关于 `release`、`acquire` 语义
根据源码注释,release 和 acquire需要成对使用才可保证可见性,如果需要一条指令即可保证可见性,则需要使用 membar 全屏障指令。并且,对于 release 操作后的写不能不能保证,后续的load一定能获取到最新的值,而通过 acquire 方式的load 一定是可以的获取 release前的操作结果。
也就是说 release 操作走,没有加storeload屏障,也就没有要求写store操作立即对所有的load可见,如果需要紧急可靠的load 的时可以用acquire-load。
综合来说 ,如果通过 acquire 模型,获取到了 release 操作的变量结果,那也就意味着,release 操作前的操作的结果也能保证可见,重要的目的更是为了 保证顺序性,就是按程序的顺序正常执行。我认为,并不是让 release 写入的结果立即可见,而是保证release可见时,前面的结果也看见了,不然的的话不就是和 storeload的效果一样了么。
// T1: access_shared_data
// T1: ]release
\-------------------/
// T1: (...)
// T1: store(X)
===============
// T2: load(X)
// T2: (...)
/-------------------\
// T2: acquire[
// T2: access_shared_data
============== 2 ===============================
thread1:
result = 100
flag = true
\ /
\---------------/ (release语义)
thread2:
/--------------------\ (acquire语义)
/ if (flag) \
print (result)
从HotSpot源码看Java volatile: http://kexianda.info/2017/04/28/从HotSpot源码看Java-volatile/
============== 3 ===============================
acquire semantics, 硬件层面就是保证在此之后的所有指令在执行的时候都不能重排到这 个指令之前, 软件层面在此之后的所有操作都不能重排到这个语义(fence)之前

硬件层面, 在执行 这个”指令”之后的,所有内存的load操作都看到的 其他核”最新”的变更(depends on memory model of the CPU), 也就是说在这个”指令”之后 的所有对的指令都不能reorder 到这个”指令”之前. 同样的, 在ARM上这个”指令”是dmb, 在PowerPC上是lwsync, 在x86-64上不需要单独的指令.
release semantics, 硬件层面就是保证在此之前的所有store都已经”release”可见, 软件层面在此之前的所有操作都不能重排到这个语义(fence)之后

release samentic和字面意思很像. 硬件层面, 这个语义(也许是一条CPU instruction)在执行这个 “指令”之后, 发生在这个”指令”之前(happens-before)的所有内存的store/load操作在所有 核都可见, 更直观的解释就是在这个”指令”, 之后的所有指令不能reorder到这个”指令” 之前. 在ARM上这个”指令”是dmb, 在PowerPC上是lwsync, 在x86-64的CPU上不需要 单独 的一个”指令”完成这个事情, 因为x86-64的strong hardware memory model类型的处 理器.
http://gavinchou.github.io/summary/c++/memory-ordering/#acquire and relase semantics by preshing
============== 4 ===============================

https://www.arangodb.com/2021/02/cpp-memory-model-migrating-from-x86-to-arm/
============== 5 ===============================
对于Acquire来说,保证Acquire后的读写操作不会发生在Acquire动作之前
对于Release来说,保证Release前的读写操作不会发生在Release动作之后
Acquire & Release 语义保证内存操作仅在acquire和release屏障之间发生
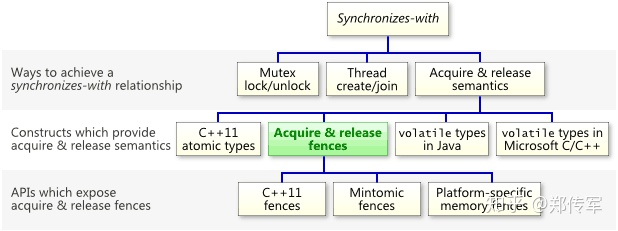
可以看到synchronizes-with是一种跨线程间的happens-before关系,此外我们可以通过mutex lock、thread create/join、Aquire and release Semantic来建立synchronized-with关系,Aquire and Release是因为另外一个复杂的关系概念,所以我可以再开一篇文章再谈,其余下有更重要的C++原子类型、内存栅栏和易失性类型等语法,再接着介绍。
http://opass.logdown.com/posts/797957-concurrency-series-4-be-with-the-synchronizes-with-relation
X86-64中Load读操作本身满足Acquire语义,Store写操作本身也是满足Release语义。但Store-Load操作间等于没有保护,因此仍需要靠mfence或lock等指令才可以满足到Synchronizes-with规则。
https://zhuanlan.zhihu.com/p/43526907
============== 6 ===============================
LD, ACQ是一条隐含half-memory fence功能的load操作,该指令之前的内存操作可以delay至该指令之后执行,反之则不可以。类似的,还有一个rel的修饰符,也是提供了支持half-memory fence功能,不同的是rel是约束rel修饰的那条指令之前的内存访问操作不得越过该指令之后执行。
https://blog.csdn.net/reliveIT/article/details/106898762
============== 7 ===============================
memory_order_acquire:用来修饰一个读操作,表示在本线程中,所有后续的关于此变量的内存操作都必须在本条原子操作完成后执行。
memory_order_release:用来修饰一个写操作,表示在本线程中,所有之前的针对该变量的内存操作完成后才能执行本条原子操作。
memory_order_acq_rel:同时包含memory_order_acquire和memory_order_release标志。
针对x、y两个变量的写操作是分别在write_x和write_y线程中进行的,即便在这里使用了release-acquire模型,仍然没有保证z=0,从以上的分析可以看出,针对同一个变量的release-acquire操作,更多时候扮演了一种“线程间使用某一变量的同步”作用,由于有了这个语义的保证,做到了线程间操作的先后顺序保证(inter-thread happens-before)。
Acquire-Release能保证不同线程之间的Synchronizes-With关系,这同时也约束到同一个线程中前后语句的执行顺序。
而Release-Consume只约束有明确的carry-a-dependency关系的语句的执行顺序,同一个线程中的其他语句的执行先后顺序并不受这个内存模型的影响。
https://www.codedump.info/post/20191214-cxx11-memory-model-2/
============== 8 ===============================
线程可以通过两种方式操作共享内存:它们可以相互竞争资源,或者它们可以合作地将信息从一个线程传递到另一个线程。获取和释放语义对于后者至关重要:在线程之间可靠地传递信息。
主要是说:当通过acquire模型获取到了release操作的变量,则也能推导出release之前的操作也对acquire之后的操作可见,是一个简单的对齐方式
Once again, both of the above atomic_thread_fence() calls can be (and hopefully are) implemented as lwsync on PowerPC. Similarly, they could both emit a dmb instruction on ARM, which I believe is at least as effective as PowerPC’s lwsync. On x86/64, both atomic_thread_fence() calls can simply be implemented as compiler barriers, since usually, every load on x86/64 already implies acquire semantics and every store implies release semantics. This is why x86/64 is often said to be strongly ordered.
Just as before, r1 == 1 indicates a synchronizes-with relationship, serving as confirmation that r2 == 42.
https://preshing.com/20120913/acquire-and-release-semantics/
在java中对volatile语义进行了增强,在 C++ 中的只对volatile变量才有禁止重排序的功能,但是在JAva对非volatile变量和volatile变量之间也做了限制。
https://www.cnblogs.com/god-of-death/p/7852394.html
============== 9 ===============================
尽可能使用acquire和release语义进行同步 :https://support.huaweicloud.com/codeprtr-kunpenggrf/kunpengtaishanporting_12_0049.html
Cache一致性和内存模型:https://wudaijun.com/2019/04/cpu-cache-and-memory-model/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号