

面试刷题暂存
1.Java中内存数据为什么是不可见的。
2.JMM是什么,作用是什么
3.Java中有那些锁,区别是什么
4.乐观锁和悲观锁的区别。
5.CAS最后有没有加索
6.java中锁是如何实现的。
7.为什么HashMap中的key和value允许为null,但是concurrentHasMap不允许。
8.hash冲突的话有几种解决方式
9.如何用Runable实现Callable的功能。
9.ThreadLocal的应用场景有那些,k和v分别是什么。
10.子线程如何获取父线程的属性信息。
1.Java中内存数据为什么是不可见的。
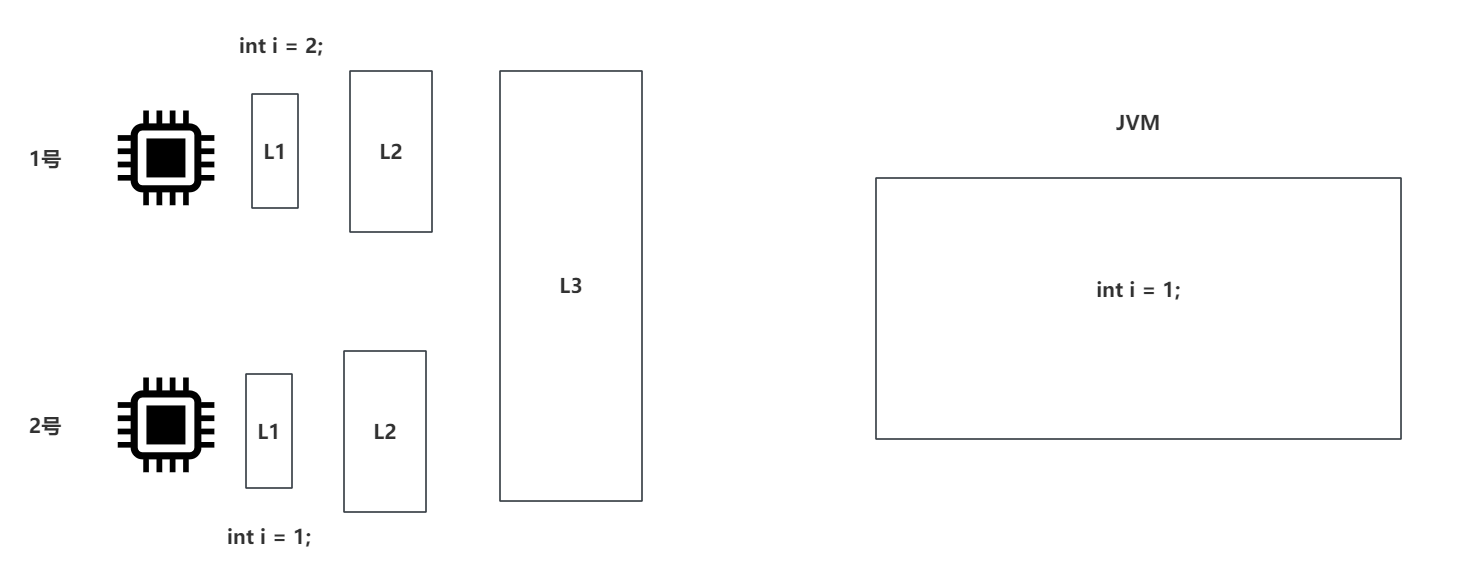
1.目前机器都是多CPU运行的,当我们有个常量i在JVM内存中被多个线程同时访问,CPU执行时会把常量拉到自己的缓存中,当线程A对长量i进行修改,修改完成后刷新到了自己的L1缓存,并没有刷新到主缓存中,所以线程B是拿不到这个常量i更改后的值。
当线程i被线程刷新到主缓存中线程B才会读取到被修改后的值。
联想:
多线程操作同一数据会产生脏数据问题:
1.可以使用synchronized和Lock锁,保证同一时间只有一个线程操作此资源。
2.可以使用atomic下的类,atomic使用是CAS原理实现,也是乐观锁的一种。
3.使用线程安全的ConcurrentHashMap或CopyOnWriteArrayList进行数据存储。
为什么CurrentHashMap会保证多线程操作资源时数据安全。
1.ConcurrentHashMap会将数据分为多段segment,多段segment分别加锁,并发情况下不同线程访问不同的segment,显著减少锁竞争。
2.ConcurrentHashMap也使用CAS+局部synchronized来解决多线程下操作同一资源的情况:当多线程来操作同一资源时写操作会进行加锁,保证同一时刻只有一个线程操作数据。线程A、B同时来操作一个资源,先谁拿到锁谁先执行,另外一个自旋等待。
3.ConcurrentHashMap也使用volatile修饰,保证数据在内存中的可见性。
为什么CopyOnWirteArrayList会保证多线程操作时数据安全。
1.CopyOnWriteArrayList使用的先复制后写的原理,当线程来操作CopyOnWriteArrayList时会先进行加锁,加锁后进行数组复制,新增或修改的数据操作的是新数组,操作完成后会将指针指向新的数组。
2.CopyOnWriteArrayList也使用volatile修饰,保证数据在内存中的可见性。
3.CopyOnWriteArrayList使用于读多写少的情况,否则会造成资源浪费或造成系统大量GC。
4.CopyOnWriteArrayList可在黑名单系统中使用(读多写少)
为什么volatile保证内存的可见性
1.禁止重排序和强制刷新内存
2.常量使用volatile关键字,读的时候强制读取主内存的数据保证是最新的,写的时候需要把最新的数据回写到主内存
3.指令重排:指计算机编译器和处理器为了提高执行效率,对指令进行优化重排,目的是为了减少CPU空闲时间和提高内存使用率,进而提升程序执行顺序。
4.并非情况下无法保证数据安全,需业务进行加锁操作。
2.JMM是什么,作用是什么
JMM是java的内存模型是一个抽象的概念主要是屏蔽操作系统之间的不同保证java程序在各个操作系统上都能达到一致的运行,其三个核心理念:原子性、可见性、有序性
原子性:操作的连续性,要么同时成功要么同时失败,不会受其他线程干扰。
可见性:线程对共享变量操作后要立刻刷新到主内存中,避免其余线程读取到的是旧址。
有序性:程序执行顺序和代码书写顺序一致,避免操作系统或CPU对程序执行顺序优化导致异常。
3.Java中有那些锁,区别是什么
1.java中的锁主要分为乐观锁和悲观锁,其中synchronized、Lock是悲观锁,CAS是乐观锁。
2..悲观锁认为我操作的时候一定会有其余的线程竞争,如果我未竞争到锁就结束或阻塞等待(tryLock)。
3.乐观锁认为我在操作的时候不会有其余的线程竞争,如果有竞争就自旋等待(CAS)或异常结束(数据库多版本机制)
4.锁的细化
7.为什么HashMap中的key和value允许为null,但是ConcurrentHasMap不允许。
1.HashMap设计之初就是在单线程中使用,key和value都是可控范围的。
2.ConcurrentHashMap设计时就是在多线程情况下使用,如果运行为空会造成寓意混乱的情况,因为get()时不知道是未获取到值,还是key不存在。
8.hash冲突的话有几种解决方式
1.链地址法:HashMap解决冲突的经典方式,hashMap底层是诉诸,hash冲突时会在冲突位置追加链表,将新冲突的值插入链表的尾部。HashMap在JDK1.8的时候进行了优化当链表长度>8且哈希表容量>64时将链表转换成红黑树进而提升查询效率。
2.多次hash法:布隆过滤器的思想。
9.如何用Runable实现Callable的功能
1.Runnable和和Callable的区别是Callable有返回值和可抛异常
内存泄漏的场景有哪些?
1. 静态集合类的不当使用:静态集合(如static List、static Map)生命周期与JVM一致,存储的对象即使不再使用也因集合引用而无法回收。
public class LeakyClass { private static List<Object> staticList = new ArrayList<>(); public void addToStaticList(Object obj) { staticList.add(obj); // 对象被静态集合永久持有 } }
2.未关闭的资源连接:数据库连接、网络连接、文件流等资源未显式关闭,导致对象无法回收。
public void fetchData() { Connection conn = DriverManager.getConnection(url); // 未关闭连接 Statement stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery(query); }
3.ThreadLocal使用不当:线程池中线程复用,ThreadLocal变量未清理,导致无效数据累积。
public class ThreadLocalCleanup { private static final ThreadLocal<byte[]> threadLocal = new ThreadLocal<>(); public static void main(String[] args) { ExecutorService executor = Executors.newFixedThreadPool(2); for (int i = 0; i < 5; i++) { executor.submit(() -> { try { threadLocal.set(new byte[1024 * 1024 * 5]); // 5MB数据 // 模拟业务处理 Thread.sleep(1000); } catch (InterruptedException e) { Thread.currentThread().interrupt(); } finally { threadLocal.remove(); // 关键清理操作 } }); } executor.shutdown(); } }
10.ThreadLocal的应用场景有那些,k和v分别是什么,内存泄漏的原因。
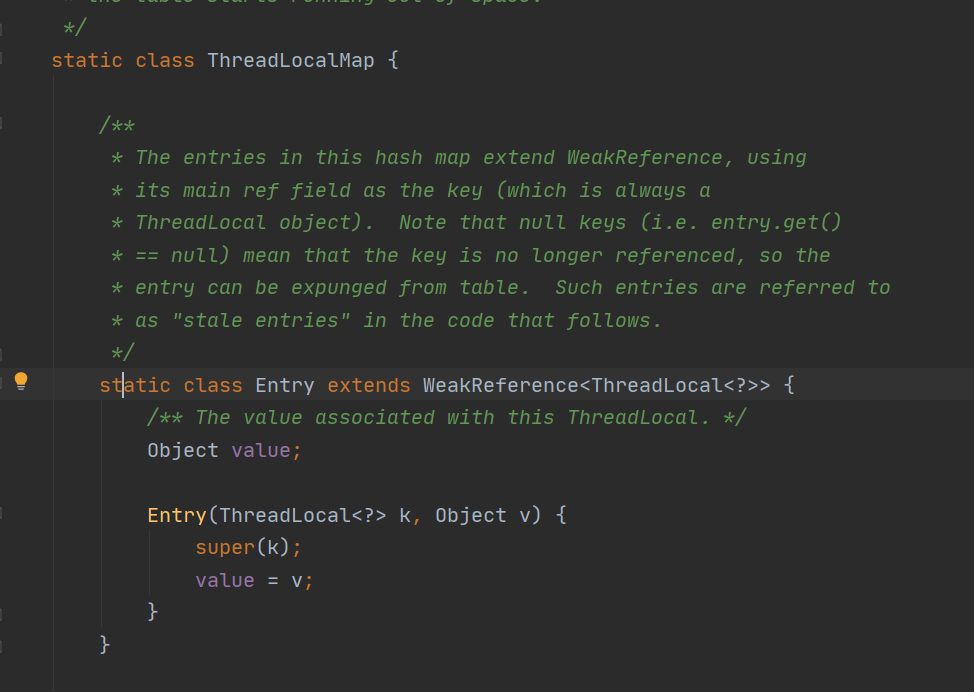
1.ThreadLocal是线程局部变量,主要作用实现同一个线程之间参数传递,ThreadLocal其实是Thread和ThreadLocalMap之间的一个工具。
ThreadLocal本身不存储数据,真正存储数据的是每个线程Thread对象中的ThreadLocalMap属性,ThreadLocalMap的key是threadLocal(Thread 对象的 threadId),value是threadLocal存放的值。使用ThreadLocal进行get/set本质才操作的是当前线程的ThreadLocalMap。
2.主要场景是事务控制,日志追踪,用户登录拦截中获取用户信息。
3.内存泄漏有两个原因
1当使用ThreadLocal玩花活时,把ThreadLocal当中私有变量操作,在使用线程池创建线程的情况下方法执行结束,方法内的是私有变量被回收, 但是ThreadLocal无法被会回收,因为线程中的ThreadLocalMap指向的ThreadLocal,
所以在ThreadLoacl设计之初将key设置为了弱引用,此时ThreadLoacl只有一个弱引用指向,所以ThreadLocal可以正常回收,但是ThreadLocalMap的value无法被回收就会导致内存泄漏。
2当ThreadLocal作为共享变量使用,在使用线程池创建线程的情况下,方法内未进行remove,方法执行结束但是未对线程中的ThreadLocalMap进行释放就会导致内存泄漏。
11.强引用和弱引用
1.强引用就是我们使用new()创建的对应,只要强引用存在垃圾回收就不会回收对象,即使内存不足也宁愿抛出OOM。
2.弱引用需要被WeakReference类包装,弱引用不会增加程序计数,当一个对象仅有弱引用指向,垃圾回收机制会回收这个对象
12.内存泄漏和内存溢出的区别
1.内存泄漏是指对象申请的地址不释放,导致内存持续升高,最终也会导致OOM
2.内存溢出是指对象申请的内存空间大于JVM剩余的内存控制,导致OOM。
进程、线程、协程的区别
java中创建线程的方式有几种
如果结束线程
ThreadLocal的作用和内存泄漏的原因
伪共享的问题以解解决方案
CPU缓存可见性问题发生的原因。
1.进程、线程、协程的区别
1.进程是操作系统分配和调度的最小单元,进程有独立的资源空间。
2.线程是CPU调度的最小单元,一个进程可以有多个线程
3.协程是轻量级线程,JDK21之后可以直接创建协程进而减少用户态和内存态的切换。
2.java中创建线程的方式有几种
1.创建Runnable对象使用Thread.start运行线程。
2.创建Callable对象使用Exc.submit运行线程。
3.使用线程池创建对象
4.继承Thread
3.如果结束线程
1.线程正常执行结束
2.使用stop方法,但是stop已经过时了
2.标志位执行可以直接调用Interrupted或自定义标志位结束
代办:
Future和futureTask的区别
Future是异步执行结果,Callable
FutureTask实现了RunnableFuture,创建FutureTask需要实现Runnable或Callable,使用Executor的submit执行Callable的call方法,使用excute执行执行Runnable的run方法
1.单例模式的DCL为什么要加volatil
2.CAS实现原理
3.synchronized实现原理
4.synchronized锁升级过程。
5.AQS是什么。
6.公平锁和非公平锁的区别
1.介绍下单例模式,有几类,单例模式为什么要进行双检索,加锁后为什么还要在判空一次,双检索模式为什么要加volatile。
1.单例模式保证一个类在JVM中只有一个实例,在传统的开发中单例模式可用来实现数据库连接池、线程池、统一日志框架,有了spring后可以直接使用@Compont、@Bean进行容器注入,这个两个默认是单例默认,传统的是编程式开发,spring是配置式开发。
2.单例模式有饿汉、懒汉、双检索
3.第一次检索是判断有没有对象实例,第二次是为了保证只创建一个实例,线程并发时线程A拿到锁进行数据实例,完成实例后线程A释放锁,这个时候线程B通过第一层校验发现实例是null,拿到锁后直接进行数据实例,实例被创建了两次,所以加锁后还要在进行一次判空。
如果没有第二层判空会被多次实例,如果是数据库连接池,就会有两套数据库实例,占用的数据库连接就会翻倍,数据库连接的缓存不一样也可能造成脏数据,如果是全局生产唯一ID,duog
4.对象实例volatile主要是为了防止指令重排和可见性,如果不加volatile理论上会出现NullPointerException,操作系统和处理器为了提升运行效率会对操作指向的顺序进行优化,正常创建对象的过程:1.开辟内存空间、2.实例化对象,3.指针指向堆内存空间,不加volatile会变为1.开辟内存空间、3.指针指向堆内存空间、2.实例化对象这样当别的线程来获取对象时就有可能是空指针
5.加了volatile后数据更新后会立刻刷新到主内存,读取数据必须去主内存获取,避免脏读。
2.CAS实现原理
1.CAS是乐观锁思想实现的,主要解决线程并发问题,其原理是新值、旧值、预期值的比较与交换,当且仅当旧址和预期值相同的情况才会把旧址改为新值,JAVA中是基于unsafe类提供的方法实现的,CAS是CPU基本的原子操作 。
2.java中Atomic类的方法是基于CAS实现的,MySql数据的多版本控制也是基于CAS实现的。
3.CAS存在ABA问题。当共享变量经历A→B→A的值变化时,CAS仅检查最终值是否与预期值相同(均为A),而忽略中间被修改为B的过程,导致逻辑误判。JAVA中提供了解决ABA的方案,可以使用AtomicstampedReference<V>来解决。
乐观锁:
悲观锁:
CAS:CAS对JAVA来说就是一个方法,CAS只会进行一次比较交换,(不会挂起线程,线程状态从运行到阻塞)
自旋锁:可以自己实现,循环进行CAS直到成功。
自适应自旋锁:相对智能的自旋锁,上次结果成功了我就多尝试几次,上次结果执行失败了,我就少尝试几次,synchronized的轻量级锁就用的了自适应自旋锁。
3.synchronized实现原理和锁升级
1.synchronized是一共互斥锁,只能有一个线程持有这把锁,synchronized中有个owner属性,owner存放的是持有当前锁的线程,当owner为null的时候其余线程可以通过CAS进行owner修改,如果修改成功则当前线程持有锁,如果修改失败则进行几次CAS,没有拿到就信息park挂起线程。
4.synchronized锁升级过程。
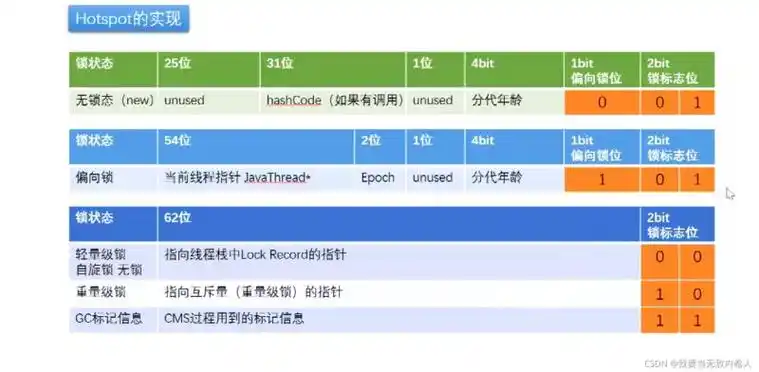
1.无锁:当前对象没有被任何锁资源占用&&在JDK1.8后会有个4S的偏向锁延迟,JVM刚刚启动的4S中,不存在偏向锁状态。
2.偏向锁:
撇去4S的延迟,刚创建出来的都行都是偏向锁(匿名偏向)
当前对象被作为锁资源占用,且指向了某一线程此时就是偏向锁(普通偏向)
如果一个线程执行任务后,反复的获取同一把锁,这个时候偏向锁的优势就体现出来了,无需进行CAS操作,直接比较线程指向是否相同,相同则直接获取锁。
3.轻量级锁:在偏向锁的状态下,锁资源出现了经常,就会升级为轻量锁。轻量锁状态下会进行几次CAS操作将owen修改为自己的线程,默认是10次,这里的CAS操作走的自适应自旋锁。
4.重量级锁:在轻量级锁状态下,轻量级锁竞争失败,就会升级为重量级锁,重量级锁也会进行几次CAS操作将owen修改为自己的线程,如果成功就直接拿锁执行任务,如果失败则挂起线程,等起锁释放后被唤醒。
5.AQS是什么
1.AQS(AbstractQueuedSynchronized)其实JUC下一个基础类,没有具体是实现并发功能,但是大多数JUC包下的类都继承了AQS,如;ReentrantLock,CountDownLatch、线程池等等、
2.AQS核心的是同步状态管理和线程队列机制
2.1.AQS中有一个被volitail修饰的state,当state = 0时表示没有线程持有锁资源,当state>0时表现有线程持有资源。
2.2Node节点组成的双向队列:当出现锁竞争的时候,未竞争到锁的线程会作为node节点存放到双向队列中。
2.3Node对象节点组成的单向链表:当线程持有锁的时候执行了await命令,线程会释放锁,此时当前线程会作为node节点存放到单线链表中,当接受到signal时会从单向链表转移到双向队列参与锁竞争。
6.公平锁和非公平锁的区别
1.公平锁支持先进先出,先到的线程先获取锁。
2.非公平锁允许线程执行CAS竞争,谁拿到锁谁就去执行任务,其余的就排队。
ReentrantLock中有两个方法决定实现公平和非公平之分。
lock:
非公平锁:线程直接执行CAS尝试将state从0修改为1,如果修改成功拿锁走人,修改失败调用tryAcquire。
公平锁:执行执行tryAcqurie。
tryacquire方法:
非公平锁:线程直接执行CAS尝试将state从0修改为1,如果修改成功拿锁走人,失败了就排队。
公平锁:如果state=0且有线程排队则直接给最先进来的线程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号