第三次作业 孙吉晨、李少楠、张先锋、张书桓
一、团队组成
- 名称:虎扑观察室
- 组员概况:
李少楠:组长
性格:积极负责
擅长:后台程序开发、系统设计、有较强解决bug问题的能力
希望的软工角色:开发者
孙吉晨:组员
性格:务实实际
擅长:技术编程、对不同语言类编程均有了解并能熟练运用一到两种
希望的软工角色:项目开发
张书桓:
性格:活泼开朗
擅长:与人交流,对实际问题有较强的分析能力
希望的软工角色:项目分析
张先锋:
性格:心思细腻
擅长:文本撰写、资料查询
希望的软工角色:文本编辑
二、项目计划
- 项目计划概述:
这次项目中采用的是配置scrapy框架的方法来生成网络爬虫,生成网络爬虫后,执行以下操作:
(1)爬取帖子,获取作者,发帖时间,帖子浏览数,回帖数等信息存到MySQL数据库中;
(2)爬取帖子内容,获取回帖的数据并插入到MySQL数据库中。
2.需求分析
我们的团队项目名称叫做“虎扑观察室”,其用户群体主要是广大的NBA篮球板块的虎扑Jrs(用户),旨在解决他们希望获取喜爱的球队、球星当前热度状态,却苦于没有时间水贴;在虎扑论坛及球队专区上发帖时,因为没有牢靠的数据支撑而不能被其他Jrs所信服
3.团队分工:
李少楠与孙吉晨同学负责scrapy爬虫框架的配置,其中孙吉晨主要负责编程工作,李少楠主要负责检测程序运行是否正常,张先锋和张书恒负责资料查询,博客撰写等
4.项目计划安排:
第一周 (2019.11.14-2019.11.20):了解python的爬虫框架,配置python3.4环境,进行爬虫技术学习
第二周(2010.11.21-2019.11.27):开发项目
第三周(2019.1.128-2019.12.04):完善项目,修复bug,撰写博客
5.实际计划执行:
由于组员较少,且两位主要编程人员课程安排实在太多,所以预期计划未能正常进行,实际计划安排如下:
2019.11.24 10:00 – 11.26 12:30 8 hours
配置python 3.4环境,安装PyCharm,阅读中文文档学习python基础语法;
2019.11.27 15:00 – 11.28 17:00 6 hours
学习scrapy网课,配置scrapy环境,熟悉scrapy命令;
2019.11.29 19:00 – 22:30 3.5 hours
阅读scrapy中文文档,实现第一个爬虫项目;
2019.11.30 09:00 – 10:30 1.5 hours
利用google源码查看功能,了解虎扑网页结构
2019.11.30 19:00 – 22:30 3.5 hours
利用Google源码查看功能,结合HTML 教程,对照scrapy视频网课,初步爬取虎扑网页信息;
20191201 10:00 – 12:00 14:30 – 16:30 4 hours
需要数据库来存scrapy爬取的信息,安装、配置MySQL;
6.功能列表:
(1)分析帖子内容及回复的数据库得出在湿乎乎的话题论坛上前十页浏览量最多和回复数最多的前五贴子,以链接的形式表现出来,方便用户进行浏览。
(2)前十页内湿乎乎论坛上的帖子中有关该球队(或球星)的关键词云图;
(3)在球队专区(主要用户为该球队粉丝)该球队、球星前十页的“状态词”云图;
(4)论坛前十页内与该球队(或球星)同时出现次数最多的其他球队(或球星),方便了解近期的主要竞争关系或者伙伴关系;(未完成)
(5)论坛中热度前十名的帖子的作者名;
三、开发过程
1.团队的模式
主治医师模式
- 过程模型的选择
瀑布模型
- 技术方案
开发语言:python
爬虫框架:scrapy
数据库:Mysql、hupu
四、工作进展
1.累计工作完成情况饼状图
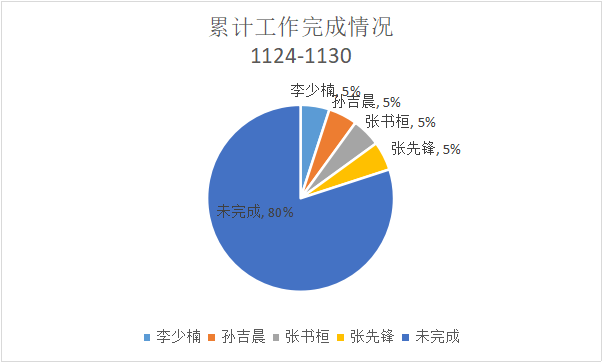
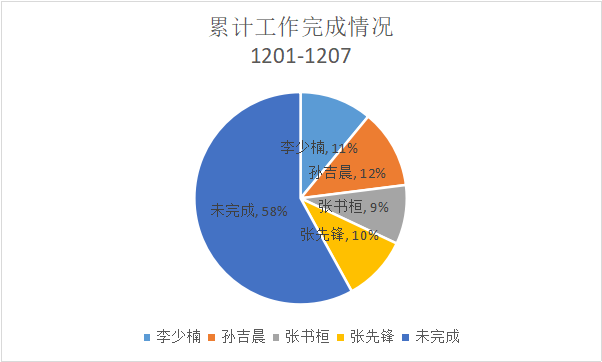
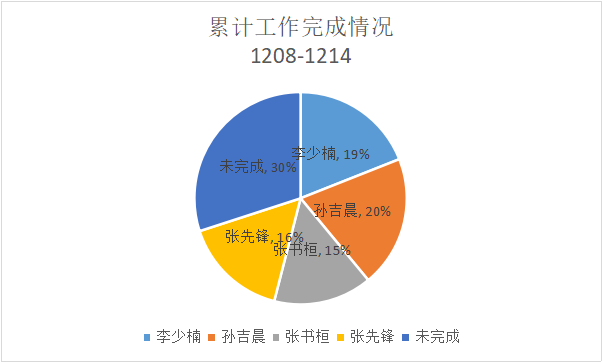
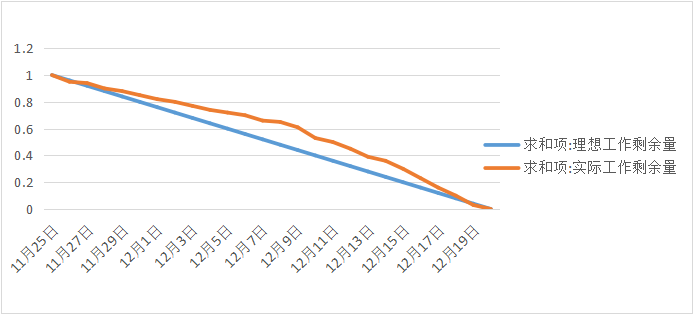
2.任务总量变换曲线
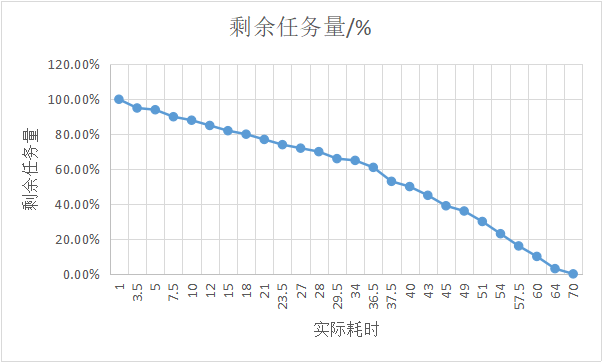
3.燃尽图
五、数据库中表的结构

六、程序运行展示
本项目成果展示采用录屏的方式,百度云链接:复制这段内容后打开百度网盘手机App,操作更方便哦 链接:https://pan.baidu.com/s/1MQ7sRFzCrLicpSPXHLFO4A 提取码:91a1
七、项目技术小结
之所以选取scrapy进行爬虫的配置,是因为scrapy难度较小,利于新手开发网络爬虫,另外网络有很多成熟的scrapy项目源码可以进行借鉴与参考。
爬取的数据以表的形式存储与MySQL数据库中,选取数据库作为存储方式,可以通过命令行进入MySQL环境,并输入相应命令就可以使相应列表的相应元素按指定顺序进行排列和输出,不需要在程序之中增加排序函数就可以达到选取最高热度的帖子的目的。
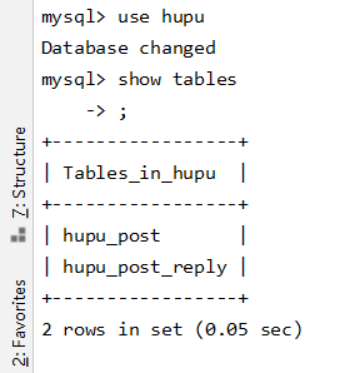
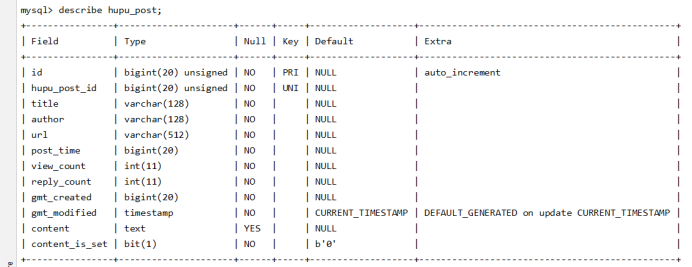
对帖子内容作者的选取,首先进入MySQL环境之中,利用use hupu;命令选用hupu数据库,之后用show tables;命令展示hupu数据库中所有表,执行完上述命令后显示hupu数据库中存在两个表这两个表分别为,hupu_post和hupu_post_reply,随后产看表的结构选取相应内容进行输出或排序,查看表结构的命令为:describe hupu_post;,执行select author from hupu_post order by view count dsac;选取author列中的元素并按照浏览量的大小进行排序,就可以得到浏览量最多的帖子作者的列表。
对帖子内容的选取也是在MySQL数据库环境中,在命令行环境中输入并执行select content from hupu_post into outfile ‘C:\Users\18846\Desktop\hupu_spider-master (1)\hupu_post.txt’命令便可以将数据库中帖子内容输出进相应的txt文件。
对帖子内容关键字的检索以及分词通过jieba库来实现,停用词的设定通过手动设定,排除xpath中的关键字例如<div>这样的英文字符以及数字,最后将出现频率最高的20个词汇写进txt文档之中,为后期生成词云进行准备。
生成词云选取wordcloud库生成,在生成词云的过程之中遇到的主要问题是,电脑中的字体并不支持中文词云的显示,只好另外下载雅黑字体,调用word cloud库生成词云使只需要调用雅黑字体便可以输出中文的词云。
八、不足之处
效率低,大量时间花费在知识的学习上,相对比上次项目,利用网上资源的能力增强,指定方案上也存在问题,目的不明确,有些目标实现起来难度较大,后期仍需完善。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号