
通用卷积核用于模型压缩和加速
介绍一下最近看的一种通用卷积核用于模型压缩的方法,刚刚查了一下,原作者的博客在https://zhuanlan.zhihu.com/p/82710870 有介绍,论文传送门 https://papers.nips.cc/paper/7433-learning-versatile-filters-for-efficient-convolutional-neural-networks.pdf , github开源地址 https://github.com/huawei-noah/Versatile-Filters
下面介绍下我的理解。
这种模型压缩方法分为两步,一步是在spatial-wise的,一步是在channel-wise的,其实思想是一样的,这两步也就对应着我们平常一个filter, 假设是7x7x24x100,那么7x7对应的就是spatial-wise,24对应的就是channel-wise。24是input feature的深度,这个没法变就不管了。从spatial的角度来说,这100个input的filters,每个都是7x7x24,其实没有必要有100个,25个就可以了,怎么说呢?7x7的这个filter可以拆成7x7,5x5,3x3,1x1,就是4个子卷积核,那么其实有25个7x7x24的filter,就可以变换出100个filter了。这个7x7怎么拆呢?如下图,以5x5的为例,就是中间这个(b)图,5x5的卷积核就是最大的这个部分,3x3的子卷积核就是绿色加中间这个部分,其实是5x5的卷积核的一部分参数,相当于外面蓝色一圈填0,1x1的子卷积核就是中间这个红点点,这样三个子卷积核都是由5x5的卷积核变换而来,参数共享,其实在实际计算的时候,还可以实现计算共享,比起实际用3个5x5卷积核,计算量是要省的,参数大小也少了,memory的要求也降低了。
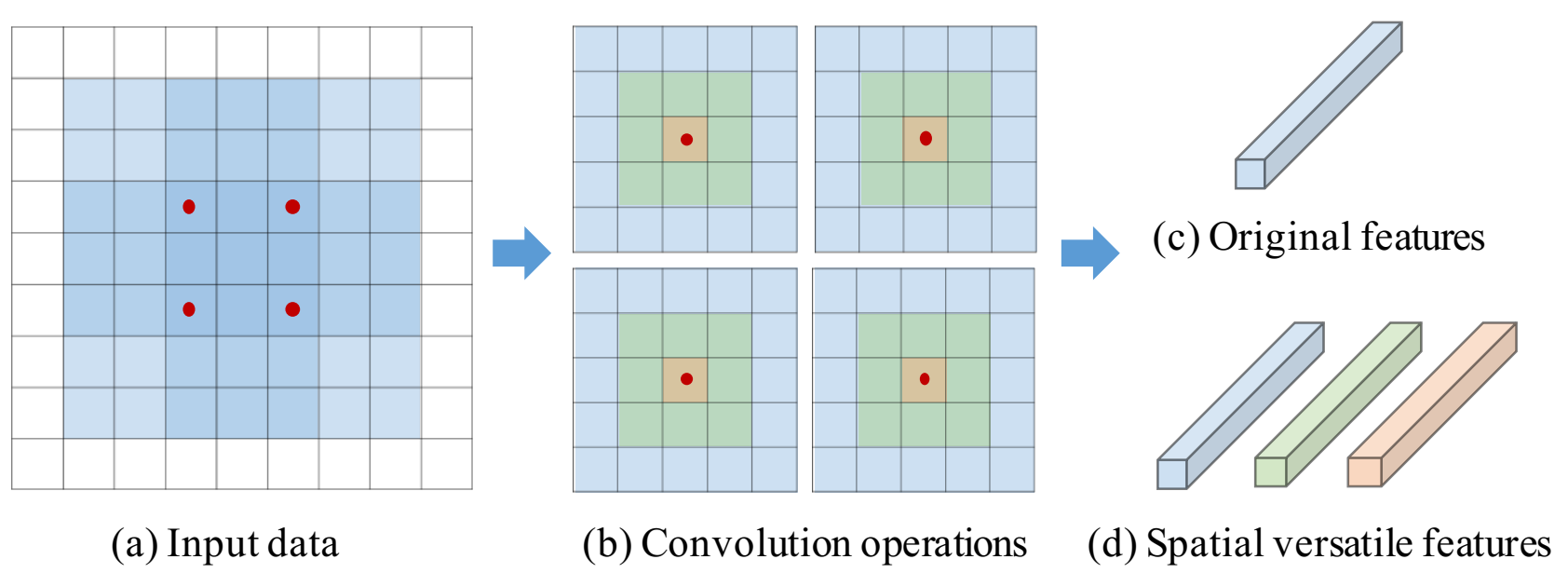
另一种就是channel-wise的压缩,基本思想跟上面的是完全一样的,这一次是在深度24这个方向上进行拆分,比如,1到22为一个子卷积核,3到24为一个子卷积核,这样就可以有两个卷积核了,结合上面的spatial-wise的压缩,就只要13个7x7x24的filter就可以了。与spatial-wise不同的是上一次出现了7x7卷积本尊,这一次没有24个channel的全的了。这样计算量也是要节省的,只有原来的22/24,并且中间还有一些结果是可以复用的,实际上会更省一些。

以上大概就是这个方法的精髓了。作者在图像分类和图像超分辨率几个经典网络上验证了自己的想法,证明了此方法的有效性。
=========================================
关于这个方法,我有一些疑问,其实这种方法降低了参数的自由度,那么他为什么还可以达到和之前的网络一样的效果?是不是之前的网络参数就有很多冗余,或者说其实这样的选取参数是有意义的,其实是基于某种先验。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号