
golang数组 切片 映射注意事项
从数组或者切片派生切片(取子切片)
o中有两种取子切片的语法形式(假设baseContainer是一个切片或者数组):
baseContainer[low : high] // 双下标形式 baseContainer[low : high : max] // 三下标形式
上面所示的双下标形式等价于下面的三下标形式:
baseContainer[low : high : cap(baseContainer)]
所以双下标形式是三下标形式的特例。在实践中,双下标形式使用得相对更为广泛。
(注意:三下标形式是从Go 1.2开始支持的。)
上面所示的取子切片表达式的语法形式中的下标必须满足下列关系,否则代码要么编译不通过,要么在运行时刻将造成恐慌。
// 双下标形式 0 <= low <= high <= cap(baseContainer) // 三下标形式 0 <= low <= high <= max <= cap(baseContainer)
下面我们举几个案例:
注意:from ,to 都是从下标0开始计算
baseContainer[from:to]
baseContainer[3:5] //表示包含下标为3的数值,不包含下包为5的数值
s := make([]int, 0, 6) s = append(s,[]int{1,2,3,4,5,6}...) //s[包含下标:不包含下标] //注意:from to 下标从0开始数 fmt.Println(s[3:]) // 4 5 6 [from:] 包含下标为3的值 fmt.Println(s[:3]) // 1 2 3 [:to] 不包含下标为3的值 fmt.Println(s[3:4]) //4 [from:to) 左闭右开 from <= s < to 包含下标为3的 不包含下标为4的
一些关于遍历映射条目的细节:
- 映射中的条目的遍历顺序是不确定的(可以认为是随机的)。或者说,同一个映射中的条目的两次遍历中,条目的顺序很可能是不一致的,即使在这两次遍历之间,此映射并未发生任何改变。
- 如果在一个映射中的条目的遍历过程中,一个还没有被遍历到的条目被删除了,则此条目保证不会被遍历出来。
- 如果在一个映射中的条目的遍历过程中,一个新的条目被添加入此映射,则此条目并不保证将在此遍历过程中被遍历出来。
如果可以确保没有其它协程操纵一个映射m,则下面的代码保证将清空m中所有条目。
for key := range m { delete(m, key) }
当然,数组和切片元素也可以用传统的for循环来遍历。
for i := 0; i < len(anArrayOrSlice); i++ { element := anArrayOrSlice[i] // ... }
对一个for-range循环代码块
for key, element = range aContainer {...}
有三个重要的事实存在:
- 被遍历的容器值是
aContainer的一个副本。 注意,只有aContainer的直接部分被复制了。 此副本是一个匿名的值,所以它是不可被修改的。- 如果
aContainer是一个数组,那么在遍历过程中对此数组元素的修改不会体现到循环变量中。 原因是此数组的副本(被真正遍历的容器)和此数组不共享任何元素。 - 如果
aContainer是一个切片(或者映射),那么在遍历过程中对此切片(或者映射)元素的修改将体现到循环变量中。 原因是此切片(或者映射)的副本和此切片(或者映射)共享元素(或条目)。
- 如果
- 在遍历中的每个循环步,
aContainer副本中的一个键值元素对将被赋值(复制)给循环变量。 所以对循环变量的直接部分的修改将不会体现在aContainer中的对应元素中。 (因为这个原因,并且for-range循环是遍历映射条目的唯一途径,所以最好不要使用大尺寸的映射键值和元素类型,以避免较大的复制负担。) - 所有被遍历的键值对将被赋值给同一对循环变量实例。
下面这个例子验证了上述第一个和第二个事实
package main import "fmt" func main() { type Person struct { name string age int } persons := [2]Person {{"Alice", 28}, {"Bob", 25}} for i, p := range persons { fmt.Println(i, p) // 此修改会体现在这个遍历过程中, persons[1].name = "Jack" // 此修改不会反映到persons数组中,因为p // 是persons数组的副本中的一个元素的副本。 p.age = 31 } fmt.Println("persons:", &persons) }
输出结果:
0 {Alice 28} 1 {Bob 25} persons: &[{Alice 28} {Jack 25}]
如果我们将上例中的数组改为一个切片,则在循环中对此切片的修改将在循环过程中体现出来。 但是对循环变量的修改仍然不会体现在此切片中。
... // 改为一个切片。 persons := []Person {{"Alice", 28}, {"Bob", 25}} for i, p := range persons { fmt.Println(i, p) // 这次,此修改将反映在此次遍历过程中。 persons[1].name = "Jack" // 这个修改仍然不会体现在persons切片容器中。 p.age = 31 } fmt.Println("persons:", &persons) }
输出结果变成了:
0 {Alice 28} 1 {Jack 25} persons: &[{Alice 28} {Jack 25}]
下面这个例子验证了上述的第二个和第三个事实:
package main import "fmt" func main() { langs := map[struct{ dynamic, strong bool }]map[string]int{ {true, false}: {"JavaScript": 1995}, {false, true}: {"Go": 2009}, {false, false}: {"C": 1972}, } // 此映射的键值和元素类型均为指针类型。 // 这有些不寻常,只是为了讲解目的。 m0 := map[*struct{ dynamic, strong bool }]*map[string]int{} for category, langInfo := range langs { m0[&category] = &langInfo // 下面这行修改对映射langs没有任何影响。 category.dynamic, category.strong = true, true } for category, langInfo := range langs { fmt.Println(category, langInfo) } m1 := map[struct{ dynamic, strong bool }]map[string]int{} for category, langInfo := range m0 { m1[*category] = *langInfo } // 映射m0和m1中均只有一个条目。 fmt.Println(len(m0), len(m1)) // 1 1 fmt.Println(m1) // map[{true true}:map[C:1972]] }
上面已经提到了,映射条目的遍历顺序是随机的。所以下面前三行的输出顺序可能会略有不同:
{false true} map[Go:2009]
{false false} map[C:1972]
{true false} map[JavaScript:1995]
1 1
map[{true true}:map[Go:2009]]
复制一个切片或者映射的代价很小,但是复制一个大尺寸的数组的代价比较大。 所以,一般来说,range关键字后跟随一个大尺寸数组不是一个好主意。 如果我们要遍历一个大尺寸数组中的元素,我们以遍历从此数组派生出来的一个切片,或者遍历一个指向此数组的指针(详见下一节)。
对于一个数组或者切片,如果它的元素类型的尺寸较大,则一般来说,用第二个循环变量来存储每个循环步中被遍历的元素不是一个好主意。 对于这样的数组或者切片,我们最好忽略或者舍弃for-range代码块中的第二个循环变量,或者使用传统的for循环来遍历元素。 比如,在下面这个例子中,函数fa中的循环效率比函数fb中的循环低得多。
type Buffer struct { start, end int data [1024]byte } func fa(buffers []Buffer) int { numUnreads := 0 for _, buf := range buffers { numUnreads += buf.end - buf.start } return numUnreads } func fb(buffers []Buffer) int { numUnreads := 0 for i := range buffers { numUnreads += buffers[i].end - buffers[i].start } return numUnreads }
把数组指针当做数组来使用
对于某些情形,我们可以把数组指针当做数组来使用。
我们可以通过在range关键字后跟随一个数组的指针来遍历此数组中的元素。 对于大尺寸的数组,这种方法比较高效,因为复制一个指针比复制一个大尺寸数组的代价低得多。 下面的例子中的两个循环是等价的,它们的效率也基本相同。package main import "fmt" func main() { var a [100]int for i, n := range &a { // 复制一个指针的开销很小 fmt.Println(i, n) } for i, n := range a[:] { // 复制一个切片的开销很小 fmt.Println(i, n) } }
如果一个for-range循环中的第二个循环变量既没有被忽略,也没有被舍弃,并且range关键字后跟随一个nil数组指针,则此循环将造成一个恐慌。 在下面这个例子中,前两个循环都将打印出5个下标,但最后一个循环将导致一个恐慌。
package main import "fmt" func main() { var p *[5]int // nil for i, _ := range p { // okay fmt.Println(i) } for i := range p { // okay fmt.Println(i) } for i, n := range p { // panic fmt.Println(i, n) } }
切片克隆
对于目前的标准编译器(1.16版本),最简单的克隆一个切片的方法为:
sClone := append(s[:0:0], s...)
我们也可以使用下面这种实现。但是和上面这个实现相比,它有一个不完美之处:如果源切片s是一个空切片(但是非nil),则结果切片是一个nil切片。
sClone := append([]T(nil), s...)
上面这两种append实现都有一个缺点:它们开辟的内存块常常会比需要的略大一些从而可能造成一点小小的不必要的性能损失。 我们可以使用这两种方法来避免这个缺点:
// 两行make+copy实现: sClone := make([]T, len(s)) copy(sClone, s) // 或者下面的make+append实现。 // 对于目前的官方Go工具链v1.16来说,这种 // 实现比上面的make+copy实现略慢一点。 sClone := append(make([]T, 0, len(s)), s...)
上面这两种make方法都有一个缺点:如果s是一个nil切片,则使用此方法将得到一个非nil切片。 不过,在编程实践中,我们常常并不需要追求克隆的完美性。如果我们确实需要,则需要多写几行:
var sClone []T if s != nil { sClone = make([]T, len(s)) copy(sClone, s) }
在Go官方工具链1.15版本之前,对于一些常见的使用场景,使用append来克隆切片比使用make加copy要高效得多。但是从1.15版本开始,官方标准编译器对make+copy这种方法做了特殊的优化,从而使得此方法总是比使用append来克隆切片高效。
删除一段切片元素
前面已经提到了切片的元素在内存中是连续存储的,相邻元素之间是没有间隙的。所以,当切片的一个元素段被删除时,
- 如果剩余元素的次序必须保持原样,则被删除的元素段后面的每个元素都得前移。
- 如果剩余元素的次序不需要保持原样,则我们可以将尾部的一些元素移到被删除的元素的位置上。
在下面的例子中,假设from(包括)和to(不包括)是两个合法的下标,并且from不大于to。
// 第一种方法(保持剩余元素的次序): s = append(s[:from], s[to:]...) // 第二种方法(保持剩余元素的次序): s = s[:from + copy(s[from:], s[to:])] // 第三种方法(不保持剩余元素的次序): if n := to-from; len(s)-to < n { copy(s[from:to], s[to:]) } else { copy(s[from:to], s[len(s)-n:]) } s = s[:len(s)-(to-from)]
如果切片的元素可能引用着其它值,则我们应该重置因为删除元素而多出来的元素槽位上的元素值,以避免暂时性的内存泄露:
// "len(s)+to-from"是删除操作之前切片s的长度。 temp := s[len(s):len(s)+to-from] for i := range temp { temp[i] = t0 }
前面已经提到了,上面这个for-range循环将被官方标准编译器优化为一个memclr调用。
删除一个元素
删除一个元素是删除一个元素段的特例。在实现上可以简化一些。
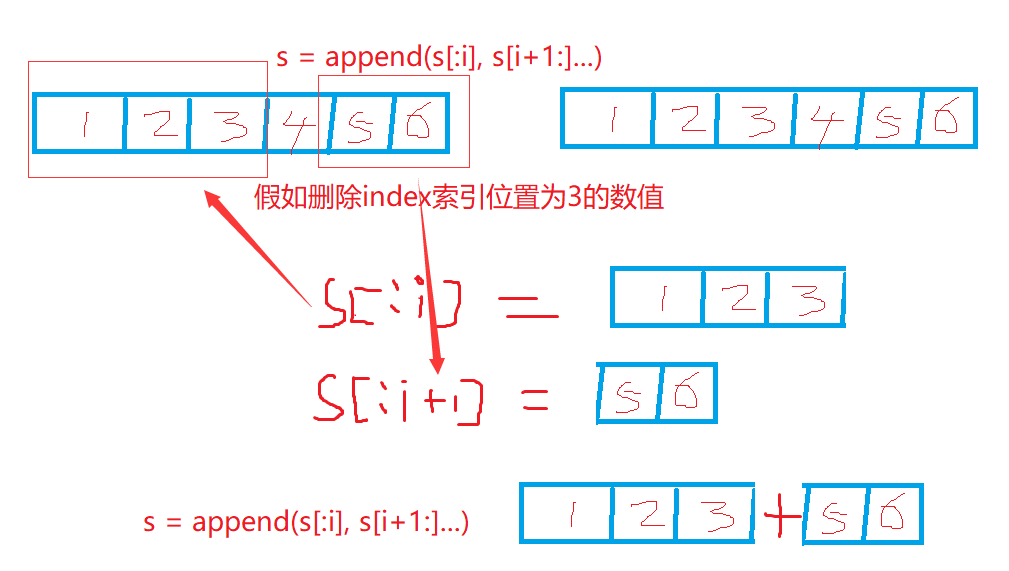
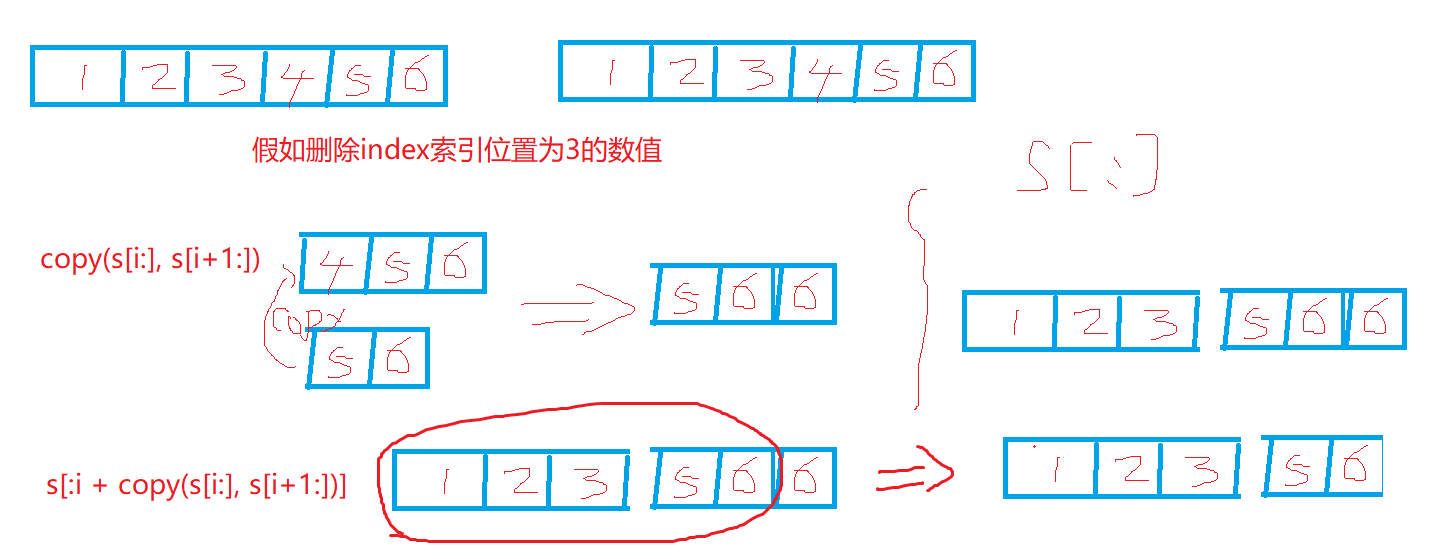
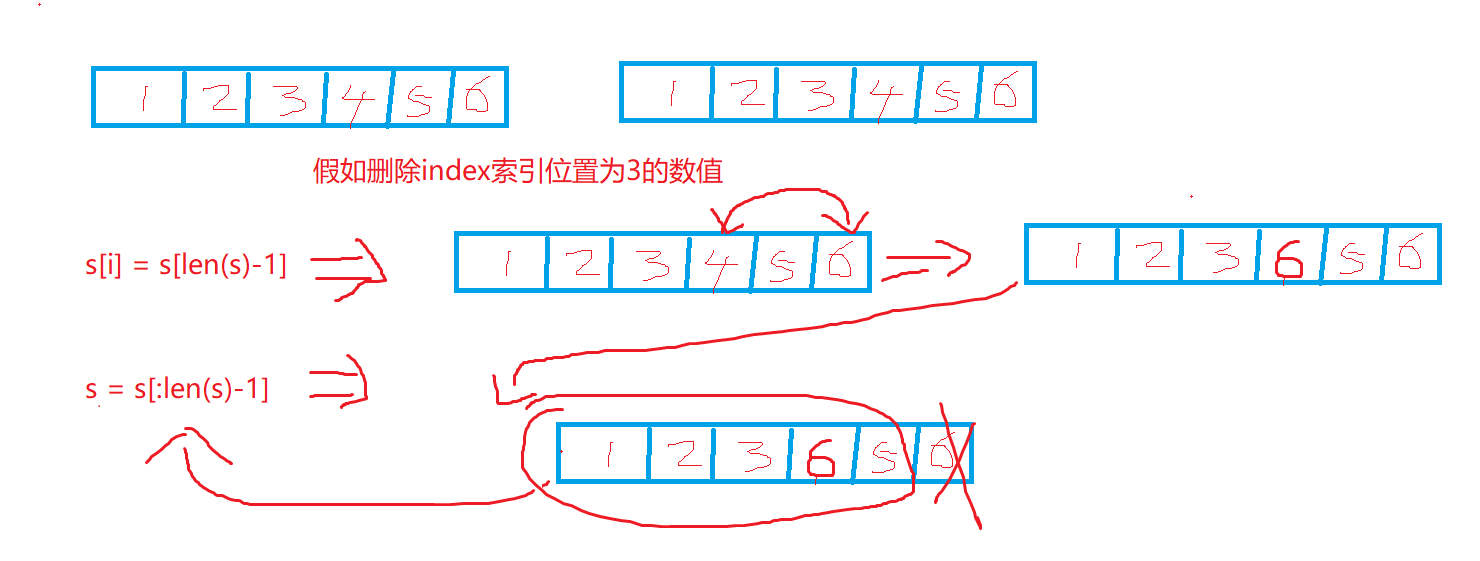
在下面的例子中,假设i将被删除的元素的下标,并且它是一个合法的下标。// 第一种方法(保持剩余元素的次序): s = append(s[:i], s[i+1:]...) // 第二种方法(保持剩余元素的次序): s = s[:i + copy(s[i:], s[i+1:])] // 上面两种方法都需要复制len(s)-i-1个元素。 // 第三种方法(不保持剩余元素的次序): s[i] = s[len(s)-1] s = s[:len(s)-1]
如果切片的元素可能引用着其它值,则我们应该重置刚多出来的元素槽位上的元素值,以避免暂时性的内存泄露:
s[len(s):len(s)+1][0] = t0 // 或者 s[:len(s)+1][len(s)] = t0
// 第一种方法(保持剩余元素的次序):
s = append(s[:i], s[i+1:]...)
// 第二种方法(保持剩余元素的次序):
s = s[:i + copy(s[i:], s[i+1:])]
// 第三种方法(不保持剩余元素的次序):
s[i] = s[len(s)-1] s = s[:len(s)-1]
条件性地删除切片元素
// 假设T是一个小尺寸类型。 func DeleteElements(s []T, keep func(T) bool, clear bool) []T { // result := make([]T, 0, len(s)) result := s[:0] // 无须开辟内存 for _, v := range s { if keep(v) { result = append(result, v) } } if clear { // 避免暂时性的内存泄露。 temp := s[len(result):] for i := range temp { temp[i] = t0 // t0是类型T的零值 } } return result }
注意:如果T是一个大尺寸类型,请慎用T做为参数类型和使用双循环变量for-range代码块遍历元素类型为T的切片。
将一个切片中的所有元素插入到另一个切片中
i是一个合法的下标并且切片elements中的元素将被插入到另一个切片s中。// 第一种方法:单行实现。 s = append(s[:i], append(elements, s[i:]...)...) // 上面这种单行实现把s[i:]中的元素复制了两次,并且它可能 // 最多导致两次内存开辟(最少一次)。 // 下面这种繁琐的实现只把s[i:]中的元素复制了一次,并且 // 它最多只会导致一次内存开辟(最少零次)。 // 但是,在当前的官方标准编译器实现中(1.16版本),此 // 繁琐实现中的make调用将会把所有刚开辟出来的元素清零。 // 这其实是没有必要的。所以此繁琐实现并非总是比上面的 // 单行实现效率更高。事实上,它仅在处理小切片时更高效。 if cap(s) >= len(s) + len(elements) { s = s[:len(s)+len(elements)] copy(s[i+len(elements):], s[i:]) copy(s[i:], elements) } else { x := make([]T, 0, len(elements)+len(s)) x = append(x, s[:i]...) x = append(x, elements...) x = append(x, s[i:]...) s = x } // Push(插入到结尾)。 s = append(s, elements...) // Unshift(插入到开头)。 s = append(elements, s...)
插入若干独立的元素
插入若干独立的元素和插入一个切片中的所有元素类似。 我们可以使用切片组合字面量构建一个临时切片,然后使用上面的方法插入这些元素。
特殊的插入和删除:前推/后推,前弹出/后弹出
e并且切片s拥有至少一个元素。// 前弹出(pop front,又称shift) s, e = s[1:], s[0] // 后弹出(pop back) s, e = s[:len(s)-1], s[len(s)-1] // 前推(push front) s = append([]T{e}, s...) // 后推(push back) s = append(s, e)
请注意:使用append函数来插入元素常常是比较低效的,因为插入点后的所有元素都要向后挪,并且当空余容量不足时还需要开辟一个更大的内存空间来容纳插入完成后所有的元素。 对于元素个数不多的切片来说,这些可能并不是严重的问题;但是在元素个数很多的切片上进行如上的插入操作常常是耗时的。所以如果元素个数很多,最好使用链表来实现元素插入操作。
本文来自博客园,作者:孙龙-程序员,转载请注明原文链接:https://www.cnblogs.com/sunlong88/p/14177131.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号