一、Python 运算符
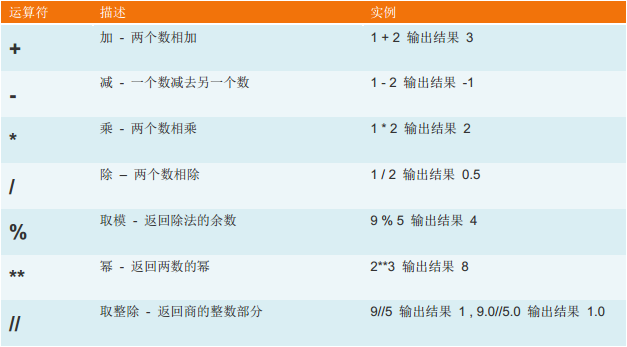
1、算术运算:
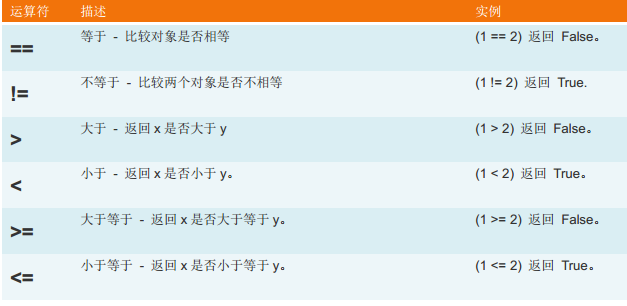
2、比较运算:
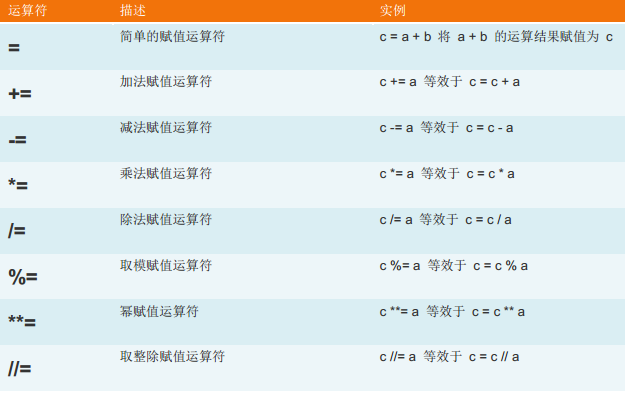
3、赋值运算:
4、逻辑运算:

5、成员运算:

二、基本数据类型
1、数字整型
int(整型)
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807


1 #返回表示该数字的时占用的最少位数 2 >>> (951).bit_length() 3 10 4 5 #返回绝对值 6 >>> (95).__abs__() 7 95 8 >>> (-95).__abs__() 9 95 10 11 #用来区分数字和字符串的 12 >>> (95).__add__(1) 13 96 14 >>> (95).__add__("1") 15 NotImplemented 16 17 #判断一个整数对象是否为0,如果为0,则返回False,如果不为0,则返回True 18 >>> (95).__bool__() 19 True 20 >>> (0).__bool__() 21 False 22 23 #判断两个值是否相等 24 >>> (95).__eq__(95) 25 True 26 >>> (95).__eq__(9) 27 False 28 29 #判断是否不等于 30 >>> (95).__ne__(9) 31 True 32 >>> (95).__ne__(95) 33 False 34 35 #判断是否大于等于 36 >>> (95).__ge__(9) 37 True 38 >>> (95).__ge__(99) 39 False 40 41 #判断是否大于 42 >>> (95).__gt__(9) 43 True 44 >>> (95).__gt__(99) 45 False 46 47 #判断是否小于等于 48 >>> (95).__le__(99) 49 True 50 >>> (95).__le__(9) 51 False 52 53 #判断是否小于 54 >>> (95).__lt__(9) 55 False 56 >>> (95).__lt__(99) 57 True 58 59 #加法运算 60 >>> (95).__add__(5) 61 100 62 63 #减法运算 64 >>> (95).__sub__(5) 65 90 66 67 #乘法运算 68 >>> (95).__mul__(10) 69 950 70 71 #除法运算 72 >>> (95).__truediv__(5) 73 19.0 74 75 #取模运算 76 >>> (95).__mod__(9) 77 5 78 79 #幂运算 80 >>> (2).__pow__(10) 81 1024 82 83 #整除,保留结果的整数部分 84 >>> (95).__floordiv__(9) 85 >>> 86 87 #转换为整型 88 >>> (9.5).__int__() 89 9 90 91 #返回一个对象的整数部分 92 >>> (9.5).__trunc__() 93 9 94 95 #将正数变为负数,将负数变为正数 96 >>> (95).__neg__() 97 -95 98 >>> (-95).__neg__() 99 95 100 101 #将一个正数转为字符串 102 >>> a = 95 103 >>> a = a.__str__() 104 >>> print(type(a)) 105 <class 'str'> 106 107 #将一个整数转换成浮点型 108 >>> (95).__float__() 109 95.0 110 111 #转换对象的类型 112 >>> (95).__format__('f') 113 '95.000000' 114 >>> (95).__format__('b') 115 '1011111' 116 117 #在内存中占多少个字节 118 >>> a = 95 119 >>> a.__sizeof__() 120 28
1 class int(object): 2 """ 3 int(x=0) -> integer 4 int(x, base=10) -> integer 5 6 Convert a number or string to an integer, or return 0 if no arguments 7 are given. If x is a number, return x.__int__(). For floating point 8 numbers, this truncates towards zero. 9 10 If x is not a number or if base is given, then x must be a string, 11 bytes, or bytearray instance representing an integer literal in the 12 given base. The literal can be preceded by '+' or '-' and be surrounded 13 by whitespace. The base defaults to 10. Valid bases are 0 and 2-36. 14 Base 0 means to interpret the base from the string as an integer literal. 15 >>> int('0b100', base=0) 16 """ 17 def bit_length(self): # real signature unknown; restored from __doc__ 18 """ 19 int.bit_length() -> int 20 21 Number of bits necessary to represent self in binary. 22 """ 23 """ 24 表示该数字返回时占用的最少位数 25 26 >>> (951).bit_length() 27 10 28 """ 29 return 0 30 31 def conjugate(self, *args, **kwargs): # real signature unknown 32 """ Returns self, the complex conjugate of any int.""" 33 34 """ 35 返回该复数的共轭复数 36 37 #返回复数的共轭复数 38 >>> (95 + 11j).conjugate() 39 (95-11j) 40 #返回复数的实数部分 41 >>> (95 + 11j).real 42 95.0 43 #返回复数的虚数部分 44 >>> (95 + 11j).imag 45 11.0 46 """ 47 pass 48 49 @classmethod # known case 50 def from_bytes(cls, bytes, byteorder, *args, **kwargs): # real signature unknown; NOTE: unreliably restored from __doc__ 51 """ 52 int.from_bytes(bytes, byteorder, *, signed=False) -> int 53 54 Return the integer represented by the given array of bytes. 55 56 The bytes argument must be a bytes-like object (e.g. bytes or bytearray). 57 58 The byteorder argument determines the byte order used to represent the 59 integer. If byteorder is 'big', the most significant byte is at the 60 beginning of the byte array. If byteorder is 'little', the most 61 significant byte is at the end of the byte array. To request the native 62 byte order of the host system, use `sys.byteorder' as the byte order value. 63 64 The signed keyword-only argument indicates whether two's complement is 65 used to represent the integer. 66 """ 67 """ 68 这个方法是在Python3.2的时候加入的,python官方给出了下面几个例子: 69 >>> int.from_bytes(b'\x00\x10', byteorder='big') 70 >>> int.from_bytes(b'\x00\x10', byteorder='little') 71 >>> int.from_bytes(b'\xfc\x00', byteorder='big', signed=True) 72 -1024 73 >>> int.from_bytes(b'\xfc\x00', byteorder='big', signed=False) 74 >>> int.from_bytes([255, 0, 0], byteorder='big') 75 """ 76 pass 77 78 def to_bytes(self, length, byteorder, *args, **kwargs): # real signature unknown; NOTE: unreliably restored from __doc__ 79 """ 80 int.to_bytes(length, byteorder, *, signed=False) -> bytes 81 82 Return an array of bytes representing an integer. 83 84 The integer is represented using length bytes. An OverflowError is 85 raised if the integer is not representable with the given number of 86 bytes. 87 88 The byteorder argument determines the byte order used to represent the 89 integer. If byteorder is 'big', the most significant byte is at the 90 beginning of the byte array. If byteorder is 'little', the most 91 significant byte is at the end of the byte array. To request the native 92 byte order of the host system, use `sys.byteorder' as the byte order value. 93 94 The signed keyword-only argument determines whether two's complement is 95 used to represent the integer. If signed is False and a negative integer 96 is given, an OverflowError is raised. 97 """ 98 """ 99 python官方给出了下面几个例子: 100 >>> (1024).to_bytes(2, byteorder='big') 101 b'\x04\x00' 102 >>> (1024).to_bytes(10, byteorder='big') 103 b'\x00\x00\x00\x00\x00\x00\x00\x00\x04\x00' 104 >>> (-1024).to_bytes(10, byteorder='big', signed=True) 105 b'\xff\xff\xff\xff\xff\xff\xff\xff\xfc\x00' 106 >>> x = 1000 107 >>> x.to_bytes((x.bit_length() // 8) + 1, byteorder='little') 108 b'\xe8\x03' 109 """ 110 pass 111 112 def __abs__(self, *args, **kwargs): # real signature unknown 113 """ abs(self)""" 114 115 """ 116 返回一个绝对值 117 118 >>> (95).__abs__() 119 -95 120 >>> (-95).__abs__() 121 95 122 """ 123 pass 124 125 126 def __add__(self, *args, **kwargs): # real signature unknown 127 """ Return self+value.""" 128 129 """ 130 加法,也可区分数字和字符串 131 132 >>> (95).__add__(1) 133 96 134 >>> (95).__add__("1") 135 NotImplemented 136 >>> 137 """ 138 pass 139 140 def __and__(self, *args, **kwargs): # real signature unknown 141 """ Return self&value.""" 142 pass 143 144 def __bool__(self, *args, **kwargs): # real signature unknown 145 """ self != 0 """ 146 147 """ 148 判断一个整数对象是否为0,如果为0,则返回False,如果不为0,则返回True 149 150 >>> (95).__bool__() 151 True 152 >>> (0).__bool__() 153 False 154 """ 155 pass 156 157 def __ceil__(self, *args, **kwargs): # real signature unknown 158 """ Ceiling of an Integral returns itself. """ 159 pass 160 161 def __divmod__(self, *args, **kwargs): # real signature unknown 162 """ Return divmod(self, value). """ 163 """ 164 返回一个元组,第一个元素为商,第二个元素为余数 165 166 >>> (9).__divmod__(5) 167 (1, 4) 168 """ 169 pass 170 171 def __eq__(self, *args, **kwargs): # real signature unknown 172 """ Return self==value. """ 173 """ 174 判断两个值是否相等 175 176 >>> (95).__eq__(95) 177 True 178 >>> (95).__eq__(9) 179 False 180 """ 181 pass 182 183 def __float__(self, *args, **kwargs): # real signature unknown 184 """ float(self) """ 185 """ 186 将一个整数转换成浮点型 187 188 >>> (95).__float__() 189 95.0 190 """ 191 pass 192 193 def __floordiv__(self, *args, **kwargs): # real signature unknown 194 """ Return self//value. """ 195 """ 196 整除,保留结果的整数部分 197 198 >>> (95).__floordiv__(9) 199 10 200 """ 201 pass 202 203 def __floor__(self, *args, **kwargs): # real signature unknown 204 """ Flooring an Integral returns itself. """ 205 """ 206 返回本身 207 208 >>> (95).__floor__() 209 95 210 """ 211 pass 212 213 def __format__(self, *args, **kwargs): # real signature unknown 214 """ 215 转换对象的类型 216 217 >>> (95).__format__('f') 218 '95.000000' 219 >>> (95).__format__('b') 220 '1011111' 221 """ 222 pass 223 224 225 def __getattribute__(self, *args, **kwargs): # real signature unknown 226 """ Return getattr(self, name). """ 227 """ 228 判断这个类中是否包含这个属性,如果包含则打印出值,如果不包含,就报错了 229 230 >>> (95).__getattribute__('__abs__') 231 <method-wrapper '__abs__' of int object at 0x9f93c0> 232 >>> (95).__getattribute__('__aaa__') 233 Traceback (most recent call last): 234 File "<stdin>", line 1, in <module> 235 AttributeError: 'int' object has no attribute '__aaa__' 236 """ 237 pass 238 239 def __getnewargs__(self, *args, **kwargs): # real signature unknown 240 pass 241 242 def __ge__(self, *args, **kwargs): # real signature unknown 243 """ Return self>=value. """ 244 """ 245 判断是否大于等于 246 247 >>> (95).__ge__(9) 248 True 249 >>> (95).__ge__(99) 250 False 251 """ 252 pass 253 254 def __gt__(self, *args, **kwargs): # real signature unknown 255 """ Return self>value. """ 256 """ 257 判断是否大于 258 259 >>> (95).__gt__(9) 260 True 261 >>> (95).__gt__(99) 262 False 263 """ 264 pass 265 266 def __hash__(self, *args, **kwargs): # real signature unknown 267 """ Return hash(self). """ 268 """ 269 计算哈希值,整数返回本身 270 271 >>> (95).__hash__() 272 95 273 >>> (95.95).__hash__() 274 2190550858753015903 275 """ 276 pass 277 278 def __index__(self, *args, **kwargs): # real signature unknown 279 """ Return self converted to an integer, if self is suitable for use as an index into a list. """ 280 pass 281 282 def __init__(self, x, base=10): # known special case of int.__init__ 283 """ 284 这个是一个类的初始化方法,当int类被实例化的时候,这个方法默认就会被执行 285 """ 286 """ 287 int(x=0) -> integer 288 int(x, base=10) -> integer 289 290 Convert a number or string to an integer, or return 0 if no arguments 291 are given. If x is a number, return x.__int__(). For floating point 292 numbers, this truncates towards zero. 293 294 If x is not a number or if base is given, then x must be a string, 295 bytes, or bytearray instance representing an integer literal in the 296 given base. The literal can be preceded by '+' or '-' and be surrounded 297 by whitespace. The base defaults to 10. Valid bases are 0 and 2-36. 298 Base 0 means to interpret the base from the string as an integer literal. 299 >>> int('0b100', base=0) 300 # (copied from class doc) 301 """ 302 pass 303 304 def __int__(self, *args, **kwargs): # real signature unknown 305 """ int(self) """ 306 """ 307 转换为整型 308 309 >>> (9.5).__int__() 310 9 311 """ 312 pass 313 314 315 def __invert__(self, *args, **kwargs): # real signature unknown 316 """ ~self """ 317 318 pass 319 320 def __le__(self, *args, **kwargs): # real signature unknown 321 """ Return self<=value. """ 322 """ 323 判断是否小于等于 324 325 >>> (95).__le__(99) 326 True 327 >>> (95).__le__(9) 328 False 329 """ 330 pass 331 332 def __lshift__(self, *args, **kwargs): # real signature unknown 333 """ Return self<<value. """ 334 """ 335 用于二进制位移,这个是向左移动 336 337 >>> bin(95) 338 '0b1011111' 339 >>> a = (95).__lshift__(2) 340 >>> bin(a) 341 '0b101111100' 342 >>> 343 """ 344 pass 345 346 def __lt__(self, *args, **kwargs): # real signature unknown 347 """ Return self<value. """ 348 """ 349 判断是否小于 350 351 >>> (95).__lt__(9) 352 False 353 >>> (95).__lt__(99) 354 True 355 """ 356 pass 357 358 def __mod__(self, *args, **kwargs): # real signature unknown 359 """ Return self%value. """ 360 """ 361 取模 % 362 363 >>> (95).__mod__(9) 364 """ 365 pass 366 367 def __mul__(self, *args, **kwargs): # real signature unknown 368 """ Return self*value. """ 369 """ 370 乘法 * 371 372 >>> (95).__mul__(10) 373 """ 374 pass 375 376 def __neg__(self, *args, **kwargs): # real signature unknown 377 """ -self """ 378 """ 379 将正数变为负数,将负数变为正数 380 381 >>> (95).__neg__() 382 -95 383 >>> (-95).__neg__() 384 95 385 """ 386 pass 387 388 @staticmethod # known case of __new__ 389 def __new__(*args, **kwargs): # real signature unknown 390 """ Create and return a new object. See help(type) for accurate signature. """ 391 pass 392 393 def __ne__(self, *args, **kwargs): # real signature unknown 394 """ Return self!=value. """ 395 """ 396 不等于 397 398 >>> (95).__ne__(9) 399 True 400 >>> (95).__ne__(95) 401 False 402 """ 403 pass 404 405 def __or__(self, *args, **kwargs): # real signature unknown 406 """ Return self|value. """ 407 """ 408 二进制或的关系,只要有一个为真,就为真 409 410 >>> a = 4 411 >>> b = 0 412 >>> a.__or__(b) # a --> 00000100 b --> 00000000 413 >>> b = 1 # b --> 00000001 414 >>> a.__or__(b) 415 """ 416 pass 417 418 def __pos__(self, *args, **kwargs): # real signature unknown 419 """ +self """ 420 pass 421 422 def __pow__(self, *args, **kwargs): # real signature unknown 423 """ Return pow(self, value, mod). """ 424 """ 425 幂 426 427 >>> (2).__pow__(10) 428 1024 429 """ 430 pass 431 432 def __radd__(self, *args, **kwargs): # real signatre unknown 433 """ Return value+self. """ 434 """ 435 加法,将value放在前面 436 437 >>> a.__radd__(b) # 相当于 b+a 438 """ 439 pass 440 441 def __rand__(self, *args, **kwargs): # real signature unknown 442 """ Return value&self. """ 443 """ 444 二进制与的关系,两个都为真,才为真,有一个为假,就为假 445 """ 446 pass 447 448 def __rdivmod__(self, *args, **kwargs): # real signature unknown 449 """ Return divmod(value, self). """ 450 pass 451 452 def __repr__(self, *args, **kwargs): # real signature unknown 453 """ Return repr(self). """ 454 pass 455 456 def __rfloordiv__(self, *args, **kwargs): # real signature unknown 457 """ Return value//self. """ 458 pass 459 460 def __rlshift__(self, *args, **kwargs): # real signature unknown 461 """ Return value<<self. """ 462 pass 463 464 def __rmod__(self, *args, **kwargs): # real signature unknown 465 """ Return value%self. """ 466 pass 467 468 def __rmul__(self, *args, **kwargs): # real signature unknown 469 """ Return value*self. """ 470 pass 471 472 def __ror__(self, *args, **kwargs): # real signature unknown 473 """ Return value|self. """ 474 pass 475 476 def __round__(self, *args, **kwargs): # real signature unknown 477 """ 478 Rounding an Integral returns itself. 479 Rounding with an ndigits argument also returns an integer. 480 """ 481 pass 482 483 def __rpow__(self, *args, **kwargs): # real signature unknown 484 """ Return pow(value, self, mod). """ 485 pass 486 487 def __rrshift__(self, *args, **kwargs): # real signature unknown 488 """ Return value>>self. """ 489 pass 490 491 def __rshift__(self, *args, **kwargs): # real signature unknown 492 """ Return self>>value. """ 493 pass 494 495 def __rsub__(self, *args, **kwargs): # real signature unknown 496 """ Return value-self. """ 497 pass 498 499 def __rtruediv__(self, *args, **kwargs): # real signature unknown 500 """ Return value/self. """ 501 pass 502 503 def __rxor__(self, *args, **kwargs): # real signature unknown 504 """ Return value^self. """ 505 pass 506 507 def __sizeof__(self, *args, **kwargs): # real signature unknown 508 """ Returns size in memory, in bytes """ 509 """ 510 在内存中占多少个字节 511 512 >>> a = 95 513 >>> a.__sizeof__() 514 28 515 """ 516 pass 517 518 def __str__(self, *args, **kwargs): # real signature unknown 519 """ Return str(self). """ 520 """ 521 将一个正数转为字符串 522 523 >>> a = 95 524 >>> a = a.__str__() 525 >>> print(type(a)) 526 <class 'str'> 527 """ 528 pass 529 530 def __sub__(self, *args, **kwargs): # real signature unknown 531 """ Return self-value. """ 532 """ 533 减法运算 534 535 >>> (95).__sub__(5) 536 90 537 """ 538 pass 539 540 def __truediv__(self, *args, **kwargs): # real signature unknown 541 """ Return self/value. """ 542 """ 543 除法运算 544 545 >>> (95).__truediv__(5) 546 19.0 547 """ 548 pass 549 550 def __trunc__(self, *args, **kwargs): # real signature unknown 551 """ Truncating an Integral returns itself. """ 552 """ 553 返回一个对象的整数部分 554 555 >>> (95.95).__trunc__() 556 95 557 """ 558 pass 559 def __xor__(self, *args, **kwargs): # real signature unknown 560 """ Return self^value. """ 561 """ 562 将对象与值进行二进制的或运算,一个为真,就为真 563 564 >>> a = 4 565 >>> b = 1 566 >>> a.__xor__(b) 567 >>> c = 0 568 >>> a.__xor__(c) 569 """ 570 571 pass 572 573 denominator = property(lambda self: object(), lambda self, v: None, lambda self: None) # default 574 """ 分母 = 1 """ 575 """the denominator of a rational number in lowest terms""" 576 577 imag = property(lambda self: object(), lambda self, v: None, lambda self: None) # default 578 """ 虚数 """ 579 """the imaginary part of a complex number""" 580 581 numerator = property(lambda self: object(), lambda self, v: None, lambda self: None) # default 582 """ 分子 = 数字大小 """ 583 """the numerator of a rational number in lowest terms""" 584 585 real = property(lambda self: object(), lambda self, v: None, lambda self: None) # default 586 """ 实属 """ 587 """the real part of a complex number"""
2、字符串
"hello world"
str(字符串类型)
万恶的字符串拼接:
字符串一旦创建不可修改,一旦修改或者拼接,都会重新生成字符串
1 #切片 2 3 #索引,从0号索引开始,获取字符串中的某一个字符 4 string="allen中文" 5 print(string[0]) 6 7 #索引范围 8 print(string[0:2]) 9 10 #获取最后一个索引位置 11 print(string[-1]) 12 13 print(string[0:-1]) 14 #输出: alle 15 16 #len()获取字符串长度 17 len(string) 18 print("_".join(string)) 19 20 #列子 21 index=0 22 while index<len(string): 23 print(string[index]) 24 index+=1 25 26 #字符串替换 27 new_string=string.replace('en','EN') 28 print(new_string) 29 #输出: allEN中文
1 #查看类型 2 age=18 3 my_name="obama" 4 5 print(type(age)) 6 print(type(my_name)) 7 #输出 : 8 # <class 'int'> 9 # <class 'str'> 10 11 12 #将字符串转换为整型 13 number="123" 14 num= int(number) 15 print(type(num),num) 16 17 #输出: <class 'int'> 123 18 19 20 #首字母转换为大写,其他字母都是小写 21 name ='my name is AllEn' 22 print(name.capitalize()) 23 # 输出:My name is allen 24 25 #所有字符转换为小写,比lower()更牛逼 26 print(name.casefold()) 27 # 输出:my name is allen 28 29 #统计m出现次数 30 print(name.count("m")) 31 # 输出:2 32 33 #把name变量放在50个字符中间,设置宽度并把内容居中 34 print(name.center(50,'-')) 35 # 输出:-----------------my name is AllEn----------------- 36 37 #判断一个字符串是否以en结尾 38 print(name.endswith('En')) 39 # 输出:True 40 41 #判断一个字符串是否以my开始 42 print(name.startswith('my')) 43 # 输出:True 44 45 46 #查找子序列name,找到返回其索引,找不到返回-1 47 print(name.find('name')) 48 49 # 输出:3 50 51 #字符串切片 52 print(name[name.find('name'):]) 53 # 输出:name is AllEn 54 55 #format格式化用法1: 将字符串占位符替换为指定的值 56 name_info='my name is {_name} and I am {_age} old' 57 # 58 # 59 print(name_info.format(_name='allen',_age=18)) 60 # 输出:my name is allen and I am 18 old 61 62 #format格式化用法2:根据顺序替换 63 name_info1='my name is {0} and I am {1} old' 64 65 print(name_info1.format('allen',18)) 66 # 输出:my name is allen and I am 18 old 67 68 #format_map 字典用法 69 print(name_info.format_map({'_name':'allen','_age':20})) 70 # 输出:my name is allen and I am 20 old 71 72 #查找索引,如果找不到会报错 73 print(name.index('name')) 74 # 输出:3 75 76 77 #判断是否包含数字和字母 78 print('9aA'.isalnum()) 79 # 输出:True 80 81 #判断是否包含纯英文字符 82 print('abA'.isalpha()) 83 84 # 输出:True 85 86 # 判断是否是整数 87 print('123'.isdigit()) 88 89 # 输出:True 90 91 #判断是否是数字,支持unicode 92 test="二" 93 print(test.isnumeric(),test) 94 # 输出:True 95 96 97 #判断是不是合法的变量名 98 print('1A'.isidentifier()) 99 100 # 输出:False 101 102 #判断是否是小写 103 print('abc'.islower()) 104 # 输出:True 105 106 #判断是否是大写 107 print('33a'.isupper()) 108 # 输出:False 109 110 # 大小写互换 111 print('AllEN'.swapcase()) 112 # 输出:aLLen 113 114 #字符串替换,只替换一次 115 print('AlLeN'.replace('l','L',1)) 116 # 输出:ALLeN 117 118 119 #join连接两个字符串 120 li = ["nick","serven"] 121 a = "".join(li) 122 b = "_".join(li) 123 print(a) 124 print(b) 125 126 #输出:nickserven 127 # nick_serven 128 129 #大写变小写 130 print('ALLen'.lower()) 131 # 输出:allen 132 133 # 小写变大写 134 print('allen'.upper()) 135 # 输出:ALLEN 136 137 138 #去掉左右的空格(包括换行符和制表符) 139 print(' all\ne\tn '.strip()) 140 # 输出:allen 141 142 #去掉左边空行和回车 143 print(' allen '.lstrip()) 144 # 输出:allen 145 146 #去掉右边空行和回车 147 print(' allen '.rstrip()) 148 # 输出: allen 149 150 #找到最右边目标的索引 151 print('allenlaen'.rfind('a')) 152 # 输出:6 153 154 155 #判断是否全部是空格 156 test=" " 157 print(test.isspace()) 158 # 输出:True 159 160 #判断是否是标题(首字母全部是大写) 161 title="Return the highest index in S where substring sub" 162 print(title.istitle(),title) 163 # 输出:False 164 # 转换为首字母全部为大写(转换为标题) 165 print(title.title()) 166 # 输出:Return The Highest Index In S Where Substring Sub 167 168 169 170 #字符串切割 以t切分 t没有了 171 print('allen test'.split('t')) 172 # 输出:['allen ', 'es', ''] 173 174 #字符串切割 以t切分,只分割一次 175 print('allen test'.split('t',1)) 176 # 输出:['allen ', 'est'] 177 178 #只根据换行符分割 179 print("asdsad\nasdsad\nasda".splitlines()) 180 181 #输出:['asdsad', 'asdsad', 'asda'] 182 183 184 #表示长度50 不够右边*号填充 185 print(name.ljust(50,'*')) 186 # 输出:my name is AllEn********************************** 187 188 # 表示长度50 不够左边-号填充 189 print(name.rjust(50,'-')) 190 # 输出:----------------------------------my name is AllEn
1 class str(object): 2 """ 3 str(object='') -> str 4 str(bytes_or_buffer[, encoding[, errors]]) -> str 5 6 Create a new string object from the given object. If encoding or 7 errors is specified, then the object must expose a data buffer 8 that will be decoded using the given encoding and error handler. 9 Otherwise, returns the result of object.__str__() (if defined) 10 or repr(object). 11 encoding defaults to sys.getdefaultencoding(). 12 errors defaults to 'strict'. 13 """ 14 def capitalize(self): # real signature unknown; restored from __doc__ 15 """ 16 S.capitalize() -> str 17 18 Return a capitalized version of S, i.e. make the first character 19 have upper case and the rest lower case. 20 """ 21 return "" 22 23 def casefold(self): # real signature unknown; restored from __doc__ 24 """ 25 S.casefold() -> str 26 27 Return a version of S suitable for caseless comparisons. 28 """ 29 return "" 30 31 def center(self, width, fillchar=None): # real signature unknown; restored from __doc__ 32 """ 33 S.center(width[, fillchar]) -> str 34 35 Return S centered in a string of length width. Padding is 36 done using the specified fill character (default is a space) 37 """ 38 return "" 39 40 def count(self, sub, start=None, end=None): # real signature unknown; restored from __doc__ 41 """ 42 S.count(sub[, start[, end]]) -> int 43 44 Return the number of non-overlapping occurrences of substring sub in 45 string S[start:end]. Optional arguments start and end are 46 interpreted as in slice notation. 47 """ 48 return 0 49 50 def encode(self, encoding='utf-8', errors='strict'): # real signature unknown; restored from __doc__ 51 """ 52 S.encode(encoding='utf-8', errors='strict') -> bytes 53 54 Encode S using the codec registered for encoding. Default encoding 55 is 'utf-8'. errors may be given to set a different error 56 handling scheme. Default is 'strict' meaning that encoding errors raise 57 a UnicodeEncodeError. Other possible values are 'ignore', 'replace' and 58 'xmlcharrefreplace' as well as any other name registered with 59 codecs.register_error that can handle UnicodeEncodeErrors. 60 """ 61 return b"" 62 63 def endswith(self, suffix, start=None, end=None): # real signature unknown; restored from __doc__ 64 """ 65 S.endswith(suffix[, start[, end]]) -> bool 66 67 Return True if S ends with the specified suffix, False otherwise. 68 With optional start, test S beginning at that position. 69 With optional end, stop comparing S at that position. 70 suffix can also be a tuple of strings to try. 71 """ 72 return False 73 74 def expandtabs(self, tabsize=8): # real signature unknown; restored from __doc__ 75 """ 76 S.expandtabs(tabsize=8) -> str 77 78 Return a copy of S where all tab characters are expanded using spaces. 79 If tabsize is not given, a tab size of 8 characters is assumed. 80 """ 81 return "" 82 83 def find(self, sub, start=None, end=None): # real signature unknown; restored from __doc__ 84 """ 85 S.find(sub[, start[, end]]) -> int 86 87 Return the lowest index in S where substring sub is found, 88 such that sub is contained within S[start:end]. Optional 89 arguments start and end are interpreted as in slice notation. 90 91 Return -1 on failure. 92 """ 93 return 0 94 95 def format(self, *args, **kwargs): # known special case of str.format 96 """ 97 S.format(*args, **kwargs) -> str 98 99 Return a formatted version of S, using substitutions from args and kwargs. 100 The substitutions are identified by braces ('{' and '}'). 101 """ 102 pass 103 104 def format_map(self, mapping): # real signature unknown; restored from __doc__ 105 """ 106 S.format_map(mapping) -> str 107 108 Return a formatted version of S, using substitutions from mapping. 109 The substitutions are identified by braces ('{' and '}'). 110 """ 111 return "" 112 113 def index(self, sub, start=None, end=None): # real signature unknown; restored from __doc__ 114 """ 115 S.index(sub[, start[, end]]) -> int 116 117 Return the lowest index in S where substring sub is found, 118 such that sub is contained within S[start:end]. Optional 119 arguments start and end are interpreted as in slice notation. 120 121 Raises ValueError when the substring is not found. 122 """ 123 return 0 124 125 def isalnum(self): # real signature unknown; restored from __doc__ 126 """ 127 S.isalnum() -> bool 128 129 Return True if all characters in S are alphanumeric 130 and there is at least one character in S, False otherwise. 131 """ 132 return False 133 134 def isalpha(self): # real signature unknown; restored from __doc__ 135 """ 136 S.isalpha() -> bool 137 138 Return True if all characters in S are alphabetic 139 and there is at least one character in S, False otherwise. 140 """ 141 return False 142 143 def isdecimal(self): # real signature unknown; restored from __doc__ 144 """ 145 S.isdecimal() -> bool 146 147 Return True if there are only decimal characters in S, 148 False otherwise. 149 """ 150 return False 151 152 def isdigit(self): # real signature unknown; restored from __doc__ 153 """ 154 S.isdigit() -> bool 155 156 Return True if all characters in S are digits 157 and there is at least one character in S, False otherwise. 158 """ 159 return False 160 161 def isidentifier(self): # real signature unknown; restored from __doc__ 162 """ 163 S.isidentifier() -> bool 164 165 Return True if S is a valid identifier according 166 to the language definition. 167 168 Use keyword.iskeyword() to test for reserved identifiers 169 such as "def" and "class". 170 """ 171 return False 172 173 def islower(self): # real signature unknown; restored from __doc__ 174 """ 175 S.islower() -> bool 176 177 Return True if all cased characters in S are lowercase and there is 178 at least one cased character in S, False otherwise. 179 """ 180 return False 181 182 def isnumeric(self): # real signature unknown; restored from __doc__ 183 """ 184 S.isnumeric() -> bool 185 186 Return True if there are only numeric characters in S, 187 False otherwise. 188 """ 189 return False 190 191 def isprintable(self): # real signature unknown; restored from __doc__ 192 """ 193 S.isprintable() -> bool 194 195 Return True if all characters in S are considered 196 printable in repr() or S is empty, False otherwise. 197 """ 198 return False 199 200 def isspace(self): # real signature unknown; restored from __doc__ 201 """ 202 S.isspace() -> bool 203 204 Return True if all characters in S are whitespace 205 and there is at least one character in S, False otherwise. 206 """ 207 return False 208 209 def istitle(self): # real signature unknown; restored from __doc__ 210 """ 211 S.istitle() -> bool 212 213 Return True if S is a titlecased string and there is at least one 214 character in S, i.e. upper- and titlecase characters may only 215 follow uncased characters and lowercase characters only cased ones. 216 Return False otherwise. 217 """ 218 return False 219 220 def isupper(self): # real signature unknown; restored from __doc__ 221 """ 222 S.isupper() -> bool 223 224 Return True if all cased characters in S are uppercase and there is 225 at least one cased character in S, False otherwise. 226 """ 227 return False 228 229 def join(self, iterable): # real signature unknown; restored from __doc__ 230 """ 231 S.join(iterable) -> str 232 233 Return a string which is the concatenation of the strings in the 234 iterable. The separator between elements is S. 235 """ 236 return "" 237 238 def ljust(self, width, fillchar=None): # real signature unknown; restored from __doc__ 239 """ 240 S.ljust(width[, fillchar]) -> str 241 242 Return S left-justified in a Unicode string of length width. Padding is 243 done using the specified fill character (default is a space). 244 """ 245 return "" 246 247 def lower(self): # real signature unknown; restored from __doc__ 248 """ 249 S.lower() -> str 250 251 Return a copy of the string S converted to lowercase. 252 """ 253 return "" 254 255 def lstrip(self, chars=None): # real signature unknown; restored from __doc__ 256 """ 257 S.lstrip([chars]) -> str 258 259 Return a copy of the string S with leading whitespace removed. 260 If chars is given and not None, remove characters in chars instead. 261 """ 262 return "" 263 264 def maketrans(self, *args, **kwargs): # real signature unknown 265 """ 266 Return a translation table usable for str.translate(). 267 268 If there is only one argument, it must be a dictionary mapping Unicode 269 ordinals (integers) or characters to Unicode ordinals, strings or None. 270 Character keys will be then converted to ordinals. 271 If there are two arguments, they must be strings of equal length, and 272 in the resulting dictionary, each character in x will be mapped to the 273 character at the same position in y. If there is a third argument, it 274 must be a string, whose characters will be mapped to None in the result. 275 """ 276 pass 277 278 def partition(self, sep): # real signature unknown; restored from __doc__ 279 """ 280 S.partition(sep) -> (head, sep, tail) 281 282 Search for the separator sep in S, and return the part before it, 283 the separator itself, and the part after it. If the separator is not 284 found, return S and two empty strings. 285 """ 286 pass 287 288 def replace(self, old, new, count=None): # real signature unknown; restored from __doc__ 289 """ 290 S.replace(old, new[, count]) -> str 291 292 Return a copy of S with all occurrences of substring 293 old replaced by new. If the optional argument count is 294 given, only the first count occurrences are replaced. 295 """ 296 return "" 297 298 def rfind(self, sub, start=None, end=None): # real signature unknown; restored from __doc__ 299 """ 300 S.rfind(sub[, start[, end]]) -> int 301 302 Return the highest index in S where substring sub is found, 303 such that sub is contained within S[start:end]. Optional 304 arguments start and end are interpreted as in slice notation. 305 306 Return -1 on failure. 307 """ 308 return 0 309 310 def rindex(self, sub, start=None, end=None): # real signature unknown; restored from __doc__ 311 """ 312 S.rindex(sub[, start[, end]]) -> int 313 314 Return the highest index in S where substring sub is found, 315 such that sub is contained within S[start:end]. Optional 316 arguments start and end are interpreted as in slice notation. 317 318 Raises ValueError when the substring is not found. 319 """ 320 return 0 321 322 def rjust(self, width, fillchar=None): # real signature unknown; restored from __doc__ 323 """ 324 S.rjust(width[, fillchar]) -> str 325 326 Return S right-justified in a string of length width. Padding is 327 done using the specified fill character (default is a space). 328 """ 329 return "" 330 331 def rpartition(self, sep): # real signature unknown; restored from __doc__ 332 """ 333 S.rpartition(sep) -> (head, sep, tail) 334 335 Search for the separator sep in S, starting at the end of S, and return 336 the part before it, the separator itself, and the part after it. If the 337 separator is not found, return two empty strings and S. 338 """ 339 pass 340 341 def rsplit(self, sep=None, maxsplit=-1): # real signature unknown; restored from __doc__ 342 """ 343 S.rsplit(sep=None, maxsplit=-1) -> list of strings 344 345 Return a list of the words in S, using sep as the 346 delimiter string, starting at the end of the string and 347 working to the front. If maxsplit is given, at most maxsplit 348 splits are done. If sep is not specified, any whitespace string 349 is a separator. 350 """ 351 return [] 352 353 def rstrip(self, chars=None): # real signature unknown; restored from __doc__ 354 """ 355 S.rstrip([chars]) -> str 356 357 Return a copy of the string S with trailing whitespace removed. 358 If chars is given and not None, remove characters in chars instead. 359 """ 360 return "" 361 362 def split(self, sep=None, maxsplit=-1): # real signature unknown; restored from __doc__ 363 """ 364 S.split(sep=None, maxsplit=-1) -> list of strings 365 366 Return a list of the words in S, using sep as the 367 delimiter string. If maxsplit is given, at most maxsplit 368 splits are done. If sep is not specified or is None, any 369 whitespace string is a separator and empty strings are 370 removed from the result. 371 """ 372 return [] 373 374 def splitlines(self, keepends=None): # real signature unknown; restored from __doc__ 375 """ 376 S.splitlines([keepends]) -> list of strings 377 378 Return a list of the lines in S, breaking at line boundaries. 379 Line breaks are not included in the resulting list unless keepends 380 is given and true. 381 """ 382 return [] 383 384 def startswith(self, prefix, start=None, end=None): # real signature unknown; restored from __doc__ 385 """ 386 S.startswith(prefix[, start[, end]]) -> bool 387 388 Return True if S starts with the specified prefix, False otherwise. 389 With optional start, test S beginning at that position. 390 With optional end, stop comparing S at that position. 391 prefix can also be a tuple of strings to try. 392 """ 393 return False 394 395 def strip(self, chars=None): # real signature unknown; restored from __doc__ 396 """ 397 S.strip([chars]) -> str 398 399 Return a copy of the string S with leading and trailing 400 whitespace removed. 401 If chars is given and not None, remove characters in chars instead. 402 """ 403 return "" 404 405 def swapcase(self): # real signature unknown; restored from __doc__ 406 """ 407 S.swapcase() -> str 408 409 Return a copy of S with uppercase characters converted to lowercase 410 and vice versa. 411 """ 412 return "" 413 414 def title(self): # real signature unknown; restored from __doc__ 415 """ 416 S.title() -> str 417 418 Return a titlecased version of S, i.e. words start with title case 419 characters, all remaining cased characters have lower case. 420 """ 421 return "" 422 423 def translate(self, table): # real signature unknown; restored from __doc__ 424 """ 425 S.translate(table) -> str 426 427 Return a copy of the string S in which each character has been mapped 428 through the given translation table. The table must implement 429 lookup/indexing via __getitem__, for instance a dictionary or list, 430 mapping Unicode ordinals to Unicode ordinals, strings, or None. If 431 this operation raises LookupError, the character is left untouched. 432 Characters mapped to None are deleted. 433 """ 434 return "" 435 436 def upper(self): # real signature unknown; restored from __doc__ 437 """ 438 S.upper() -> str 439 440 Return a copy of S converted to uppercase. 441 """ 442 return "" 443 444 def zfill(self, width): # real signature unknown; restored from __doc__ 445 """ 446 S.zfill(width) -> str 447 448 Pad a numeric string S with zeros on the left, to fill a field 449 of the specified width. The string S is never truncated. 450 """ 451 return ""
1 #range创建连续的数字 2 3 for item in range(0,100): 4 print(item) 5 #设置步长 6 for item in range(0,100,2): 7 print(item)
# -*- coding:utf-8 -*- # Author:sunhao name=input('username:') age=int(input('age:')) job=input('job:') salary=int(input('salary:')) info=''' --------info of %s---------- Name:%s Age:%d Job:%s Salary:%d '''%(name,name,age,job,salary) #第一种表示方法 info2=''' --------info of {_name}---------- Name:{_name} Age:{_age} Job:{_job} Salary:{_salary} '''.format(_name=name, _age=age, _job=job, _salary=salary) #第二种表示方法 .format() info3=''' --------info of {0}---------- Name:{0} Age:{1} Job:{2} Salary:{3} '''.format(name, age, job, salary) #第三种表示方法 print(info1) print(info2) print(info3) #三种显示结果是一样的
3、列表
通过list类创建的对象
names=['Lily','Tom','Lucy','Hanmeimei']
通过下标访问列表中的元素,下标从0开始:
In[3]: names = ['Lily', 'Tom', 'Lucy', 'Hanmeimei'] In[4]: names[0] Out[4]: 'Lily' In[5]: names[1] Out[5]: 'Tom' In[6]: names[-1] Out[6]: 'Hanmeimei' In[7]: names[-2] Out[7]: 'Lucy'
>>> names = ["Alex","Tenglan","Eric","Rain","Tom","Amy"] >>> names[1:4] #取下标1至下标4之间的数字,包括1,不包括4 ['Tenglan', 'Eric', 'Rain'] >>> names[1:-1] #取下标1至-1的值,不包括-1 ['Tenglan', 'Eric', 'Rain', 'Tom'] >>> names[0:3] ['Alex', 'Tenglan', 'Eric'] >>> names[:3] #如果是从头开始取,0可以忽略,跟上句效果一样 ['Alex', 'Tenglan', 'Eric'] >>> names[3:] #如果想取最后一个,必须不能写-1,只能这么写 ['Rain', 'Tom', 'Amy'] >>> names[3:-1] #这样-1就不会被包含了 ['Rain', 'Tom'] >>> names[0::2] #后面的2是代表,每隔一个元素,就取一个 ['Alex', 'Eric', 'Tom'] >>> names[::2] #和上句效果一样 ['Alex', 'Eric', 'Tom']
list.append() #列表追加元素 只是追加在列表的尾部 list1=['apple','orange','peach','watermelon'] list1.append('banana') #往列表中添加一个元素 print (list1) ['apple', 'orange', 'peach', 'watermelon', 'banana']
不能批量插入 list.insert(index, object) #往列表中插入一个元素 例如: list1=['apple','orange','peach','watermelon'] list1.insert(1,'Lemon') #在列表第一个位置插入Lemon这个元素 print (list1) ['apple', 'Lemon', 'orange', 'peach', 'watermelon', 'banana']
list1=['apple','orange','peach','watermelon'] list1[2]='fruit' #把peach修改为fruit print(list1) 输出: ['apple', 'Lemon', 'fruit', 'peach', 'watermelon', 'banana'] #peach被修改为 fruit
删除有两种方法: 第一种 list.remove() list1=['apple', 'Lemon', 'orange', 'peach', 'watermelon', 'banana'] list1.remove('apple') #remove方法 输出: print (list1) ['Lemon', 'fruit', 'peach', 'watermelon', 'banana'] 第二种 按下标方法删除 del list1[1] #删除列表中第1个元素
list.pop() # 默认是从列表中一次弹出最后一个元素 list.pop(1) # 如果输入下标 等于 del list1[1] 方法
list.index() #查找元素的位置 list1=['Lemon', 'fruit', 'peach', 'watermelon', 'banana'] list1.index('peach') #查找peach的位置 输出:2 #索引的位置为2 print(list1[list1.index('peach')]) 输出:peach
如果一个列表中有重复的元素,需要统计重复元素的个数 list.count() 例如: list1=['banana','peach','watermelon','banana','peach','apple','banana'] list1.count('banana') #统计列表中banana 的数量 输出: 3
list.clear()
list.reverse() list1=['banana', 'peach', 'watermelon', 'banana','peach','apple','tomato','banana'] list1.reverse() print (list1) ['banana', 'tomato', 'apple', 'peach', 'banana', 'watermelon', 'peach', 'banana'] #元素反转 位置改变
list.sort() list1=['banana', 'peach', 'watermelon', 'banana','peach','apple','tomato','banana'] list1.sort() print(list1) ['apple', 'banana', 'banana', 'banana', 'peach', 'peach', 'tomato', 'watermelon'] #按照字母排序
list.extend() #两个列表 list1=['banana', 'peach', 'watermelon', 'banana','peach','apple','tomato','banana'] list2=['lily','Lucy','Tom'] list1.extend(list2) #把list1和list2合并 print(list1) 输出: ['apple', 'banana', 'banana', 'banana', 'peach', 'peach', 'tomato', 'watermelon', 'lily', 'Lucy', 'Tom'] # 两个列表合并
names=['lucy','Lily','Jim','age'] new_names="".join(names) print(new_names)
4、元组(不可变列表)
元组一级元素不可被修改和删除。但是,元组中嵌套列表可以被修改
tu3=(111,222,[(333,444)],555,(666,777),) tu3[2][0]=888 print(tu3) #输出:(111, 222, [888], 555, (666, 777))
创建元组:
tuple=('tom','lily',1,2,) 一般写元组时,建议在最后加一个逗号
1 class tuple(object): 2 """ 3 tuple() -> empty tuple 4 tuple(iterable) -> tuple initialized from iterable's items 5 6 If the argument is a tuple, the return value is the same object. 7 """ 8 def count(self, value): # real signature unknown; restored from __doc__ 9 """ T.count(value) -> integer -- return number of occurrences of value """ 10 return 0 11 12 def index(self, value, start=None, stop=None): # real signature unknown; restored from __doc__ 13 """ 14 T.index(value, [start, [stop]]) -> integer -- return first index of value. 15 Raises ValueError if the value is not present. 16 """ 17 return 0 18 19 def __add__(self, *args, **kwargs): # real signature unknown 20 """ Return self+value. """ 21 pass 22 23 def __contains__(self, *args, **kwargs): # real signature unknown 24 """ Return key in self. """ 25 pass 26 27 def __eq__(self, *args, **kwargs): # real signature unknown 28 """ Return self==value. """ 29 pass 30 31 def __getattribute__(self, *args, **kwargs): # real signature unknown 32 """ Return getattr(self, name). """ 33 pass 34 35 def __getitem__(self, *args, **kwargs): # real signature unknown 36 """ Return self[key]. """ 37 pass 38 39 def __getnewargs__(self, *args, **kwargs): # real signature unknown 40 pass 41 42 def __ge__(self, *args, **kwargs): # real signature unknown 43 """ Return self>=value. """ 44 pass 45 46 def __gt__(self, *args, **kwargs): # real signature unknown 47 """ Return self>value. """ 48 pass 49 50 def __hash__(self, *args, **kwargs): # real signature unknown 51 """ Return hash(self). """ 52 pass 53 54 def __init__(self, seq=()): # known special case of tuple.__init__ 55 """ 56 tuple() -> empty tuple 57 tuple(iterable) -> tuple initialized from iterable's items 58 59 If the argument is a tuple, the return value is the same object. 60 # (copied from class doc) 61 """ 62 pass 63 64 def __iter__(self, *args, **kwargs): # real signature unknown 65 """ Implement iter(self). """ 66 pass 67 68 def __len__(self, *args, **kwargs): # real signature unknown 69 """ Return len(self). """ 70 pass 71 72 def __le__(self, *args, **kwargs): # real signature unknown 73 """ Return self<=value. """ 74 pass 75 76 def __lt__(self, *args, **kwargs): # real signature unknown 77 """ Return self<value. """ 78 pass 79 80 def __mul__(self, *args, **kwargs): # real signature unknown 81 """ Return self*value.n """ 82 pass 83 84 @staticmethod # known case of __new__ 85 def __new__(*args, **kwargs): # real signature unknown 86 """ Create and return a new object. See help(type) for accurate signature. """ 87 pass 88 89 def __ne__(self, *args, **kwargs): # real signature unknown 90 """ Return self!=value. """ 91 pass 92 93 def __repr__(self, *args, **kwargs): # real signature unknown 94 """ Return repr(self). """ 95 pass 96 97 def __rmul__(self, *args, **kwargs): # real signature unknown 98 """ Return self*value. """ 99 pass
str1="Mypython" tu1=tuple(str1) print(tu1) #输出:('M', 'y', 'p', 'y', 't', 'h', 'o', 'n')
names=['lucy','Lily','Jim','age'] tu2=tuple(names) print(tu2) #输出:('lucy', 'Lily', 'Jim', 'age')
name2=('lucy', 'Lily', 'Jim', 'age') list1=list(name2) print(list1) #输出:['lucy', 'Lily', 'Jim', 'age']
5、字典
字典一种key - value 的数据类型
字典的特性:
- dict是无序的
- key必须是唯一的,所以自动去重
语法:
user_info={ '01':'Tom', '02':'Jim', '03':'Lucy', '04':'Lily' }
a = user_info.keys() print(a)
#根据key获取值 a = user_info.get("age") print(a) #如果没有值,返回None,不报错 a = user_info.get("Age",19") print(a) #如果没有值,就返回19
user_info = { "name":"nick", "age":18, "job":"pythoner" } print(user_info.values()) #返回 dict_values(['nick', 18, 'pythoner'])
user_info = { "name":"nick", "age":18, "job":"pythoner" } print(user_info.items()) #输出:dict_items([('name', 'nick'), ('age', 18), ('job', 'pythoner')])
user_info = { "name":"nick", "age":18, "job":"pythoner" } #第一种删除方法 print(user_info.pop('name')) #输出{'age': 18, 'job': 'pythoner'} #第二种随机删除字典里的key和value print(user_info.popitem())
user_info = { "name":"nick", "age":18, "job":"pythoner" } user_info2 = { "wage":800000000, "drem":"The knife girl", "name":"jack" } #有交叉的就覆盖了 没有交叉就创建 user_info.update(user_info2) print(user_info) #输出:{'name': 'jack', 'age': 18, 'job': 'pythoner', 'wage': 800000000, 'drem': 'The knife girl'}
user_info = { "name":"nick", "age":18, "job":"pythoner" } #如果key不存在,则创建,如果存在,则返回已存在的值且不修改 print(user_info.setdefault('slary',5000)) print(user_info)
user_info = { "name":"nick", "age":18, "job":"pythoner" } print(user_info.clear()) print(user_info) #输出:{}
user_info = { "name":"nick", "age":18, "job":"pythoner" } del user_info['name'] print(user_info) #输出:{'age': 18, 'job': 'pythoner'}
#根据序列,创建字典并指定统一的值 info=dict.fromkeys(['slary','number'],5000) print(info) #输出:{'slary': 5000, 'number': 5000}
province={ '广东省':{'深圳市':['南山区','龙岗区','福田区'], '广州市':['荔湾区','海珠区','天河区'], '惠州市':['惠阳区','惠城区','惠东县']}, '浙江省':{'杭州市':['西湖区','上城区','下城区'], '宁波市':['江北区','镇海区'], '嘉兴市':['南湖区','秀洲区']} } print(province['广东省']) {'深圳市': ['南山区', '龙岗区', '福田区'], '广州市': ['荔湾区', '海珠区', '天河区'], '惠州市': ['惠阳区', '惠城区', '惠东县']}
province={ '广东省':{'深圳市':['南山区','龙岗区','福田区'], '广州市':['荔湾区','海珠区','天河区'], '惠州市':['惠阳区','惠城区','惠东县']}, '浙江省':{'杭州市':['西湖区','上城区','下城区'], '宁波市':['江北区','镇海区'], '嘉兴市':['南湖区','秀洲区']} } for k,v in province.items(): print(k,v)
user_info = { "name":"nick", "age":18, "job":"pythoner" } user_info2 = { "wage":800000000, "drem":"The knife girl", "name":"jack" } #有交叉的就覆盖了 没有交叉就创建 user_info.update(user_info2) 或者 user_info.update( "wage"=800000000, "drem"="The knife girl") print(user_info) #输出:{'name': 'jack', 'age': 18, 'job': 'pythoner', 'wage': 800000000, 'drem': 'The knife girl'}
6、set()集合
集合是一个无序的,不重复的数据组合,它的主要作用如下:
- 去重,把一个列表变成集合,就自动去重了
- 关系测试,测试两组数据之前的交集、差集、并集等关系
- 集合中元素必须是不可变类型,不能包含列表、字典
- 集合只可以追加、删除,但是不可修改
#列表 list1=[1,4,5,7,3,6,7,9] # 创建集合 集合也是无序的 set1=set(list1) print(set1,type(set1)) set2=set([2,6,0,66,22,8,4]) print(set1,set2) #输出: {1, 3, 4, 5, 6, 7, 9} <class 'set'> {1, 3, 4, 5, 6, 7, 9} {0, 2, 66, 4, 6, 8, 22}
list1=[1,4,5,7,3,6,7,9] set1=set(list1) set2=set([2,6,0,66,22,8,4]) print(set1.intersection(set2)) #输出:{4, 6}
list1=[1,4,5,7,3,6,7,9] set1=set(list1) set2=set([2,6,0,66,22,8,4]) #求并集两个集合去重合并 print(set1.union(set2)) #输出:{0, 1, 2, 3, 4, 5, 6, 7, 66, 9, 8, 22}
list1=[1,4,5,7,3,6,7,9] set1=set(list1) set2=set([2,6,0,66,22,8,4]) #set1中有 set2中没有的元素 print(set1.difference(set2)) #输出:{1, 3, 5, 7, 9} #set2中有 set1中没有的元素 print(set2.difference(set1)) #输出:{0, 2, 66, 8, 22}
list1=[1,4,5,7,3,6,7,9] set1=set(list1) set2=set([2,6,0,66,22,8,4]) #求子集 #判断set1是否是set2的子集 print(set1.issubset(set2)) #判断set2是否是set1的子集 print(set2.issubset(set1))
#求父集 list1=[1,4,5,7,3,6,7,9] set1=set(list1) set2=set([2,6,0,66,22,8,4]) # 判断set1是否是set2的父集 print(set1.issuperset(set2)) # 判断set2是否是set1的父集 print(set2.issuperset(set1))
list1=[1,4,5,7,3,6,7,9] set1=set(list1) set2=set([2,6,0,66,22,8,4]) #对称差集 print(set1.symmetric_difference(set2)) #输出: {0, 1, 2, 66, 3, 5, 8, 7, 9, 22}
list1=[1,4,5,7,3,6,7,9] set1=set(list1) set2=set([2,6,0,66,22,8,4]) #如果两个集合没有交集返回True 否则返回False print(set1.isdisjoint(set2)) #输出:False
print(set1 & set2) #交集 print(set1 | set2) #并集 print(set1 - set2) #差集 print(set1 ^ set2) #对称差集 list1=[1,4,5,7,3,6,7,9] set1=set(list1) set2=set([2,6,0,66,22,8,4]) #集合中是没有插入的,只能添加 set1.add(2) # 添加一项 set3 = set([100, 200, 300]) set1.update(set3) # 只能把一个集合更新到另一个集合中 set1.remove(100) # 删除集合中一个元素 set1.discard(100) # 删除一个元素 如果这个元素没有 不会报错 而remove会报错
# -*-coding:utf-8-*- # Author:sunhao product_list=[('Iphone',5800), ('Mac Pro',12000), ('Bike',800), ('Watch',10600), ('coffee',31) ] shopping_list=[] salary=input('请输入你的工资:') if salary.isdigit(): salary=int(salary) while True: for index,item in enumerate(product_list): print(index,item) user_choice=input("请选择要买的商品:") if user_choice.isdigit(): user_choice=int(user_choice) if user_choice<len(product_list) and user_choice >=0: p_item=product_list[user_choice] print(p_item) if p_item[1] <= salary: shopping_list.append(p_item) salary -= p_item[1] print('%s已添加至购物车 ,余额为%d'%(p_item[0],salary)) else: print("\033[41;1m你的余额只剩%s\033[0m"%salary) else: print("商品不存在") elif user_choice=='q': print("-------shoppinglist------") for p in shopping_list: print(p[0]) print('-------------------------') print('Your current balance:%s'%salary) exit() else: print('Invalid choice')
三、文件处理
1、文件操作
对文件操作流程
- 打开文件,得到文件句柄并赋值给一个变量
- 通过句柄对文件进行操作
- 关闭文件
Somehow, it seems the love I knew was always the most destructive kind 不知为何,我经历的爱情总是最具毁灭性的的那种 Yesterday when I was young 昨日当我年少轻狂 The taste of life was sweet 生命的滋味是甜的 As rain upon my tongue 就如舌尖上的雨露 I teased at life as if it were a foolish game 我戏弄生命 视其为愚蠢的游戏 The way the evening breeze 就如夜晚的微风 May tease the candle flame 逗弄蜡烛的火苗 The thousand dreams I dreamed 我曾千万次梦见 The splendid things I planned 那些我计划的绚丽蓝图 I always built to last on weak and shifting sand 但我总是将之建筑在易逝的流沙上 I lived by night and shunned the naked light of day 我夜夜笙歌 逃避白昼赤裸的阳光 And only now I see how the time ran away 事到如今我才看清岁月是如何匆匆流逝 Yesterday when I was young 昨日当我年少轻狂 So many lovely songs were waiting to be sung 有那么多甜美的曲儿等我歌唱 So many wild pleasures lay in store for me 有那么多肆意的快乐等我享受 And so much pain my eyes refused to see 还有那么多痛苦 我的双眼却视而不见 I ran so fast that time and youth at last ran out 我飞快地奔走 最终时光与青春消逝殆尽 I never stopped to think what life was all about 我从未停下脚步去思考生命的意义 And every conversation that I can now recall 如今回想起的所有对话 Concerned itself with me and nothing else at all 除了和我相关的 什么都记不得了 The game of love I played with arrogance and pride 我用自负和傲慢玩着爱情的游戏 And every flame I lit too quickly, quickly died 所有我点燃的火焰都熄灭得太快 The friends I made all somehow seemed to slip away 所有我交的朋友似乎都不知不觉地离开了 And only now I'm left alone to end the play, yeah 只剩我一个人在台上来结束这场闹剧 Oh, yesterday when I was young 噢 昨日当我年少轻狂 So many, many songs were waiting to be sung 有那么那么多甜美的曲儿等我歌唱 So many wild pleasures lay in store for me 有那么多肆意的快乐等我享受 And so much pain my eyes refused to see 还有那么多痛苦 我的双眼却视而不见 There are so many songs in me that won't be sung 我有太多歌曲永远不会被唱起 I feel the bitter taste of tears upon my tongue 我尝到了舌尖泪水的苦涩滋味 The time has come for me to pay for yesterday 终于到了付出代价的时间 为了昨日 When I was young 当我年少轻狂
f = open('lyrics','w','encoding=utf-8') #打开文件 f为文件句柄 data = f.read() #读文件 print(data) f.close() #关闭文件 f.readable() #判断文件是否可读 f.writable() #判断文件是都可写 f.closed() #判断文件是否关闭 返回True 和 False
打开一个文件包含两部分资源:操作系统级打开的文件+应用程序的变量。在操作完毕一个文件时,必须把与该文件的这两部分资源一个不落地回收,回收方法为: 1、f.close() #回收操作系统级打开的文件 2、del f #回收应用程序级的变量 其中del f一定要发生在f.close()之后,否则就会导致操作系统打开的文件还没有关闭,白白占用资源, 而python自动的垃圾回收机制决定了我们无需考虑del f,这就要求我们,在操作完毕文件后,一定要记住f.close() 我们推荐傻瓜式操作方式:使用with关键字来帮我们管理上下文 with open('a.txt','w') as f: pass with open('a.txt','r') as read_f,open('b.txt','w') as write_f: data=read_f.read() write_f.write(data)
f=open(...)是由操作系统打开文件,那么如果我们没有为open指定编码,那么打开文件的默认编码很明显是操作系统说了算了,操作系统会用自己的默认编码去打开文件,在windows下是gbk,在linux下是utf-8。 这就用到了上节课讲的字符编码的知识:若要保证不乱码,文件以什么方式存的,就要以什么方式打开。 f=open('a.txt','r',encoding='utf-8')
2、打开文件的模式
#1. 打开文件的模式有(默认为文本模式): r,只读模式【默认模式,文件必须存在,不存在则抛出异常】 w,只写模式【不可读;不存在则创建;存在则清空内容】 a,只追加写模式【不可读;不存在则创建;存在则只追加内容】 #2. 对于非文本文件,我们只能使用b模式,"b"表示以字节的方式操作(而所有文件也都是以字节的形式存储的,使用这种模式无需考虑文本文件的字符编码、图片文件的jgp格式、视频文件的avi格式) rb wb ab 注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码 #3. 了解部分 "+" 表示可以同时读写某个文件 r+, 读写【可读,可写】 w+,写读【可读,可写】 a+, 写读【可读,可写】
"U"表示在读取时,可以将 \r \n \r\n自动转换成 \n (与 r 或 r+ 模式同使用)
rU
r+U
x, 只写模式【不可读;不存在则创建,存在则报错】 x+ ,写读【可读,可写】 xb
3、操作文件的方法
f.read() #读取所有内容,光标移动到文件末尾 f.readline() #读取一行内容,光标移动到第二行首部 f.readlines() #读取每一行内容,存放于列表中 f.write('1111\n222\n') #针对文本模式的写,需要自己写换行符 f.write('1111\n222\n'.encode('utf-8')) #针对b模式的写,需要自己写换行符 f.writelines(['333\n','444\n']) #文件模式 f.writelines([bytes('333\n',encoding='utf-8'),'444\n'.encode('utf-8')]) #b模式
f = open('lyrics','r+',encoding='utf-8') for index,line in enumerate(f.readlines()): if index ==9: print(-------分隔符------) #第九行打印分隔符 跳出本次循环 continue print(line)
练习,利用b模式,编写一个cp工具,要求如下:
1. 既可以拷贝文本又可以拷贝视频,图片等文件
2. 用户一旦参数错误,打印命令的正确使用方法,如usage: cp source_file target_file
提示:可以用import sys,然后用sys.argv获取脚本后面跟的参数
import sys if len(sys.argv) != 3: print('usage: cp source_file target_file') sys.exit() source_file,target_file=sys.argv[1],sys.argv[2] with open(source_file,'rb') as read_f,open(target_file,'wb') as write_f: for line in read_f: write_f.write(line)
4、文件内光标移动
f = open('lyrics','r+',encoding='utf-8') print(f.tell()) f.read(16) print(f.tell()) 输出: 0 16
f = open('lyrics','r+',encoding='utf-8') print(f.tell()) f.read(16) print(f.tell()) f.seek(0) #移动到文件字符行首 print(f.tell()) 输出: 0 16 0
f = open('lyrics','r+',encoding='utf-8') print(f.encoding()) 输出: utf-8
f = open('lyrics','r+',encoding='utf-8') f.flush()
# -*-coding:utf-8-*- import sys,time for i in range(10): sys.stdout.write('#') sys.stdout.flush() 如果不加flush 是等缓存满了之后一次性打印出来 加了之后是打印在一次强制刷新一次 time.sleep(1)
truncate是截断文件,所以文件的打开方式必须可写,但是不能用w或w+等方式打开,因为那样直接清空文件了,所以truncate要在r+或a或a+等模式下测试效果
5、文件的修改
文件的数据是存放于硬盘上的,因而只存在覆盖、不存在修改这么一说,我们平时看到的修改文件,都是模拟出来的效果,具体的说有两种实现方式:
方式一:将硬盘存放的该文件的内容全部加载到内存,在内存中是可以修改的,修改完毕后,再由内存覆盖到硬盘(word,vim,nodpad++等编辑器)
import os with open('a.txt') as read_f,open('.a.txt.swap','w') as write_f: data=read_f.read() #全部读入内存,如果文件很大,会很卡 data=data.replace('alex','SB') #在内存中完成修改 write_f.write(data) #一次性写入新文件 os.remove('a.txt') os.rename('.a.txt.swap','a.txt')
方式二:将硬盘存放的该文件的内容一行一行地读入内存,修改完毕就写入新文件,最后用新文件覆盖源文件
import os with open('a.txt') as read_f,open('.a.txt.swap','w') as write_f: for line in read_f: line=line.replace('alex','SB') write_f.write(line) os.remove('a.txt') os.rename('.a.txt.swap','a.txt')
# -*-coding:utf-8-*- # Author:sunhao f = open('yesterday','r',encoding='utf-8') #打开要修改的文件 f_new = open('yesterday.bak','w',encoding='utf-8') #再打开一个要写入的新文件 for line in f: #循环旧文件里的每一行 if "肆意的快乐" in line: #每一行的type(line)是一个字符串 line=line.replace("肆意的快乐",'肆意的痛苦') #字符串替换 f_new.write(line) #写入新文件 f.close() #关闭旧文件 f_new.close() #关闭新文件
#with语句 为了避免打开文件后忘记关闭,可以通过管理上下文,即: with open('file','r','encoding='uth-8'') as f: #f为文件句柄 for line in f: print(line) 这样不用关闭文件 也可以同时操作多个文件 with open('file1','r','encoding=utf-8') as f1,open('file2','r','encoding=utf-8') as f2: pass
import sys f = open('yesterday','r',encoding='utf-8') f_new = open('yesterday.bak','w',encoding='utf-8') find_str=sys.argv[1] replace_str=sys.argv[2] for line in f: if find_str in line: line=line.replace(find_str,replace_str) f_new.write(line) f.close() f_new.close()
四、其他
1、字符编码与转码
1.在python2默认编码是ASCII, python3里默认是unicode
2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-16就是现在最常用的unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间
3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
name='中国' new_name=name.encode('utf-8') #对字符串name编码 成二进制字节码 print (new_name) 输出: b'\xe4\xb8\xad\xe5\x9b\xbd'
name='中国' new_name=name.encode('utf-8') #对字符串name编码成二进制字节码 renew_name=new_name.decode() #对二进制字节码进行解码 print (renew_name) 输出: 中国
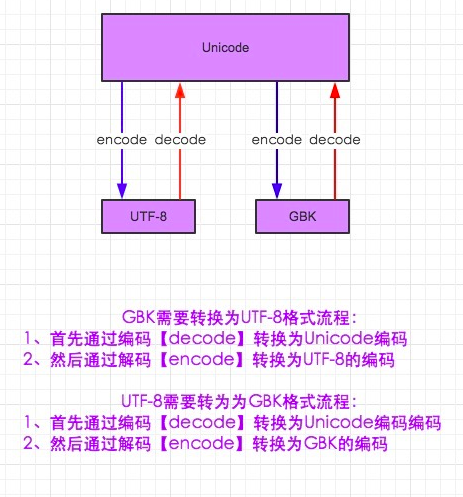
上图仅适用于python2
#-*- encoding:utf-8 -*- import sys print(sys.getdefaultencoding()) #打印系统默认编码 s='你好' s_to_unicode=s.decode('utf-8') #先解码成unicode print(s_to_unicode,type(s_to_unicode)) s_to_gbk=s_to_unicode.encode('gbk') #再编码成gbk print(s_to_gbk) print('你好') #把gbk再转成utf-8 gbk_to_utf8=s_to_gbk.decode('gbk').encode('utf-8') print(gbk_to_utf8)
#在python3中默认的字符编码是unicode-utf8所以不需要decode了 #-*-coding:gb2312 -*- #这个也可以去掉 #默认字符集为gb2312 __author__ = 'Alex Li' import sys print(sys.getdefaultencoding()) msg = "我爱北京天安门" #msg_gb2312 = msg.decode("utf-8").encode("gb2312") #在python2中需要先解码成unicode再编码成gb2312 msg_gb2312 = msg.encode("gb2312") #python3中默认就是unicode utf8,不用再decode,喜大普奔 gb2312_to_unicode = msg_gb2312.decode("gb2312") gb2312_to_utf8 = msg_gb2312.decode("gb2312").encode("utf-8") print(msg) print(msg_gb2312) print(gb2312_to_unicode) print(gb2312_to_utf8)
hex()十进制转换为十六进制hex()二进制转十六进制
#十进制转二进制 number=10 to_bin=bin(number) print(to_bin) #输出:0b1010 #十六进制转二进制 number=0xff to_bin=bin(number) print(to_bin) #输出:0b11111111
#十六进制转十进制 number=0xff to_int=int(number) print(to_int) #输出:255 #二进制转十进制 number=0b11111111 to_int=int(number) print(to_int) #输出:255
name = "python之路" a = bytes(name, encoding='utf-8') print(a) for i in a: print(i,bin(i)) b = bytes(name, encoding='gbk') print(b) for i in b: print(i, bin(i))
2、三元运算符
result= 值1 if 条件 else 值2 如果条件为真:result=值1 如果条件为假:result=值2 a,b,c=1,4,6 d= a if a>b else c
3、input和raw_input
# -*-coding:utf-8 -*- name=raw_input('请输入你的名字:') #raw_input仅适用于python2.7版本 age=input('请输入你的年龄:') print("%s的年龄是%s:"%(name,age))
# 输入密码时,如果想要不可见,需要利用getpass 模块中的 getpass方法 import getpass #导入getpass模块 _username='sunhao' _password='abc123' username = input("usename:") password = getpass.getpass("password:") if _username==username and password == _password: print("Welcome user {name} login...".format(name=_username)) else: print("Invalid username or password")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号