【linux编程】字节序
字节序
与同一台计算机上的进程进行通信时,一般不用考虑字节序,字节序是一个处理器架构特性,用于指示像整数计算的大数据类型内部的字节如何排序。
假设上图图 中在内存 0x1000 到 0x1003 这连续的 4 个字节保存了数据,这段数据对应的数据类型是 int 类型。我们知道 int 类型的数据在大多数编译器实现中都是 4 字节。
那么上图这个 int 类型数据,到底是 0x10203040 还是 0x40302010?实际上这是依赖于处理器架构的。
对于 little-endian (小端)机器来说,这 4 字节数据被解释成 int 类型的话它就是 0x10203040,对于 big-endian (大端)机器来说,它被解释成 0x40302010.
按照这个规则,对于小端机器来说,高地址 0x1003 这个位置保存的是数据最高位,0x1000 这个地址保存的是数据的最低位,所以最终的 int 类型数据就是 0x10203040.
数据在内存中的存放方式似乎和我们想象的顺序不太一样,在我们的常规认知不一样,在我们的常规认知中,它的存放方式应该是00 00 00 01,那造成这个的原因是什么呢?
因为C语言在内存中存放数据时采用了两种存储模式,大端存储和小端存储。

在小端存储模式中最低位字节中存放的为01,大端存储模式中放的为00,于是我们可以想到通过强制转换的方法,将一个四个字节的整型数据截断为一个字节的字符型数据,即可得到这个低位的数据,再进行判断,如果为1则说明该机器为小端存储模式,如果为0则说明为大端存储模式
int main()
{
int i = 1;
char ch = (char)i;
if (ch == 0)
printf("大端存储\n");
else if (ch == 1)
printf("小端存储\n");
return 0;
}注意:大部分情况下,我们的使用都是小端机器,Intel 处理器和 AMD 处理器基本上都是小端的。但是也有一些处理器是大端的。TCP协议栈使用大端字节序(网络字节序)。
对于TCP/IP应用程序,有4个用来在处理字节序和网络字节序之间实施转换的函数。
#include <arpa/inet.h>
uint32_t htonl(uint32_t hostlong); // 返回值:以网络字节序表示的32位整数
uint16_t htons(uint16_t hostshort); // 返回值:以网路字节序表表示16位整数
uint32_t ntohl(uint32_t netlong); // 返回值:以主机字节序表示的32位整数
uint16_t ntohs(uint16_t netshort); //返回值:以主机字节序表示16位整数
例1:
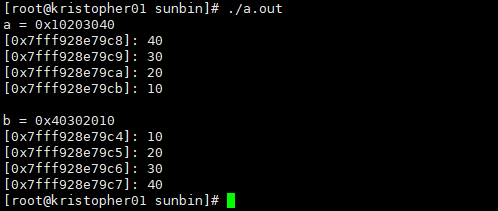
1 #include <stdio.h> 2 #include <arpa/inet.h> 3 4 union Int 5 { 6 char data[4]; 7 int x; 8 }; 9 10 int main() 11 { 12 int i; 13 union Int a; 14 union Int b; 15 a.x = 0x10203040; 16 b.x = htonl(a.x); 17 18 printf("a = 0x%08x\n", a.x); 19 for (i = 0; i < 4; ++i) 20 { 21 printf("[%p]: %02x\n", a.data + i, a.data[i]); 22 } 23 puts(""); 24 25 printf("b = 0x%08x\n", b.x); 26 for (i = 0; i < 4; ++i) 27 { 28 printf("[%p]: %02x\n", b.data + i, b.data[i]); 29 } 30 return 0; 31 }
输出:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号