算法复杂度
算法和数据结构密不可分。算法依赖数据结构。
数据结构和算法解决是“如何让计算机更快时间、更省空间的解决问题”
因此从 执行时间 和 资源占用 两个维度来评估数据结构和算法的性能
也就是我们接下来讲的复杂度的问题,
时间维度 即是 时间复杂度;资源空间维度 就是 空间复杂度;
复杂度是描述了 执行时间或者资源空间与数据规模的关系
比如一段程序,我们如何估算这段代码的执行时间?
在这里,我们可以约定每一行代码的执行时间是一样的,我们约定为 单位时间 unit_time。
这样问题就可以转换为:程序总共执行了多少个单位时间。
先看下面这段代码,总共执行了多少个单位时间:
1 public static void F(int n)
2 {
3 int i_index = 0;
4 int j_todo = 0;
5 for (; i_index < n; i_index++)
6 {
7 j_todo = i_index;
8 Console.WriteLine($"业务调用次数 :{j_todo + 1}");
9 Console.Write($"循环次数 :{i_index + 1}");
10 }
11 }
第 3 行,一个单位是时间 =1 unit_time
第 4 行,也是一个执行单位时间 =1 unit_time
第 5 行,根据n的大小,所以会执行 n次 =n unit_time
同样第 7 ,8 , 9 这三行都会执行 n次 = ( n + n + n ) unit_time
所以 以上这个方法内部的算法执行时间是:T=1+1+n+3n = 4n+2;
T = 4n+2 是算法的执行时间,所以我们可以看出T和n成正比。
我们再来看一下一个嵌套循环的时间复杂度:
1 public static void F2(int n)
2 {
3 int i_index = 0;
4 for (; i_index < n; i_index++)
5 {
6 int j_todo = 0;
7 for (; j_todo < n; j_todo++)
8 {
9 Console.WriteLine($"业务调用次数 :{j_todo + 1}");
10 }
11 Console.Write($"循环次数 :{i_index + 1}");
12 }
13 }
第3行 = 1 unit
第4行 = n unit
第6行 = n unit
第7行 = n * n
第9行 = n * n
第10行= n
T = 3n + 2*n^2
其实我们也已经看到,执行时间T 和 n 执行次数的数量级成正比,
这里就引出了一个公式:T(n) = O(f(n))
T(n) 代码在数量级n规模下的执行时间;
f(n) 每行代码执行次数总和
O 即为 T(n) 和 f(n) 成正比关系
上面的例1:T = 4n+2 ,大O表示法为 T(n) = O(4n+2)
例2:T = 3n + 2*n^2 , 大O表示法为 T(n) = O(3n + 2*n^2)
通过以上例子我们可以知道,当n很大时,常量,系数,低阶这些对趋势影响极小,也就是我们找到影响面最大的因子
对案例1来说,去除常量和系数,影响最大因子就是n,即可表示为 T(n)=O(n)
案例2来说,同样去除影响面较小的因子,可表示为 T(n)=O(n^2)
我们可以总结为:去除影响趋势较小的因子,保留影响趋势最大的因子
1)单段代码看高频:比如循环。
2)嵌套代码求乘积:比如递归、多重循环等
3)多段代码取最大:比如一段代码中有单循环和多重循环,那么取多重循环的复杂度。
4)多个规模求加法:比如方法有两个参数控制两个循环的次数,那么这时就取二者复杂度相加。
我们常见的或者常听到的复杂度级别比如:
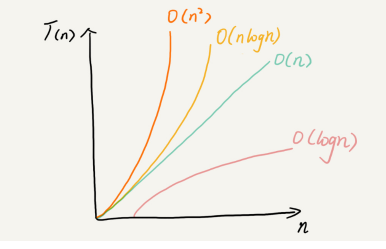
O(1) 常量阶
1不是代表的代码行数,这是对执行次数为固定常量的统称。
以下FormatWriteLineMsg函数只是一个格式化展示的函数
1 public static void N1(int n) 2 { 3 int i_index = 0; 4 Console.WriteLine($"时间复杂度-常量阶-i :{i_index + 1}"); 5 }
1 int n = 10; 2 3 FormatWriteLineMsg("时间复杂度-常量阶: O(1)"); 4 N1(n);

O(n) 线性阶
我们刚才案例1已经提到过,成正比关系。
1 public static void N(int n) 2 { 3 int i_index = 0; 4 5 for (; i_index < n; i_index++) 6 { 7 Console.WriteLine($"时间复杂度-线性阶-i :{i_index + 1}"); 8 } 9 }
1 int n = 10; 2 3 FormatWriteLineMsg("时间复杂度-线性阶: O(n)"); 4 N(n);
O(n^k) 次方阶
案例2也是平方阶,当然还有给根据嵌套的层数对应的k的增加。
1 public static void NxN(int n) 2 { 3 int i_index = 0; 4 for (; i_index < n; i_index++) 5 { 6 int j_todo = 0; 7 for (; j_todo < n; j_todo++) 8 { 9 Console.WriteLine($"时间复杂度-X方阶 :i*j ={i_index + 1} *{j_todo + 1}"); 10 } 11 } 12 }
1 int n = 10; 2 3 FormatWriteLineMsg("时间复杂度-X方阶: O(n^x)"); 4 NxN(n);
......
O(m+n)、O(m*n)
复杂度与两个数据资源有关
O(log n) 对数阶
1 public static void LogN(int n) 2 { 3 double flag = 1; 4 double step = 2; 5 int forCount = 0; 6 while (flag <= n) 7 { 8 forCount++; 9 flag = flag * step; 10 Console.WriteLine($"时间复杂度-对数阶:{forCount} ==> {step}^{Math.Log(flag, step)}"); 11 } 12 }
1 int n = 10; 2 3 FormatWriteLineMsg("时间复杂度-对数阶: O(log n)"); 4 LogN(n);

循环最多的代码是 第6、8、9、10行,我们看一下它们执行了多少次:
次数 => 1 2 3 4
flag => 1*2 2*2 4*2 8*2
n => 2^1 2^2 2^3 2^4
所以 对于n来说,n=2^x,执行了x次。x=log2n,时间复杂度为 O( log2n ).
我i什么会将这些对数同意规整为 logn?--忽略对数的底,即为 O( logn )
空间复杂度
算法的存储空间与数据规模之间的增长关系
通常空间复杂度级别:O(1) O(n) O(n^2)
一般分析到这已经可以应对我们平时的开发需求,因为下面的很多的概念思想可以借鉴。也是很多的开源工具框架运用了其中的一些算法的精髓。
所以我们有必要再对算法复杂度深入一下,那么接下来我们再进一步了解一下几个概念:
最坏情况时间复杂度、最好情况时间复杂度 、平均情况时间复杂度、均摊时间复杂度
来看一下下面这一段代码:查找某个元素,找到就结束返回索引,没找到为-1。
1 string source = "8,4,5,6,2,3,1,9,0,7";
2 string[] data = source.Split(',').ToArray();
3 Console.WriteLine($"Source ={source} | find =>{search}");
4 Console.WriteLine();
5
6 int count = data.Count();
7 int search_index = -1;
8
9 int i_index = 0;
10 for (; i_index < count; i_index++)
11 {
12 Console.WriteLine($"todo:{i_index + 1}");
13 if (search == data[i_index])
14 {
15 search_index = i_index;
16 break;
17 }
18 }
这就会出现多种情况:
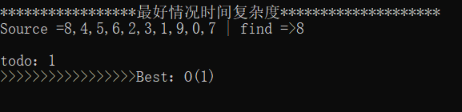
1、比如上来第一个就找到了,那么时间复杂度为O(1),因为只循环了一次就找到了;
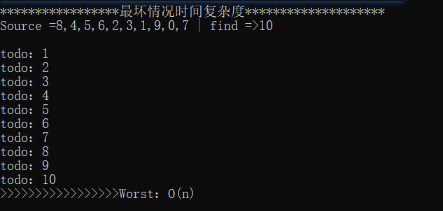
2、运气较差最有一个找到了,时间复杂度为O(n);
3、那么在第二个,第三个,第n个找到呢 ?
4、找遍所有还是没有找到,那么这个时间复杂度仍为 O(n);
第1、2、4 只是一种特殊情况,我们很多情况会是3.
当然,第1就是我们上面提到的 最好情况时间复杂度=O(1);
第2、4 就是最坏情况时间复杂度 = O(n);
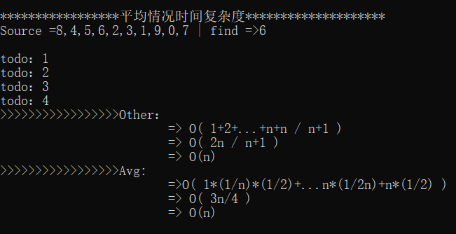
我们接下来所分析的就是 第3,平均情况时间复杂度:
- 所有发生的情况为 n +1 (n内找到+没找到)
- 概率,对于每一次查找 是的概率为 1/2
- 对于n+1种情况来说,n内找到的概率为 1/n
1+2+3...+n+n / n+1 => + 概率 => 1*(1/2n)+2*(1/2n)+3*(1/2n)...+n*(1/2n)+n*1/2 => 3n+1 / 4
所以 平均时间复杂度为 O(n)
Demo


1 public static void Best_Worst_Avg_CaseTime(string search)
2 {
3 string source = "8,4,5,6,2,3,1,9,0,7";
4 string[] data = source.Split(',').ToArray();
5 Console.WriteLine($"Source ={source} | find =>{search}");
6 Console.WriteLine();
7
8 int count = data.Count();
9 int search_index = -1;
10
11 int i_index = 0;
12 for (; i_index < count; i_index++)
13 {
14 Console.WriteLine($"todo:{i_index + 1}");
15 if (search == data[i_index])
16 {
17 search_index = i_index;
18 break;
19 }
20 }
21
22 if (i_index == 0)
23 {
24 Console.WriteLine($">>>>>>>>>>>>>>>>>Best:O(1)");
25 Console.WriteLine();
26 }
27 else
28 {
29 if (search_index == -1)
30 {
31 Console.WriteLine($">>>>>>>>>>>>>>>>>Worst:O(n)");
32 Console.WriteLine();
33 }
34 else
35 {
36 Console.WriteLine($@">>>>>>>>>>>>>>>>>Other:
37 => O( 1+2+...+n+n / n+1 )
38 => O( 2n / n+1 )
39 => O(n)");
40
41 Console.WriteLine($@">>>>>>>>>>>>>>>>>Avg:
42 =>O( 1*(1/n)*(1/2)+...n*(1/2n)+n*(1/2) )
43 => O( 3n/4 )
44 => O(n)");
45 Console.WriteLine();
46 }
47 }
48
49 }
50
1 FormatWriteLineMsg("最好情况时间复杂度");
2 string best = "8";
3 Best_Worst_Avg_CaseTime(best);
4
5 FormatWriteLineMsg("最坏情况时间复杂度");
6 string worst = "10";
7 Best_Worst_Avg_CaseTime(worst);
8
9 FormatWriteLineMsg("平均情况时间复杂度");
10 string avg = "6";
11 Best_Worst_Avg_CaseTime(avg);
12
13 Console.ReadKey();
均摊情况时间复杂度,其实是一种更加特殊的平均情况时间复杂度,
均摊也是存在复杂度级别的差距,但是级别较高的复杂度会被平摊到级别较低的复杂度执行中去。这样来看算法复杂度进行了均摊。Redis很多场景都使用了这种思想。
平均情况算法复杂度,代码在不同的情况下有不同的复杂度级别,参考相关发生的概率,进行平均计算。
至于平均和均摊的复杂度来说,哪种情况出现的可能性比较多,那么他的复杂度越是趋近于这种复杂度。
以上的四个复杂度概念,平时见的不多,但是很多的流行的开源工具框架,很多都有这种思想在里面。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号