OB集群问题排查(一)之事务异常中断回滚
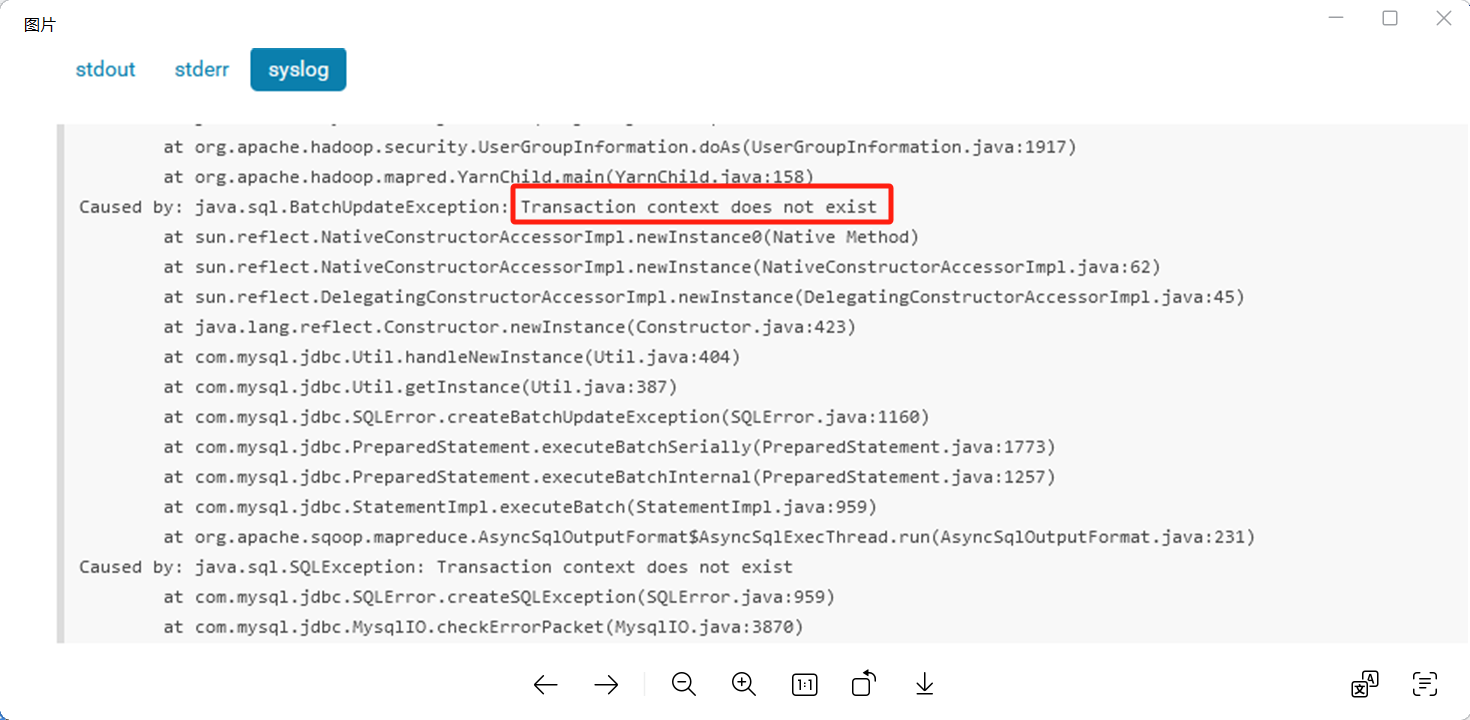
有研发反馈程序有异常事务回滚了,报错如下:
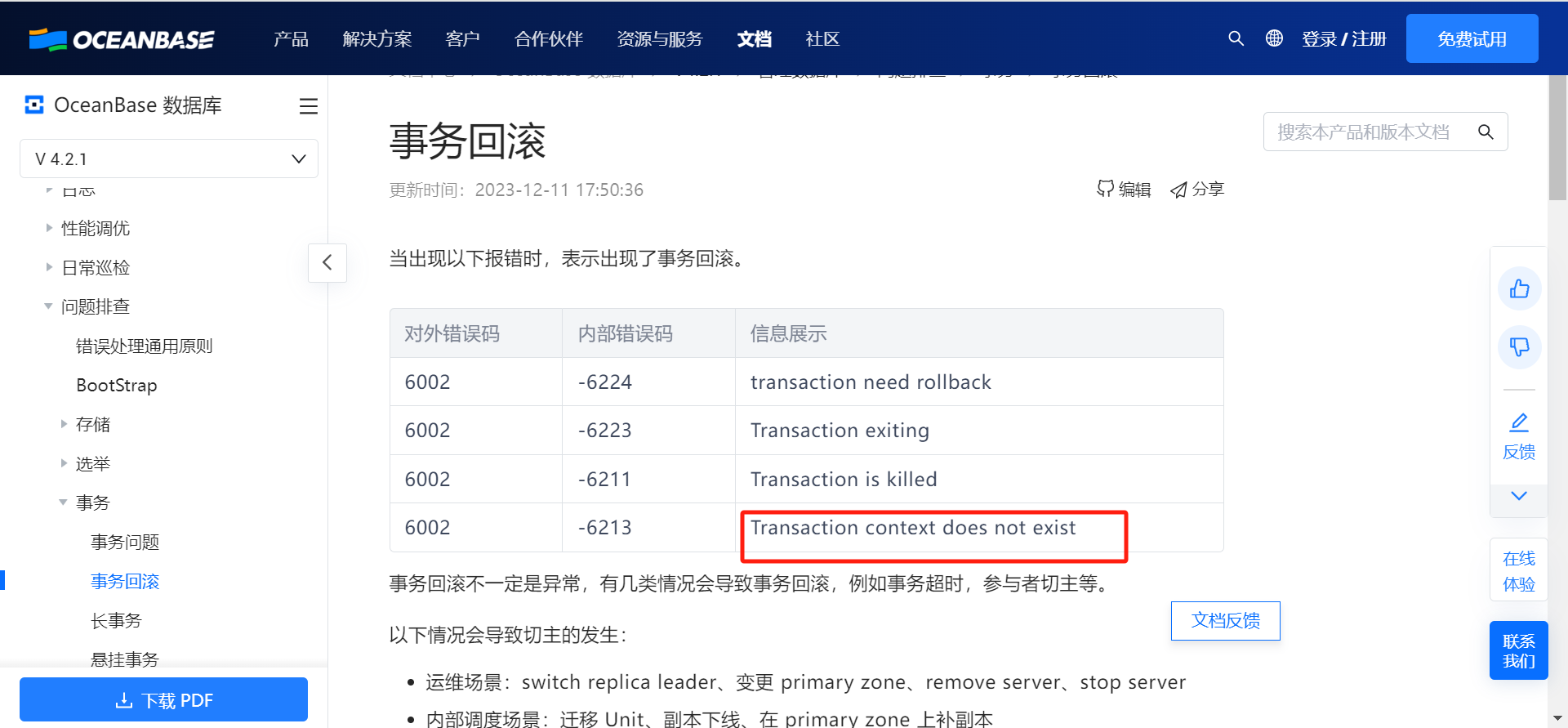
咋一看到,一头雾水,查看官网得知这是由于异常切主导致的事务回滚,如下图:
知道了是异常切主,接下来就是寻找为何会异常切主,以下是排查步骤:
首先我查看obproxy日志,在日志中搜索Transaction context does not exist 和 错误码 -6213 关键字,但是一无所获,然后我又在observer中搜索该关键字,依然是没查到,猜测该报错可能是返回给前端看的,日志中并不会记载。然后询问了研发报错的时间点,通过时间点找到对应的observer日志,搜索了ERROR关键字,发现了如下报错:
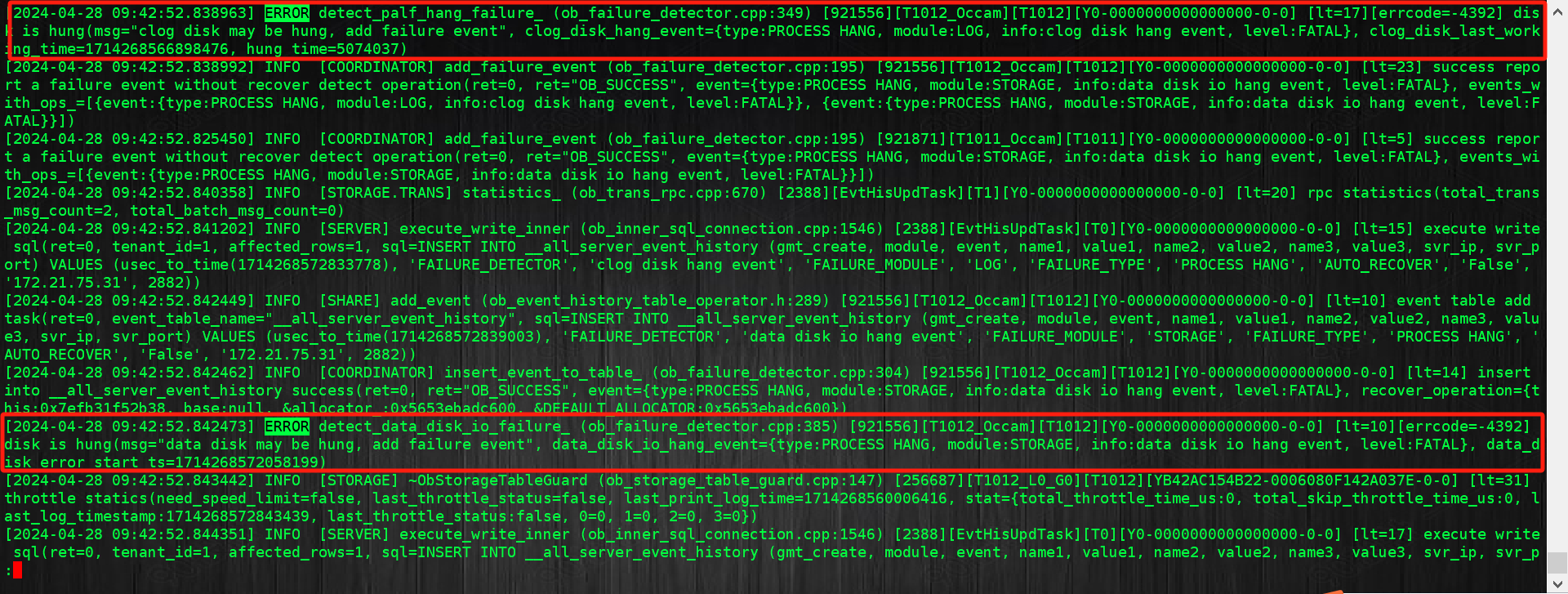
通过日志信息可以清楚的看到是磁盘hang住了,故而引起异常切主,那磁盘hang住为什么会引发异常切主呢?
原来OceanBase 数据库的 IO Manager 会通过探测线程尝试探测数据盘状态,如果超过data_storage_warning_tolerance_time(默认5秒)配置项指定的时间,探测发现这台机器的数据盘状态仍然未恢复正常,探测线程会将该数据盘状态设置为 WARNING,然后触发切主等事件以正常服务业务请求。
通过监控发现此时的磁盘等待时间确实超过了5秒,见下图:
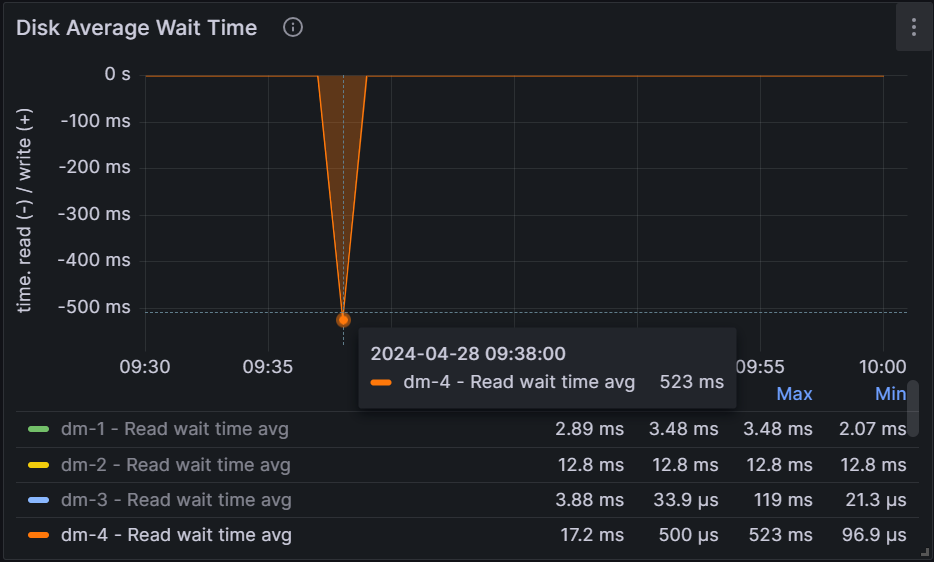
至此,该问题已找到原因,然后把data_storage_warning_tolerance_time从5秒调到了10秒。
总结:
此次排查过程中,排查思路应该是没问题的,先查看obproxy日志,通过obproxy日志找到异常切主的数据副本所在的机器ip,然后再到该机器上查找observer日志判断异常切主的原因。但是排查中却屡屡碰壁,对OB问题排查的过程还是不太熟悉啊,有待进一步加强。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号