随机森林
【随机森林】是由多个【决策树】构成的,不同决策树之间没有关联。
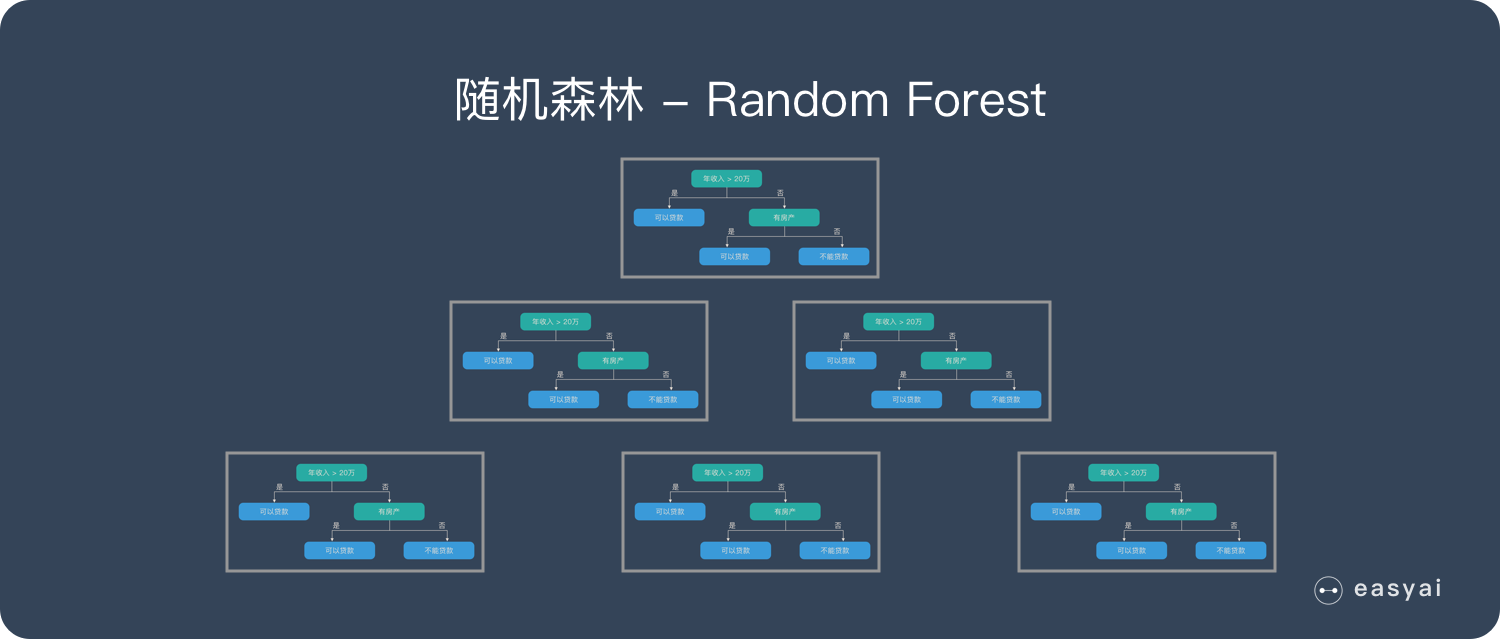
特点
- 可以使用特征多数据,且无需降维使用,无需特征选择。
- 能够进行特征重要度判断。
- 能够判断特征间的相关影响
- 不容器过拟合。
- 训练速度快、并行。
- 实现简单。
- 不平衡数据集、可平衡误差。
- 特征遗失的数据,仍可以维持准确度。
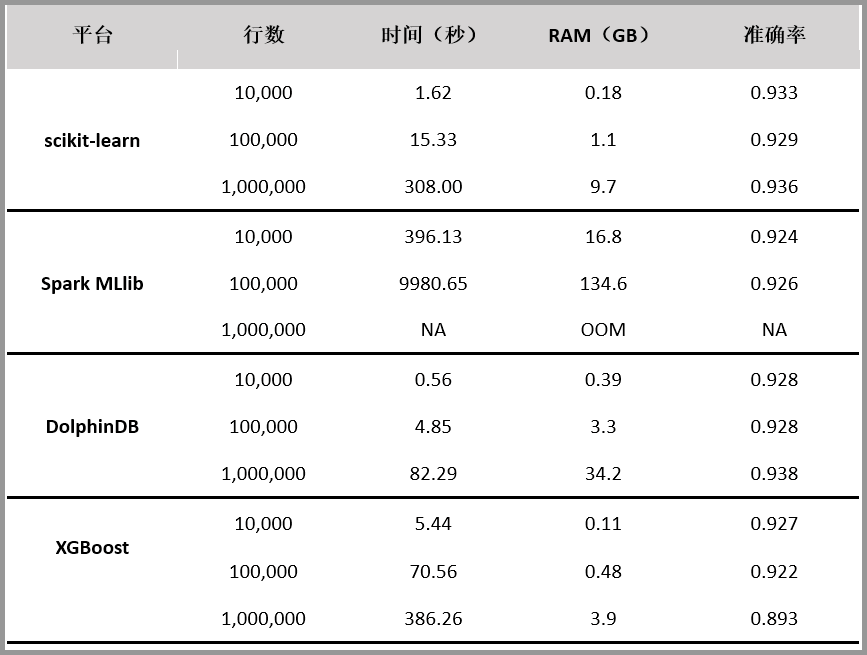
支持平台
- scikit-learn
- Spark MLlib
- DolphinDB
- XGBoost
准确度
使用步骤
- 随机抽样,训练【决策树】
- 随机选属性,做节点分裂属性
- 重复步骤2,直到不能再分裂。
- 建立大量决策树、形成森林。
应用方向
- 分类 (对离散值的分类)
- 回归 (对连续值的回归)
- 聚类 (无监督学习聚类)
- 异常检测

 浙公网安备 33010602011771号
浙公网安备 33010602011771号