【nfs-ganesha】gansha关于mdcache代码分析
MDCACHE_BYPASS_DIRCACHE标记目前只有在没有开启chunk的情况下,如果目录过大,会打上此标记,不会被缓存,开启了chunk,此标记永远失效。除了这两行之外,后面的操作是在没有开启chunk的情况下的流程,暂时不做分析。所以mdcache_readdir其实是执行了mdcache_readdir_chunked函数。
mdcache_readdir_chunked的流程如下:
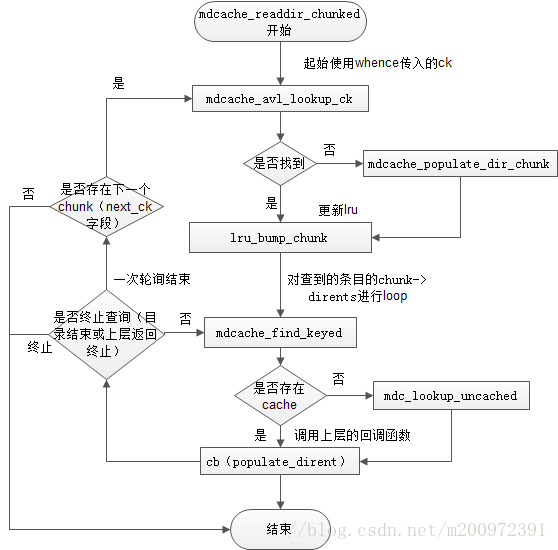
还是和lookup一样,我们先看没有找到的流程。
2.1 mdcache_populate_dir_chunk
流程如下:
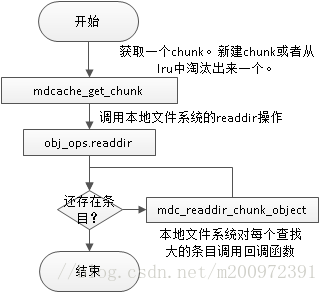
做了3件事情:
1、mdcache_get_chunk。
2、调用本地的readdir操作。
3、本地的readdir调用回调函数mdc_readdir_chunk_object。
2.1.1 mdcache_get_chunk
这个函数是获取一个可用的chunk,如果全局的chunk数达到了阈值,就从lru中淘汰出一个。
2.1.2 调用本地的readdir操作
本地读取数据
2.1.3 本地每读取一个数据,调用一次mdc_readdir_chunk_object回调函数,我们照常看看mdc_readdir_chunk_object的流程
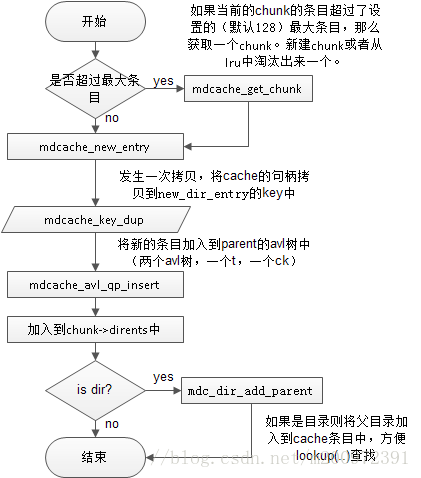
其实可以发现,很多事情和lookup类似的。与lookup不同的是,lookup如果没有找到,会将chunk置无效(compute_readdir_cookie没有实现的情况下,如果实现了,会加入chunk中),而在这里,chunk的结构体中,存在一个dirents参数,这里保存这个chunk的所有文件的链表。
2.2 mdcache_avl_lookup_ck
现在我们回头看看直接在cache中找的函数,其实就是遍历ck的过程。在mdcache_entry_t结构体中,存在一个 first_ck的字段,作为一个目录ck的初始值,每个chunk中存这next_ck的字段,就可以进行ck的遍历操作。
2.3 chunk->dirents的loop操作
针对每个ck查找到的chunk,对chunk->dirents 的loop操作,对每个cache条目,调用上层的回调函数,已完成readdir的操作。
项目中使用了ganesha-nfs,之前使用了nfs-ganesha的2.3.3版本, 但是貌似cache中出现了一些问题,而2.4以后的版本重构了inode cache模块,导致只能自己分析源码,解决部分bug(其实大部分问题起始在2.5.4的稳定版本之后已经修复)。
mdcache在2.4.0之后放在了FSAL层,对应的目录为src\FSAL\Stackable_FSALs\FSAL_MDCACHE下。
我们从lookup和readdir的流程来分析mdcache是怎么工作的。
项目中使用了ganesha-nfs,之前使用了nfs-ganesha的2.3.3版本, 但是貌似cache中出现了一些问题,而2.4以后的版本重构了inode cache模块,导致只能自己分析源码,解决部分bug(其实大部分问题起始在2.5.4的稳定版本之后已经修复)。
mdcache在2.4.0之后放在了FSAL层,对应的目录为src\FSAL\Stackable_FSALs\FSAL_MDCACHE下。
我们从lookup和readdir的流程来分析mdcache是怎么工作的。
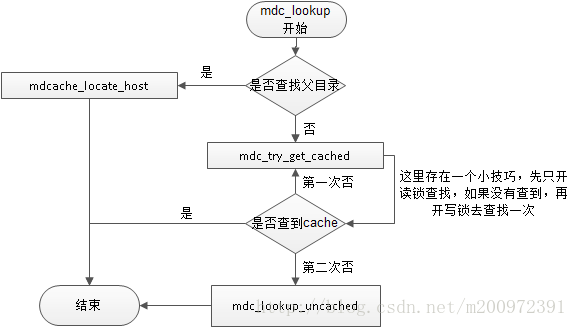
函数定义如下:
fsal_status_t mdc_lookup(mdcache_entry_t *mdc_parent, const char *name, bool uncached, mdcache_entry_t **new_entry, struct attrlist *attrs_out)
先看看mdcache_entry_t这个结构体,现在暂时先不展开结构体讨论。mdcache_entry_t结构体是一个对象(文件/目录等)cache的实体,mdc_parent是父目录存在于cache中的cache实例。 mdcache_entry->fsobj.fsdir.parent保存了父目录的信息,如果是查找父目录的话,直接调用mdcache_locate_host将mdcache_entry->fsobj.fsdir.parent转化为父目录的mdcache_entry_t条目返回即可。
接下来调用mdc_try_get_cached,通过mdc_parent和name查找cache,如果不存在的话,我们调用mdc_lookup_uncached。
1.1 先看 mdc_lookup_uncached函数,了解元数据怎么加入cache中之后,就会理解怎么查找。
流程如下:
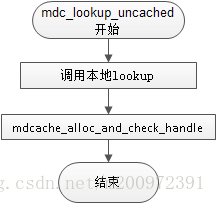
在调用了本地文件系统的lookup之后,进行cache的创建操作,这里主要看mdcache_alloc_and_check_handle流程:
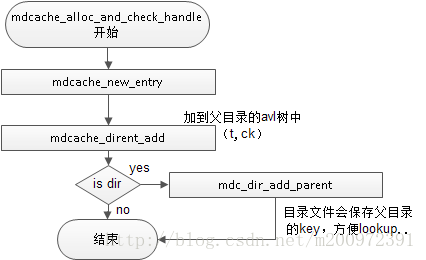

看流程比较清晰,做三个事情:
1、新建条目。
2、增加到父目录的avl树中。
3、针对目录保存父目录的key。
下面分别将这三件事情做了什么详细说明:
1.1.1 新建条目
这个是最复杂的事情,首先还是照常先看流程图:
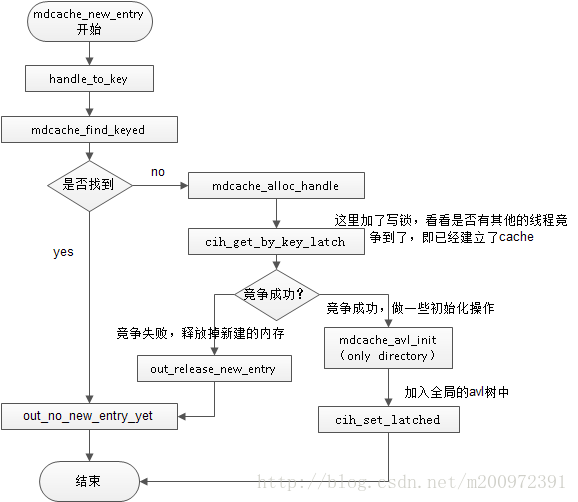
这里着重讨论新建部分,主要是针对目录的avl树的初始化,以及加入到全局的avl树中。
对于目录来说,会初始化它子目录的avl树,以缓存所有的子目录和文件。下面是 mdcache_entry->fsobj.fsdir.avl的结构的定义。
struct {
/*目录下条目的avl树*/
struct avltree t;
/*删除条目的avl树*/
struct avltree c;
/** FSAL的cookie的构成的avl树 */
struct avltree ck;
/**排序的avl树 需要支持fso_compute_readdir_cookie, 暂时不分析*/
struct avltree sorted;
/** 冲突标记0,暂时不知道搞什么飞机的东西. */
uint32_t collisions;
} avl;
主要是两棵树,t 和 ck,t保存以文件名的hash值作为比较值的avl树,可以用来查找某个文件,而ck则构建的以子文件或目录在文件夹中的offset为比较值的avl树,主要用来列举目录的所有或部分条目。
主要对这几个树进行初始化。
然后加入到全局的avl树(key的hash值作为avl树的比较值)中。
struct cih_lookup_table结构体保存的全局的cache,默认有7个分区(配置文件中Nparts设置),每个分区存在一个avl树,而且每个分区有cache字段,直接cache了32633个cache条目。全局cache查找策略是,通过key的hash直接查找,如果在cache没有查到,才到avl树中找,找到了之后替换掉cache。
1.1.2 增加到父目录的avl树中
主要做到是事情是新建一个mdcache_dir_entry_t条目,将其加入到的avl树(t, ck)中。
1.1.3 针对目录保存父目录的key
这里在上面提过,如果查找到的是目录,需要将父目录的key赋值给目录cache条目的 fsobj.fsdir.parent字段,方便lookup..的查找。
1.2 mdc_try_get_cached存在cache的流程
主要是在parent的avl树t中查找,如果查到了,在全局的avl树中确认存在,即返回。
1.3 cache每个avl树的作用的简单总结
1.3.1 全局avl树的作用
通过key快速查询mdcache_entry_t条目信息。
1.3.2 目录avl树中的t
查找子文件或者目录时使用。
1.3.3 目录avl树中的ck
主要是readdir使用,之后第二节将readdir的流程会详细说明。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号