♠ JavaScript数据结构与算法之树结构
♣ 树的特点:
- 树一般都有一个根,连接着根的是树干;
- 树干会发生分叉,形成许多树枝,树枝会继续分化成更小的树枝;
- 树枝的最后是叶子;
现实生活中很多结构都是树的抽象,模拟的树结构相当于旋转 180° 的树。
树结构对比于数组/链表/哈希表有哪些优势呢?
数组:
- 优点:可以通过下标值访问,效率高;
- 缺点:查找数据时需要先对数据进行排序,生成有序数组,才能提高查找效率;并且在插入和删除元素时,需要大量的位移操作;
链表:
- 优点:数据的插入和删除操作效率都很高;
- 缺点:查找效率低,需要从头开始依次查找,直到找到目标数据为止;当需要在链表中间位置插入或删除数据时,插入或删除的效率都不高。
哈希表:
- 优点:哈希表的插入/查询/删除效率都非常高;
- 缺点:空间利用率不高,底层使用的数组中很多单元没有被利用;并且哈希表中的元素是无序的,不能按照固定顺序遍历哈希表中的元素;而且不能快速找出哈希表中最大值或最小值这些特殊值。
树结构:
- 优点:树结构综合了上述三种结构的优点,同时也弥补了它们存在的缺点(虽然效率不一定都比它们高),比如树结构中数据都是有序的,查找效率高;空间利用率高;并且可以快速获取最大值和最小值等。
总的来说:每种数据结构都有自己特定的应用场景。
树结构:
- 树(Tree):由 n(n ≥ 0)个节点构成的有限集合。当 n = 0 时,称为空树。
对于任意一棵非空树(n > 0),它具备以下性质:
- 数中有一个称为根(Root)的特殊节点,用 r 表示;
- 其余节点可分为 m(m > 0)个互不相交的有限集合 T1,T2,...,Tm,其中每个集合本身又是一棵树,称为原来树的子树(SubTree)。
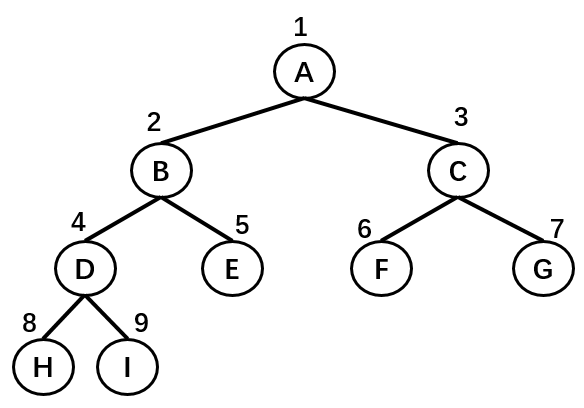
♣ 树的常用术语:
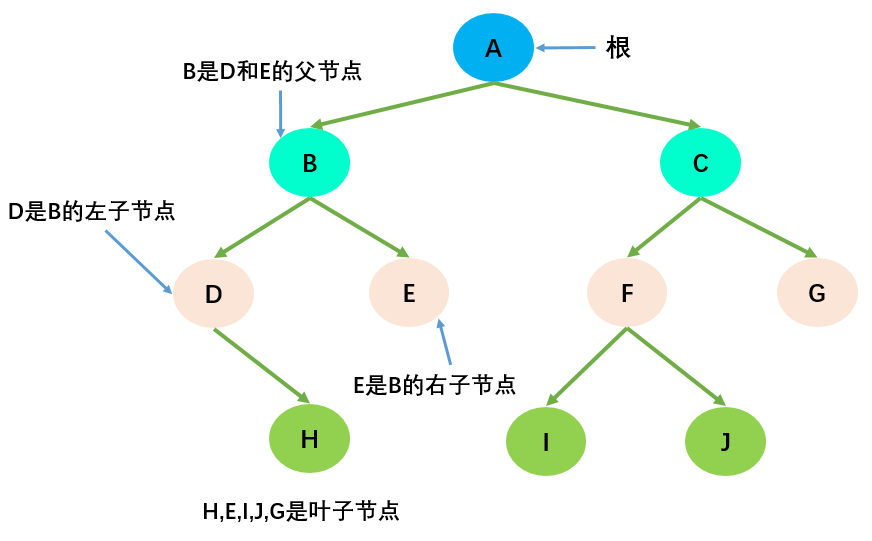
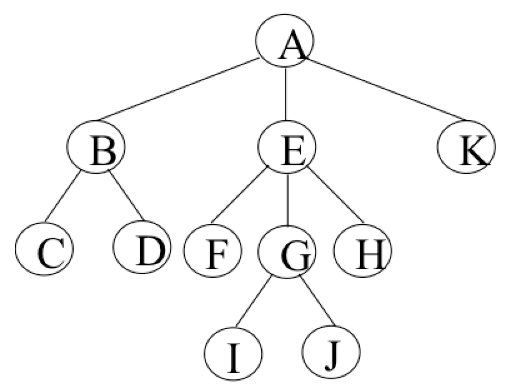
- 节点的度(Degree):节点的子树个数,比如节点 B 的度为 2;
- 树的度:树的所有节点中最大的度数,如上图树的度为 2;
- 叶节点(Leaf):度为 0 的节点(也称为叶子节点),如上图的 H,I 等;
- 父节点(Parent):度不为 0 的节点称为父节点,如上图节点 B 是节点 D 和 E 的父节点;
- 子节点(Child):若 B 是 D 的父节点,那么 D 就是 B 的子节点;
- 兄弟节点(Sibling):具有同一父节点的各节点彼此是兄弟节点,比如上图的 B 和 C,D 和 E 互为兄弟节点;
- 路径和路径长度:路径指的是一个节点到另一节点的通道,路径所包含边的个数称为路径长度,比如 A->H 的路径长度为 3;
- 节点的层次(Level):规定根节点在 1 层,其他任一节点的层数是其父节点的层数加 1。如 B 和 C 节点的层次为 2;
- 树的深度(Depth):树种所有节点中的最大层次是这棵树的深度,如上图树的深度为 4;
♣ 树结构的表示方式
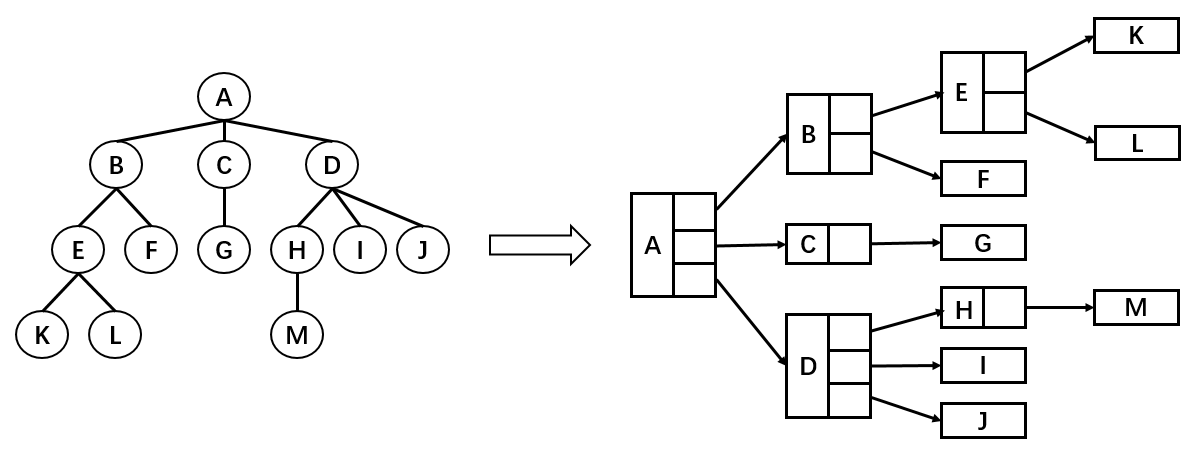
如图,树结构的组成方式类似于链表,都是由一个个节点连接构成。不过,根据每个父节点子节点数量的不同,每一个父节点需要的引用数量也不同。比如节点 A 需要 3 个引用,分别指向子节点 B,C,D;B 节点需要 2 个引用,分别指向子节点 E 和 F;K 节点由于没有子节点,所以不需要引用。这种方法缺点在于我们无法确定某一结点的引用数。
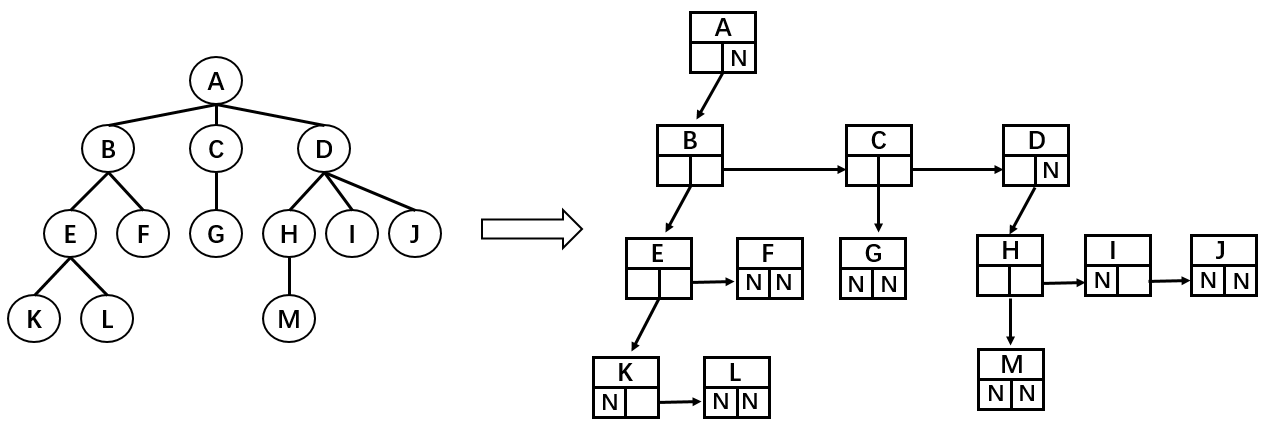
儿子-兄弟表示法:
点击查看代码
//节点A
Node{
//存储数据
this.data = data
//统一只记录左边的子节点
this.leftChild = B
//统一只记录右边的第一个兄弟节点
this.rightSibling = null
}
//节点B
Node{
this.data = data
this.leftChild = E
this.rightSibling = C
}
//节点F
Node{
this.data = data
this.leftChild = null
this.rightSibling = null
}
这种表示法的优点在于每一个节点中引用的数量都是确定的。
将其顺时针旋转 45° 之后:
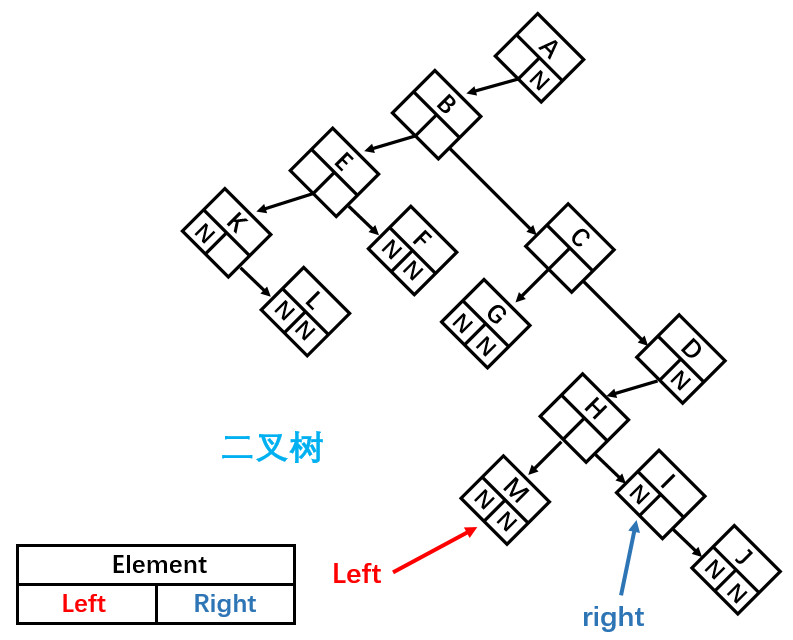
这样就成为了一棵二叉树,由此我们可以得出结论:任何树都可以通过二叉树进行模拟。但是这样父节点不是变了吗?其实,父节点的设置只是为了方便指向子节点,在代码实现中谁是父节点并没有关系,只要能正确找到对应节点即可。
♣ 二叉树
如果树中的每一个节点最多只能由两个子节点,这样的树就称为二叉树;
二叉树的组成
- 二叉树可以为空,也就是没有节点;
- 若二叉树不为空,则它由根节点和称为其左子树 TL 和右子树 TR 的两个不相交的二叉树组成;
二叉树的五种形态
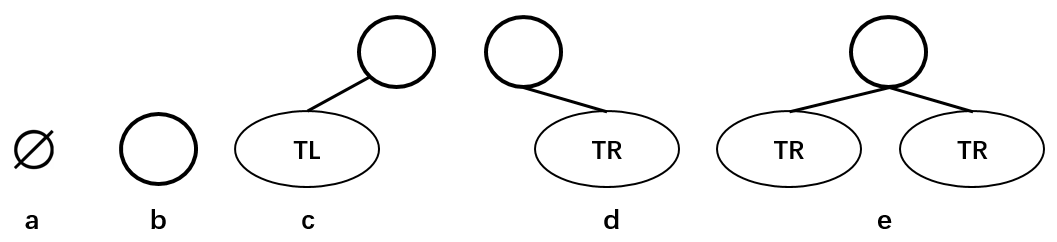
上图分别表示:空的二叉树、只有一个节点的二叉树、只有左子树 TL 的二叉树、只有右子树 TR 的二叉树和有左右两个子树的二叉树。
二叉树的特性
- 一个二叉树的第 i 层的最大节点树为:2^(i-1)^,i >= 1;
- 深度为 k 的二叉树的最大节点总数为:2^k^ - 1 ,k >= 1;
- 对任何非空二叉树,若 n~0~ 表示叶子节点的个数,n~2~表示度为 2 的非叶子节点个数,那么两者满足关系:n~0~ = n~2~ + 1;如下图所示:H,E,I,J,G 为叶子节点,总数为 5;A,B,C,F 为度为 2 的非叶子节点,总数为 4;满足 n~0~ = n~2~ + 1 的规律。
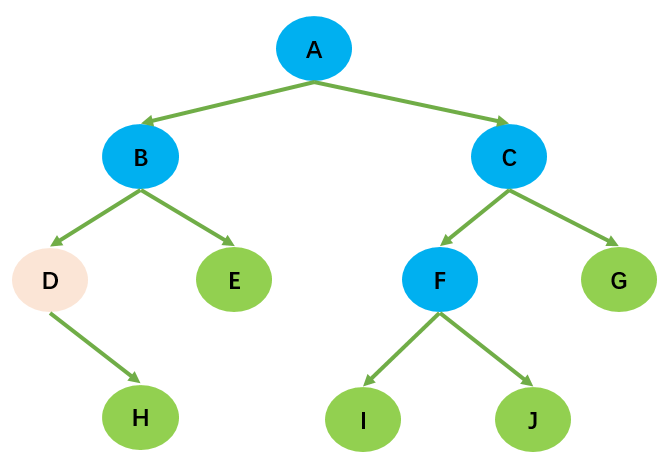
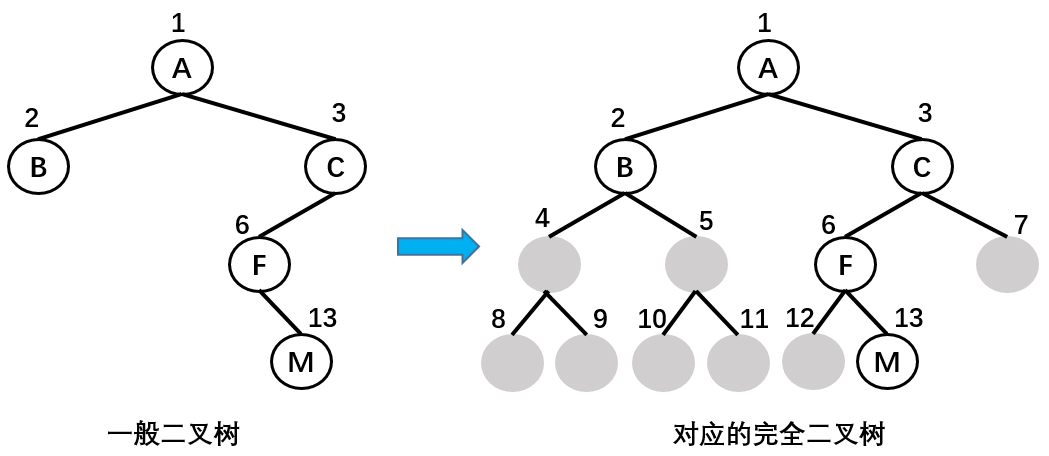
完全二叉树
完全二叉树(Complete Binary Tree):
- 除了二叉树最后一层外,其他各层的节点数都达到了最大值;
- 并且,最后一层的叶子节点从左向右是连续存在,只缺失右侧若干叶子节点;
- 完美二叉树是特殊的完全二叉树
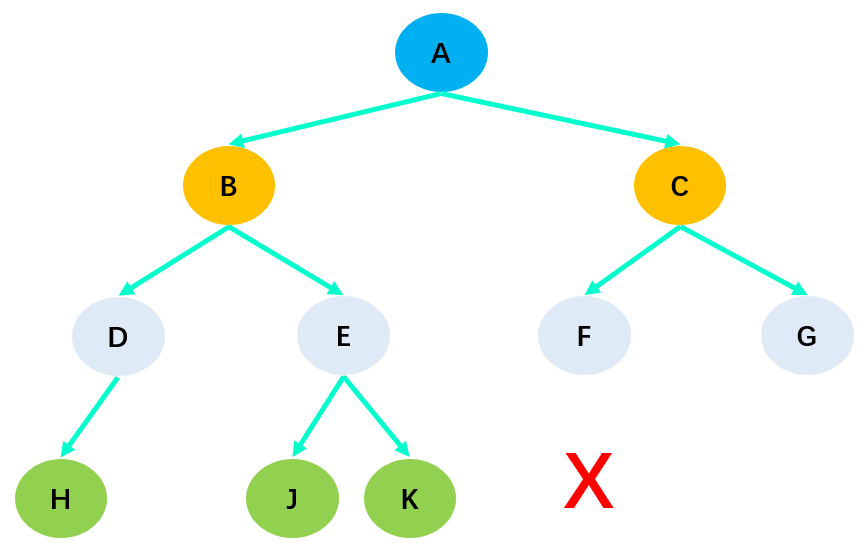
在上图中,由于 H 缺失了右子节点,所以它不是完全二叉树。
二叉树的数据存储
常见的二叉树存储方式为数组和链表:
使用数组
-
完全二叉树:按从上到下,从左到右的方式存储数据。
| 节点 | A | B | C | D | E | F | G | H | I |
|---|---|---|---|---|---|---|---|---|---|
| 序号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
使用数组存储时,取数据的时候也十分方便:左子节点的序号等于父节点序号 *2,右子节点的序号等于父节点序号 *2 + 1 。
非完全二叉树:非完全二叉树需要转换成完全二叉树才能按照上面的方案存储,这样会浪费很大的存储空间。

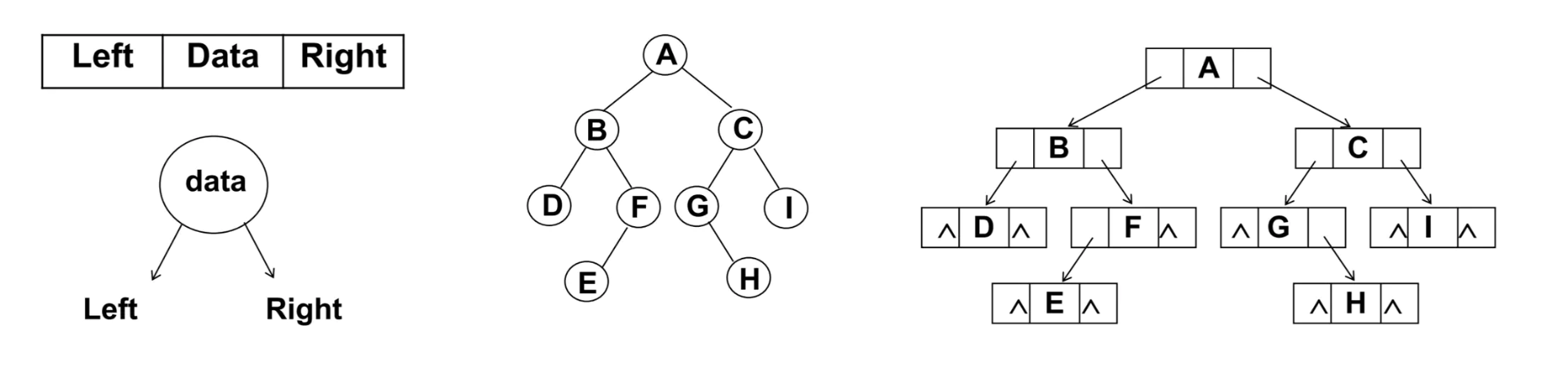
使用链表
二叉树最常见的存储方式为链表:每一个节点封装成一个 Node,Node 中包含存储的数据、左节点的引用和右节点的引用
二叉搜索树(排序)
二叉搜索树(BST,Binary Search Tree),也称为二叉排序树和二叉查找树。
二叉搜索树是一棵二叉树,可以为空。
如果不为空,则满足以下性质:
- 条件 1:非空左子树的所有键值小于其根节点的键值。比如三中节点 6 的所有非空左子树的键值都小于 6;
- 条件 2:非空右子树的所有键值大于其根节点的键值;比如三中节点 6 的所有非空右子树的键值都大于 6;
- 条件 3:左、右子树本身也都是二叉搜索树;
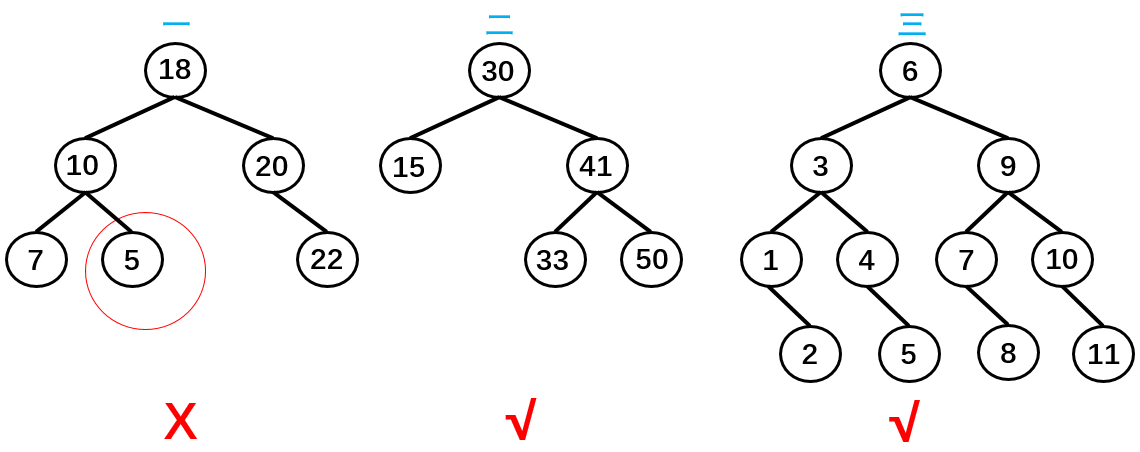
如上图所示,树二和树三符合 3 个条件属于二叉树,树一不满足条件 3 所以不是二叉树。
总结:二叉搜索树的特点主要是较小的值总是保存在左节点上,相对较大的值总是保存在右节点上。这种特点使得二叉搜索树的查询效率非常高,这也就是二叉搜索树中“搜索”的来源。
二叉搜索树应用举例
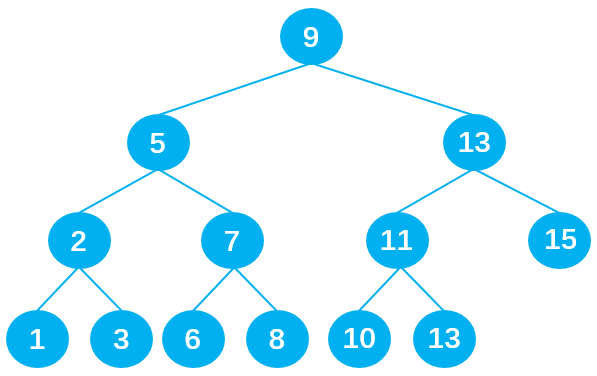
若想在其中查找数据 10,只需要查找 4 次,查找效率非常高。
- 第 1 次:将 10 与根节点 9 进行比较,由于 10 > 9,所以 10 下一步与根节点 9 的右子节点 13 比较;
- 第 2 次:由于 10 < 13,所以 10 下一步与父节点 13 的左子节点 11 比较;
- 第 3 次:由于 10 < 11,所以 10 下一步与父节点 11 的左子节点 10 比较;
- 第 4 次:由于 10 = 10,最终查找到数据 10 。
同样是 15 个数据,在排序好的数组中查询数据 10,需要查询 10 次:

二叉搜索树的封装
二叉搜索树有四个最基本的属性:指向节点的根(root),节点中的键(key)、左指针(right)、右指针(right)。
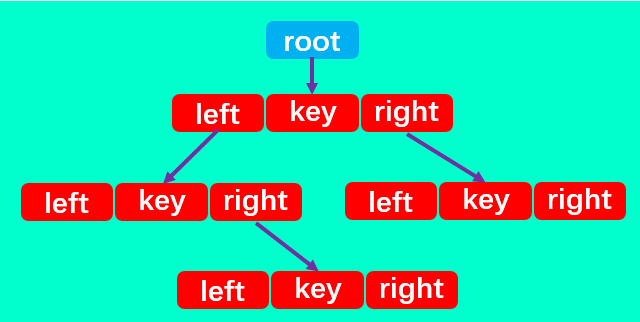
所以,二叉搜索树中除了定义 root 属性外,还应定义一个节点内部类,里面包含每个节点中的 left、right 和 key 三个属性。
点击查看代码
// 节点类
class Node {
constructor(key) {
this.key = key;
this.left = null;
this.right = null;
}
}
二叉搜索树的常见操作:
insert(key)向树中插入一个新的键。search(key)在树中查找一个键,如果节点存在,则返回 true;如果不存在,则返回false。preOrderTraverse通过先序遍历方式遍历所有节点。inOrderTraverse通过中序遍历方式遍历所有节点。postOrderTraverse通过后序遍历方式遍历所有节点。min返回树中最小的值/键。max返回树中最大的值/键。remove(key)从树中移除某个键。
插入数据
实现思路:
- 首先根据传入的 key 创建节点对象。
- 然后判断根节点是否存在,不存在时通过:this.root = newNode,直接把新节点作为二叉搜索树的根节点。
- 若存在根节点则重新定义一个内部方法
insertNode()用于查找插入点。
点击查看代码
// insert(key) 插入数据
insert(key) {
const newNode = new Node(key);
if (this.root === null) {
this.root = newNode;
} else {
this.insertNode(this.root, newNode);
}
}
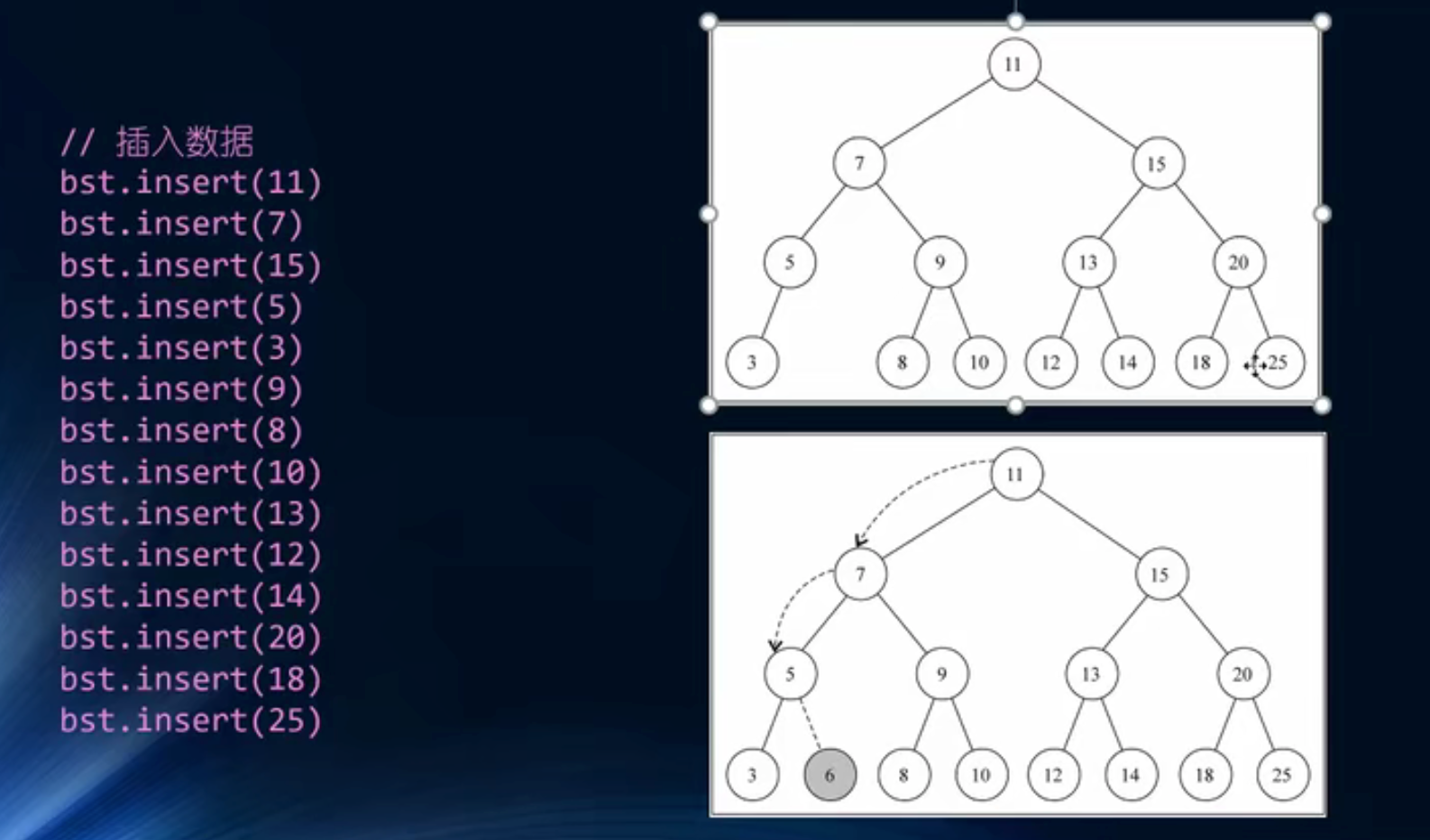
insertNode() 的实现思路:
根据比较传入的两个节点,一直查找新节点适合插入的位置,直到成功插入新节点为止。
-
当 newNode.key < node.key 向左查找:
-
情况 1:当 node 无左子节点时,直接插入:
-
情况 2:当 node 有左子节点时,递归调用 insertNode(),直到遇到无左子节点成功插入 newNode 后,不再符合该情况,也就不再调用 insertNode(),递归停止。
-
-
当 newNode.key >= node.key 向右查找,与向左查找类似:
-
情况 1:当 node 无右子节点时,直接插入:
-
情况 2:当 node 有右子节点时,依然递归调用 insertNode(),直到遇到传入 insertNode 方法 的 node 无右子节点成功插入 newNode 为止。
-
insertNode(root, node) 代码实现
点击查看代码
insertNode(root, node) {
if (node.key < root.key) { // 往左边查找插入
if (root.left === null) {
root.left = node;
} else {
this.insertNode(root.left, node);
}
} else { // 往右边查找插入
if (root.right === null) {
root.right = node;
} else {
this.insertNode(root.right, node);
}
}
}
遍历数据
这里所说的树的遍历不仅仅针对二叉搜索树,而是适用于所有的二叉树。由于树结构不是线性结构,所以遍历方式有多种选择,常见的三种二叉树遍历方式为:
- 先序遍历;
- 中序遍历;
- 后序遍历;
还有层序遍历,使用较少。
先序遍历
先序遍历的过程为:首先,遍历根节点; 然后,遍历其左子树; 最后,遍历其右子树;
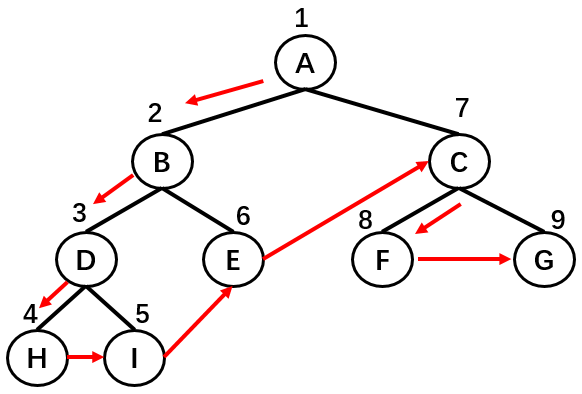
如上图所示,二叉树的节点遍历顺序为:A -> B -> D -> H -> I -> E -> C -> F -> G。
点击查看代码
// 先序遍历(根左右 DLR)
preorderTraversal() {
const result = [];
this.preorderTraversalNode(this.root, result);
return result;
}
preorderTraversalNode(node, result) {
if (node === null) return result;
result.push(node.key);
this.preorderTraversalNode(node.left, result);
this.preorderTraversalNode(node.right, result);
}
中序遍历
实现思路:与先序遍历原理相同,只不过是遍历的顺序不一样了。首先,遍历其左子树; 然后,遍历根(父)节点; 最后,遍历其右子树;
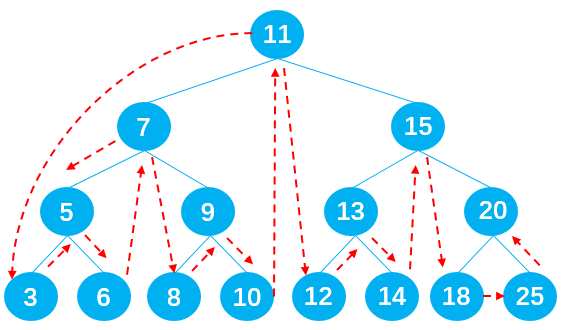
输出节点的顺序应为:3 -> 5 -> 6 -> 7 -> 8 -> 9 -> 10 -> 11 -> 12 -> 13 -> 14 -> 15 -> 18 -> 20 -> 25 。
点击查看代码
// 中序遍历(左根右 LDR)
inorderTraversal() {
const result = [];
this.inorderTraversalNode(this.root, result);
return result;
}
inorderTraversalNode(node, result) {
if (node === null) return result;
this.inorderTraversalNode(node.left, result);
result.push(node.key);
this.inorderTraversalNode(node.right, result);
}
后序遍历
实现思路:与先序遍历原理相同,只不过是遍历的顺序不一样了。首先,遍历其左子树; 然后,遍历其右子树; 最后,遍历根(父)节点;
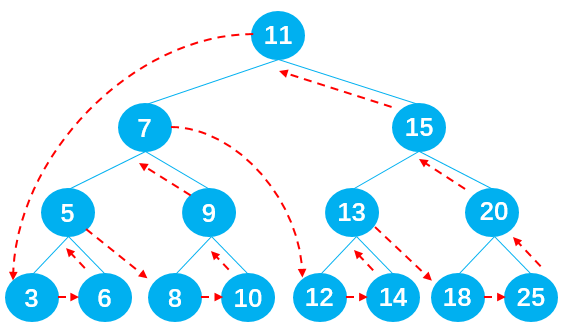
点击查看代码
// 后序遍历(左右根 LRD)
postorderTraversal() {
const result = [];
this.postorderTraversalNode(this.root, result);
return result;
}
postorderTraversalNode(node, result) {
if (node === null) return result;
this.postorderTraversalNode(node.left, result);
this.postorderTraversalNode(node.right, result);
result.push(node.key);
}
总结
以遍历根(父)节点的顺序来区分三种遍历方式。比如:先序遍历先遍历根节点、中序遍历第二遍历根节点、后续遍历最后遍历根节点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号