
第二次作业
个人项目
Github下的dev分支中
PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 5 | 5 |
| · Estimate | · 估计这个任务需要多少时间 | 5 | 5 |
| Development | 开发 | 335 | 420 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 80 |
| · Design Spec | · 生成设计文档 | 20 | 20 |
| · Design Review | · 设计复审 | 20 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 60 | 80 |
| · Design | · 具体设计 | 30 | 30 |
| · Coding | · 具体编码 | 150 | 180 |
| · Code Review | · 代码复审 | 5 | 10 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 100 | 200 |
| Reporting | 报告 | 100 | 100 |
| · Test Repor | · 测试报告 | 60 | 60 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 10 |
| · 合计 | 440 | 525 |
计算模块接口的设计与实现过程
1. 实现算法-Simhash算法
具体步骤如下
- 文本预处理:对原始文本进行分词、去除停用词等预处理操作,得到一组关键词。
- 特征提取:对每个关键词计算其哈希值,使用哈希函数
MD5将关键词映射为一个固定长度的二进制串。 - 特征加权:对于每个关键词根据TF-IDF值来确定权重,再对其哈希值进行加权计算,具体计算方法为:如果该位值为1,则结果为权重值,反之为0,则结果为权重的负值。
- 向量合并:将加权的哈希值进行合并,将每个位上的加权值相加,得到一个最终的
Simhash向量。 - 指纹压缩:根据
Simhash向量的每个位的加权和,将其转换为一个固定长度的二进制指纹。一般情况下,如果某个位的加权和大于0,则该位为1,否则为0。 - 距离计算:根据hamming距离,对得到的两个文本的二进制指纹进行异或运算,计算出hamming距离,得到相差度,再用1减去相差度,得到相似度。
其中,文本预处理与特征加权可以通过外部依赖库python jieba分词中的jieba.analyse同时实现
2. 计算模块接口部分的性能改进
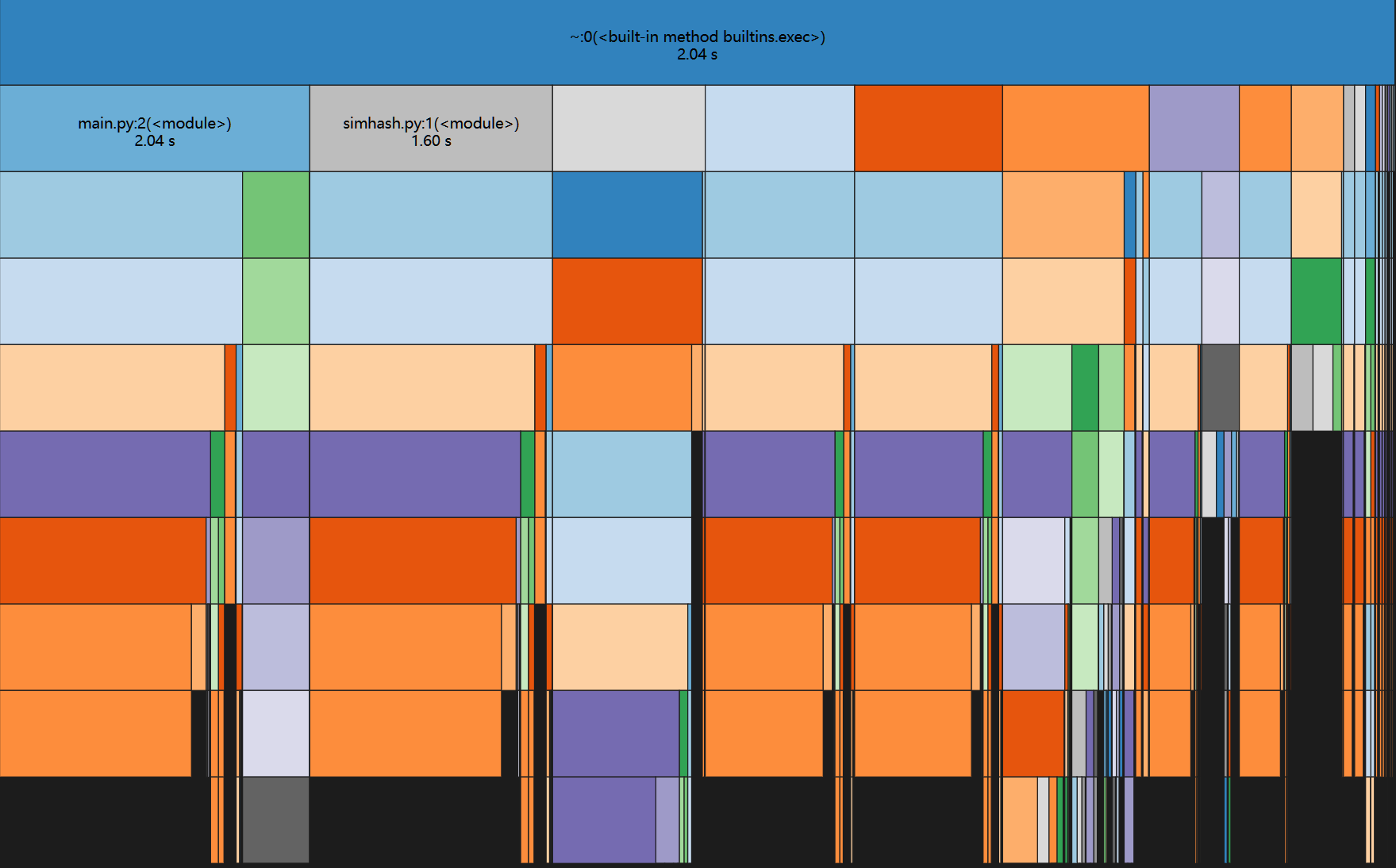
使用python cProfile进行运行时间查看

耗时最多的是载入nt.stat()与marshal.load()两个方法,以及加载jieba分词库与计算tfidf值
性能分析图:
3. 计算模块部分单元测试展示
以下是部分测试单元
class Testsimhash(unittest.TestCase):
#空文本
def test_empty(self):
sc = simhash.simhash_check('test\org_empty.txt','test\org_add_empty.txt') # noqa: E501
result = sc.check()
print('空文本:',result)
self.assertEqual(result,1)
#长文本、相似度高
def test_long_high(self):
sc = simhash.simhash_check('test\org_long_high.txt','test\org_add_long_high.txt') # noqa: E501
result = sc.check()
print('长文本高相似:',result)
self.assertTrue(result<100 and result>0)
#长文本低相似
def test_long_low(self):
sc = simhash.simhash_check('test\org_long_low.txt','test\org_add_long_low.txt') # noqa: E501
result = sc.check()
print('长文本低相似:',result)
self.assertTrue(result<100 and result>0)
#短文本高相似
def test_short_high(self):
sc = simhash.simhash_check('test\org_short_high.txt','test\org_add_short_high.txt') # noqa: E501
result = sc.check()
print('短文本高相似:',result)
self.assertTrue(result<100 and result>0)
#短文本低相似
def test_short_low(self):
sc = simhash.simhash_check('test\org_short_low.txt','test\org_add_short_low.txt') # noqa: E501
result = sc.check()
print('短文本低相似:',result)
self.assertTrue(result<100 and result>0)
if __name__ == '__main__':
unittest.main()
对于测试数据,设计了空文本、长文本且相似度高、长文本低相似、短文本高相似、短文本低相似以及中英文翻译文本
对应文件均放在项目的test文件夹中
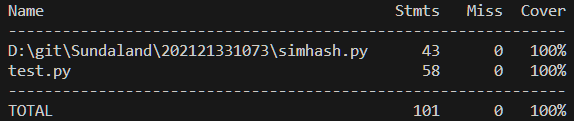
以下是测试代码代码覆盖率
4. 异常设置
-
检测命令行参数
if len(sys.argv) != 4: print("未输入完整文件路径") sys.exit(1) -
输入文件后缀
if (sys.argv[1].endswith(".txt") and sys.argv[2].endswith(".txt") and sys.argv[3].endswith(".txt")) is not True: # noqa: E501 print("输入文件中有非txt文件") sys.exit(1)测试用例
#检测命令行参数 异常 def test_error1(self): os.system('python D:\git\Sundaland\\202121331073\main.py') #输入文件后缀 异常2 def test_error2(self): os.system('python D:\git\Sundaland\\202121331073\main.py org.txt org_add.txt ans') # noqa: E501测试结果(包括其他单元测试)
Building prefix dict from the default dictionary ... Loading model from cache C:\Users\SUNDAL~1\AppData\Local\Temp\jieba.cache Loading model cost 0.476 seconds. Prefix dict has been built successfully. 中英文: 0.46875 .空文本: 1.0 .长文本高相似: 1.0 .长文本低相似: 0.453125 .常规1: 0.90625 .常规2: 0.8125 .常规3: 0.8125 .常规4: 0.890625 .短文本高相似: 0.78125 .短文本低相似: 0.484375 .未输入完整文件路径 .输入文件中有非txt文件 . ---------------------------------------------------------------------- Ran 12 tests in 3.360s
最后
simhash算法的简单实现,再特性提取时使用的是MD5哈希函数。实际上hashlib中的md5()函数返回的是长度为32位的16进制串,这里为方便计算取中间部分压缩成16位,从结果来看意外的还行。
it just works。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号