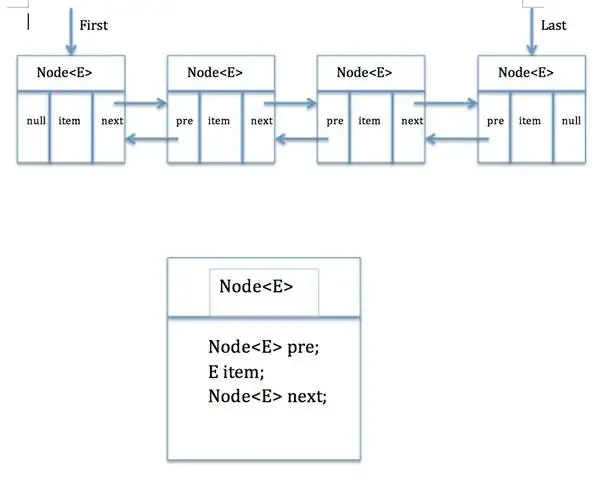
底层是双向链表,可进行头插和尾插,新增和删除的效率高,但是查询的时候需要一个一个遍历,可用于实现堆栈、队列。
CopyOnWriteArrayList
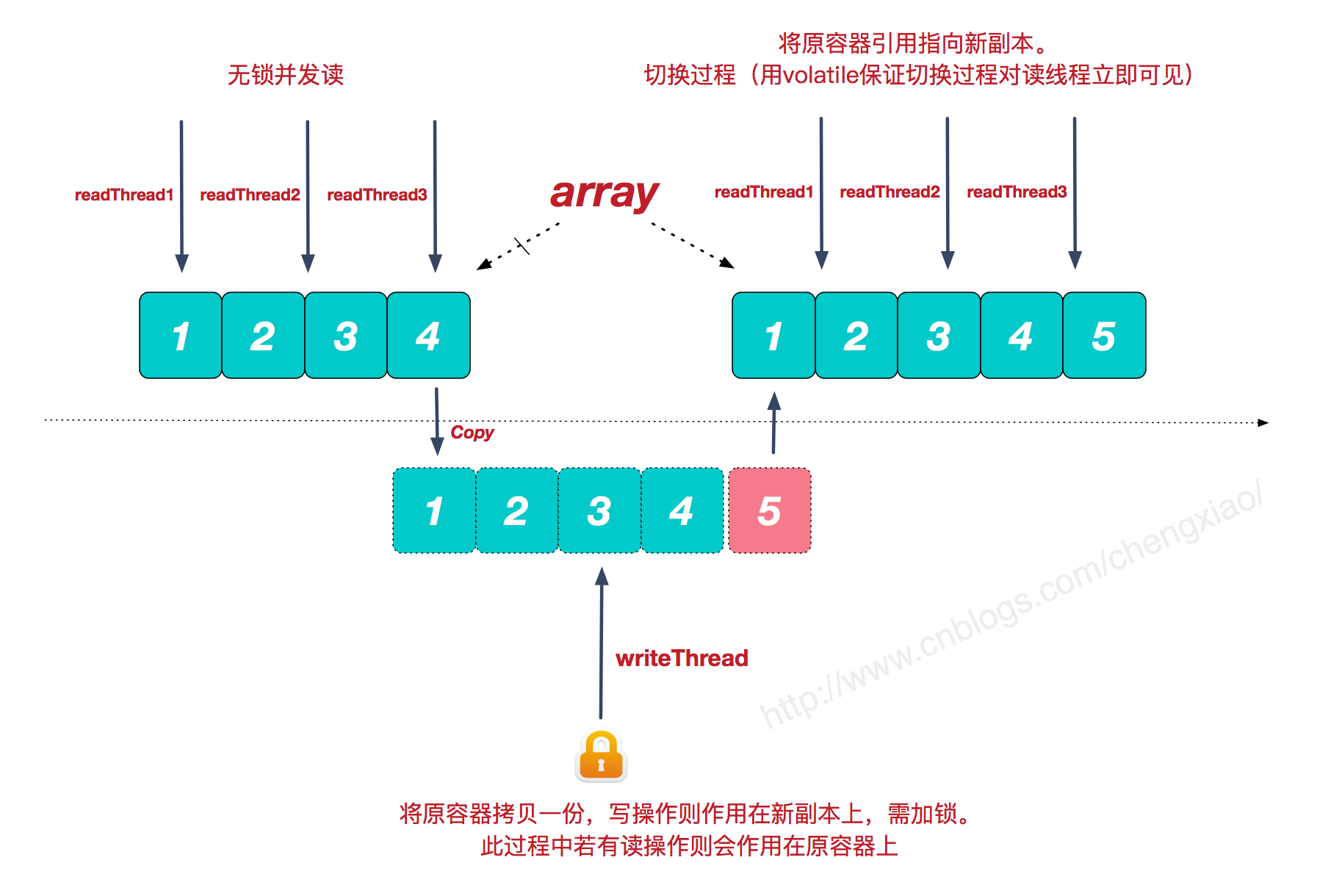
CopyOnWriteArrayList是一个线程安全的集合,适合读多写少的场景,读的时候不进行加锁,写的适合会加ReentrantLock,基于volatile修饰的Object[]数组实现,volatile确保数组引用的修改对所有线程立即可见。
CopyOnWriteArrayList为什么用ReentrantLock而不用Synchronized
ReentrantLock提供了比synchronized更精细的锁控制能力,它支持公平锁和非公平锁两种模式,ReentrantLock提供了tryLock()方法,可以尝试获取锁而不阻塞,如果获取失败可以立即返回,这种机制在某些高并发场景下很有价值。
HashSet
HashSet是无序的不运行重复,最多存储一个NULL元素,查询效率高,非线程安全,查询时是根据key的hashCode进行寻址,底层是基于HashMap实现的,HashSet的元素的HashMap的key,而HashMap的value是new Object()。
其扩容因子是0.75,扩容倍数是2倍,底层是数组+链表+红黑树,这些都同HashMap
TreeSet
TreeSet、具有自动排序和去重的特性,TreeSet的底层完全依赖于TreeMap,TreeSet的元素的TreeMap的key,而TreeMap的value是new Object()。TreeSet创建的时候可以进行自定义排序,如果不自定义的话会默认按照Unicode排序。
CopyOnWriteArraySet
基于写时复制机制,适合读多写少的场景。底层使用ReentrantLock保证写操作的线程安全,读操作完全无锁,性能优异
ConcurrentSkipListSet
基于跳表实现的有序线程安全Set,适合需要排序的高并发场景。
HashMap
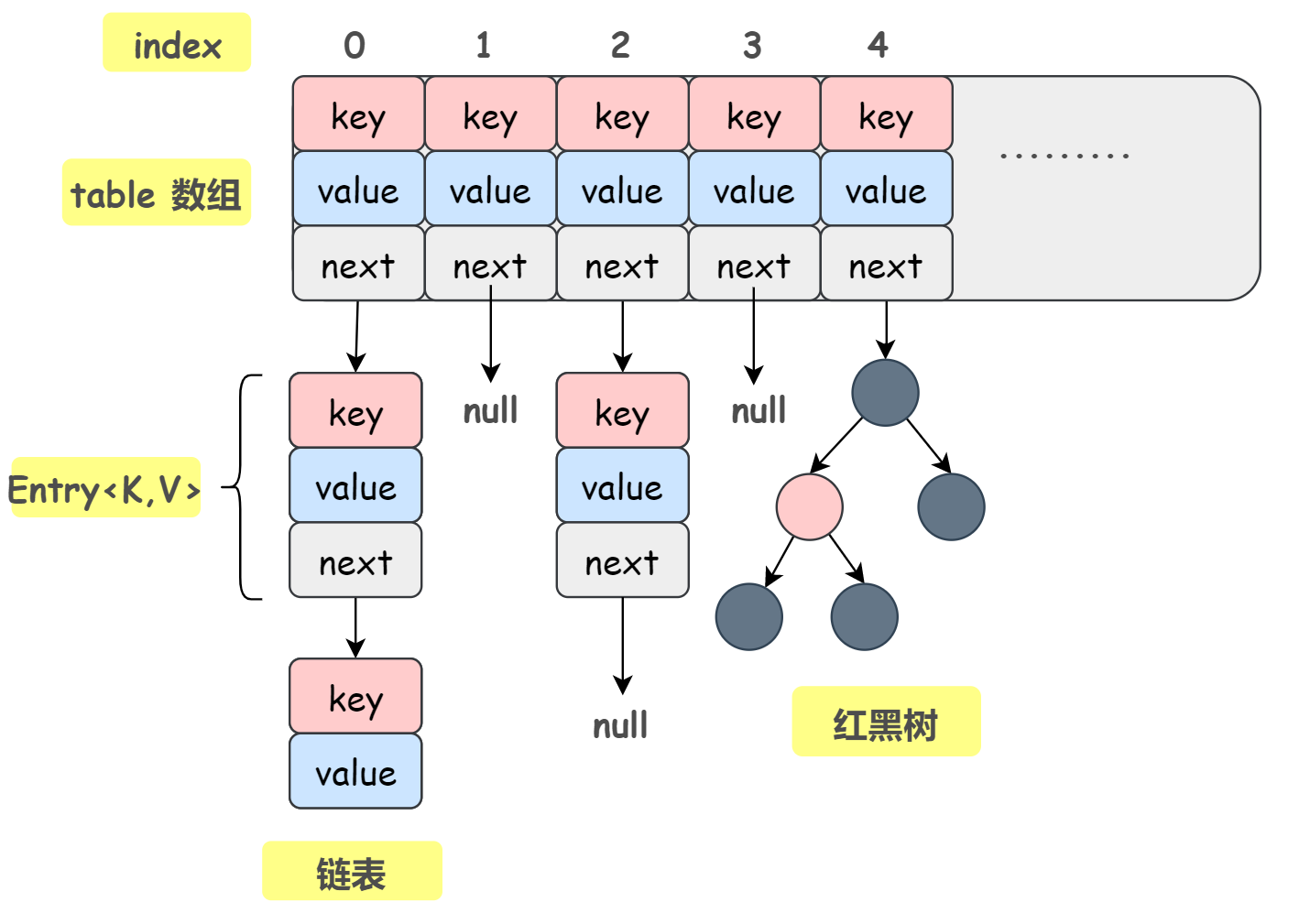
HashMap是键值对结构,无序、元素唯一,允许null作为键值,非线程安全,put的时候会根据对key进行哈希值计算数组下标。扩容因子是0.75,扩容倍数是2
JDK1.7底层是数组+链表,key的哈希计算是进行4次位运算和5次异或运算的复杂哈希计算
JDK1.8底层是数组+链表+红黑树,key的哈希是进行一次1次位运算和1次异或运算,显著提升了计算效率
HashMap为什么使用数组+链表+红黑树结构
主要是为了在解决哈希冲突和保证查询效率之间达到最佳平衡,当有hash冲突的时候会在数组下形成链表,当链表长度大于8的时候会转化为红黑树,当红黑树元素小于6的时候会转换为链表。
HashMap的链表和红黑树转换为什么是8呢
主要是基于空间和查询效率的平衡,如何链表过长会影响查询效率,如果链表过短就转化为红黑树,在数据存储的时候红黑树要进行颜色调整和旋转操作也会耗时。
根据泊松定理计算,在Hash联想的情况下链表达到8的几率很低,为千万分之六。
HashMap的扩容倍数为什么是2倍
HashMap选择2作为扩容倍数,主要基于计算效率、元素分布和扩容性能的综合考量。
计算效率:当扩容倍数是2的时候哈希值计算的时候(hash%容量)可转换为(hash & (容量- 1))这个位运算比取模操作快得多。
元素分布:2的幂次容量确保哈希值的低位能充分利用,让元素均匀分布在整个数组中,显著减少哈希冲突。
扩容性能:每次扩容倍数都是2的话可以让二进制的高低位参与运算,扩容后要么是原位置不变,要么是原位置+上扩容容量。(检查哈希值对应的新增高位是0还是1:如果是0,位置不变;如果是1,位置变为原索引+原容量。这样只需移动一半的数据,效率极高)
Hashmap的扩容因子为什么是0.75
HashMap的负载因子设为0.75,是空间利用率和时间效率之间的最佳平衡点,
负载因子过大(如0.9):扩容次数减少,内存利用率高,但哈希冲突概率显著增加,导致查询性能下降
负载因子过小(如0.5):哈希冲突减少,查询效率高,但会导致频繁扩容和内存浪费
根据泊松分布,当负载因子为0.75时,链表长度达到树化阈值8的概率极低,为千万分之六。
HashMap的查询顺序和插入顺序一样吗
不一样,HashMap存储的时候是根据key进行哈希计算出存储的位置,元素是散列在数组上的,而查询是按照数组的顺序查询的,所有查询的顺序和插入顺序不一致,另外扩容后元素的值也会被重新计算。
Hashtable
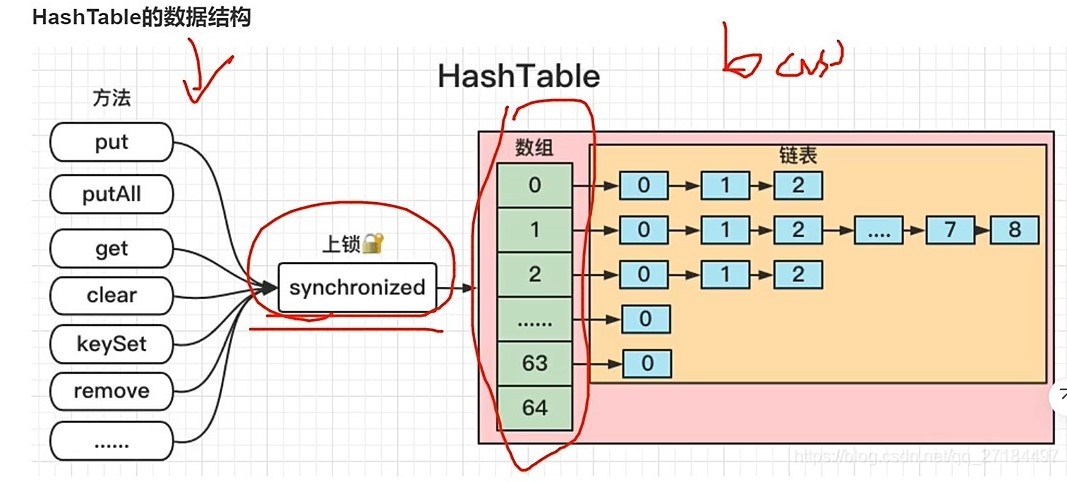
Hashtable是一个线程安全的集合,Hashtable的操作都会使用synchronized关键字进行加锁来确保数据安全,底层是数组+链表,不允许key和value为空。
TreeMap
TreeMap是有序,元素唯一,允许值为空,不允许键为空,底层是红黑数实现,创建的时候可以实现自定义排序,如果不实现按照Unicode码排序。
ConcurrentHashMap
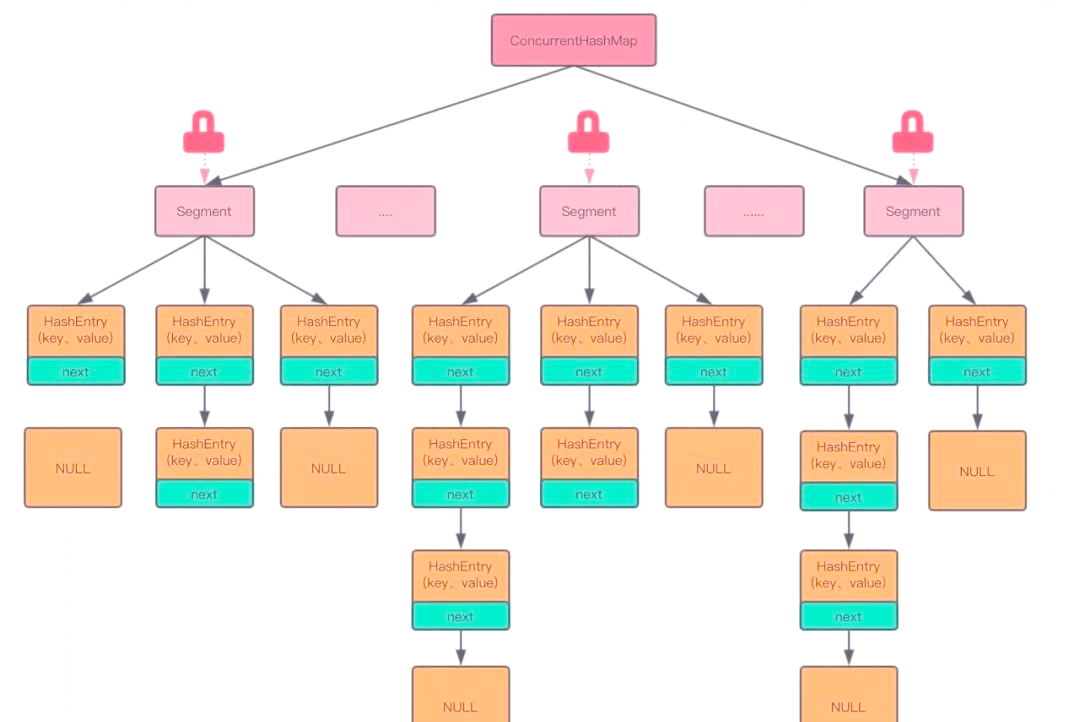
JDK1.7:底层是数组+链表,使用分段锁机制,采用分段锁策略,默认由16个 Segment 组合而成,其中 Segment 可以看成一个 HashMap, 不同点是 Segment 继承自 ReentrantLock,在进行数据操作的时候会锁住对应是Segment,不同Segment的并发写入。
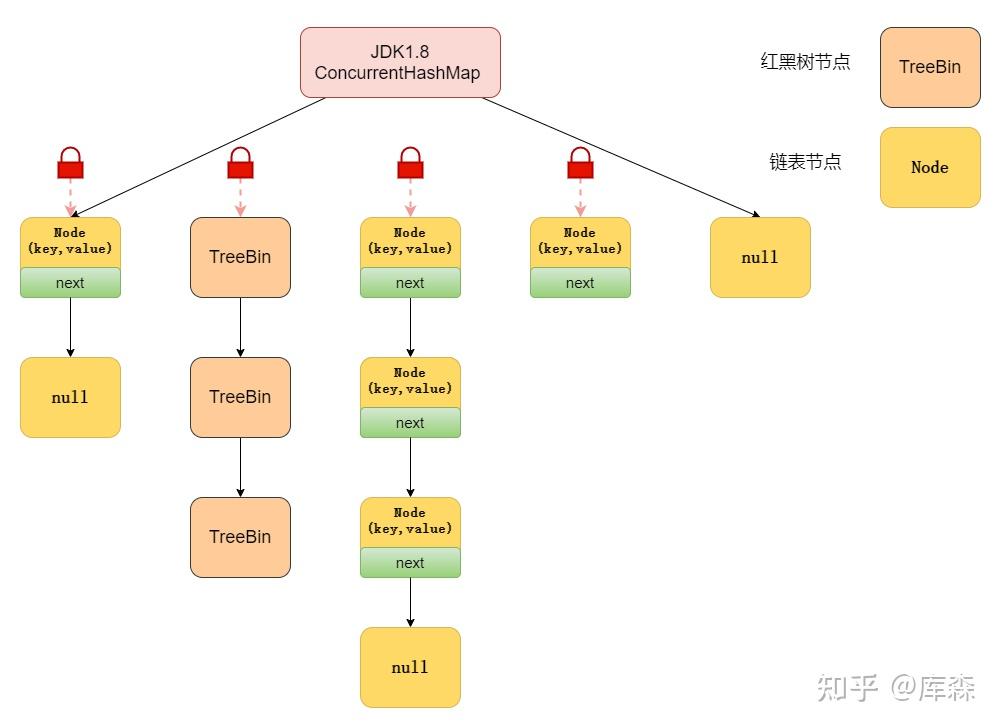
JDK1.8:底层是数组+链表+红黑树,使用CAS+synchronized关键字来实现线程安全,数据写入的时候锁定是对应是数组Node节点,相比JDK1.7锁的粒度更细,并发性更高
CAS 操作
CAS(Compare-And-Swap)是一种无锁的算法,用于在不使用锁的情况下实现多线程间的原子操作。在 ConcurrentHashMap 中,CAS 被用于无锁的计数器(例如扩容时的大小更新)和在某些情况下对节点的访问更新。例如,在尝试将一个节点添加到链表或树结构时,如果发现该节点的状态已经改变(比如已经被其他线程修改),则重新尝试。
synchronized 关键字
尽管 JDK 8 的 ConcurrentHashMap 不再使用分段锁,但在某些关键的操作上仍然使用了 synchronized 关键字来保证线程安全。例如,在计算哈希表大小、初始化 table 或进行某些结构性修改(如扩容)时,会使用到 synchronized 块。这些操作虽然不是频繁的,但它们是必要的,以确保在并发环境下的数据一致性。
示例:JDK 8 中的 ConcurrentHashMap 实现细节
在 JDK 8 中,每个桶(bucket)可以包含一个链表或者一棵红黑树。当一个链表长度超过一定阈值(默认为 TREEIFY_THRESHOLD,值为 8)时,链表会被转换为红黑树以优化搜索性能

 浙公网安备 33010602011771号
浙公网安备 33010602011771号