常用排序算法(冒泡排序,选择排序,插入排序,希尔排序,快速排序) 分析和java简单实现
文章总结了几种常用排序算法: 冒泡排序,选择排序,插入排序,希尔排序,快速排序。
假设有一队棒球队员 如图3.1,3.2,需要对棒球队员进行排序:
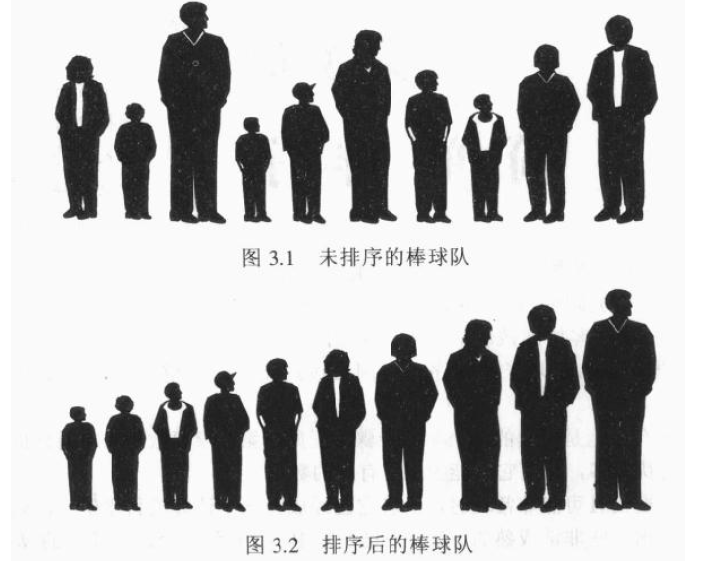
我们知道计算机不能像人一样通揽所有棒球队员。计算机只能在同一时间内对两个队员进行比较,因此计算机只能一步步解决具体问题和遵循一些简单的规则。该文中所有排序算法都将包括如下两个步骤,这两个步骤循环执行,直到全部数据有序为止。
1) 比较两个数据项
2) 交换两个数据项或复制其中一项
但是,每种排序算法实现的具体细节不同。
1. 冒泡排序:
冒泡排序运行起来非常慢,但在概念上,它是排序算法中最简单的。
使用冒泡排序对棒球队员排序:
冒泡排序过程如下: 假设有N个队员,并且从左往右对这N个队员编上号 0到 N-1 。 从队伍的最左边开始,比较第0个位置和第1个位置的队员的身高,如果0号位置队员身高大于1号位置队员身高,那么交换0号位置和1号位置的队员,如果0号位置队员身高小于1号位置队员的身高,那么什么也不做。然后右移一个位置,比较1号位置队员和2号位置队员的身高,和刚才一样如果左边队员身高高则交换两个队员的位置。这个排序过程如图3.3所示。
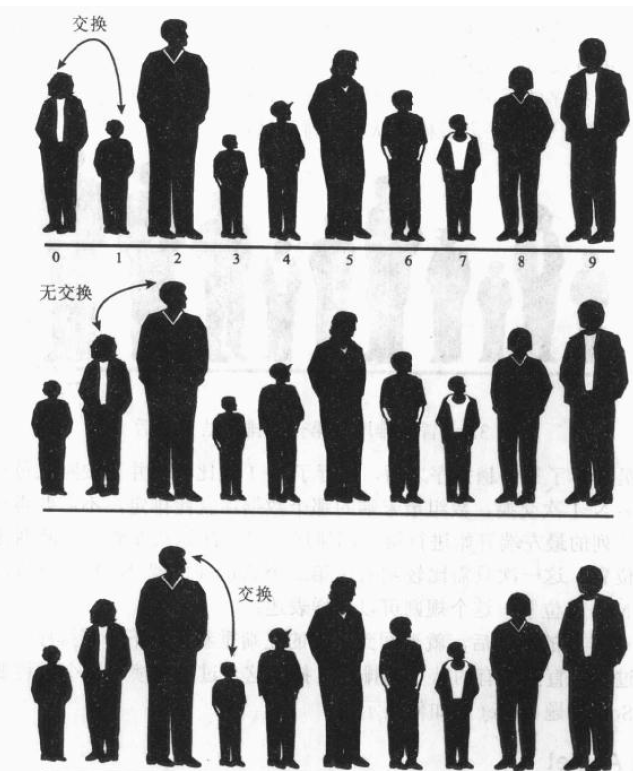

以下是要遵循的规则:
1. 比较两个队员
2. 如果左边的队员高 ,则两个队员交换位置
3. 向右移动一个位置,比较下两个队员
沿着这个队列照着刚才的方法比较下去,一直比较到队列的最右端,虽然整个队列并没有完全排好序,但最高的队员已经排在了队列的最右端。 这个是确定的,因为比较两个队员,只要遇到最高的队员就会交换他两个的位置,这样最高的队员一直到达队列的最右端 。这也是这个算法被称为冒泡算法的原因 ,因为最大的数据项总是冒泡到队列的最顶端。
图3.4表示了再第一趟排序后棒球队员的排列情况:

再对所有队员进行了第一趟排序之后,进行了N-1次的比较和最多N-1次 最少0次的交换。队列最右端的数据项至此已排好序,不需要再变动了。现在从回到对列最左边开始第二趟的排序,第二趟排序也是两两比较,再适当的时候交换两队员位置,这次只需比较到右侧第二个队员(N-2)位置,因为最高的队员已经占据了最右端的位置,即N-1号位置有已经排好序的队员。这个规则可以这样描述:
当碰到第一个已排好序的队员后,返回最左端进行新一轮的排序,直到所有队员都排序完成。
描述这个过程比演示这个过程的代码困难的多 ,以下是冒泡排序代码层面的简单实现 :
void maopaoSort(int[] a){
int in,out;//定义内层循环和外层循环
for(out=a.length()-1;out>0;out--){
for(in=0;in<out;in++){
if(a[in]>=a[in+1]){
int temp=a[in];
a[in]=a[in+1] ;
a[in+1]=temp;
}
}
}
}
这个算法的思路是定义外层循环和内层循环,外层循环从数组的最后开始,每循环完一次减一,下标大于out的数据都已经是排好序的了。 内循环从队列最左边开始,比较下标未in和in+1的数据,如果满足条件则交换,当内循环in等于out时则结束一次内循环。
冒泡排序的效率是O(N²) 级别的,比较次数和交换次数都是O(N²) 级别的
2. 选择排序
选择排序改进了冒泡排序 将必要的交换次数从O(N²)降低成了O(N),但不幸的是选择排序算法的比较次数仍是O(N²)。
使用选择排序对棒球队员排序:
让我们再来考虑棒球队员排序的问题。在选择排序中不再只比较两个相邻的球员,因此需要记录下某一个指定球员的高度;可以用记事本写下指定球员的身高,同时还需要准备一条红色的毛巾。
简述:
选择排序就是把所有队员都扫描一遍,从中挑出(或者是选择出,这就是选择排序名字的由来)最矮的一个队员。最矮的这个队员和站在队列最左边即0号位置的队员交换位置,现在最左端的球员是有序的了,不需要再交换位置了。 注意,这个算法中 有序的队员都是站在队列最左边(下标较小的位置),而冒泡排序有序的队员则是站在队列最右边。 再次扫描球队队列时就把最矮的球员和1号位置球员交换,重复这个过程,直到所有队员都已排好序。
更详细的描述:
排序的球员从最左边开始,在记录本上记录最左端球员的身高,并把红色毛巾放在这个队员的前边。于是开始用下个球员的身高和记录本上记录的值比较。如果这个球员更矮则记录本上划掉第一个球员的身高,并记录下这个球员的身高;同时移动毛巾,把它放在这个新的最矮的(当前)队员前边。继续沿着队列走下去,每一个球员都和记录本上的最小值比较,当发现更小的队员时候,就更新记录本上的最小值并移动毛巾。 第一轮比较找到这一轮的最矮的队员,这个最矮队员和最左边队员交换位置。现在已经对一个队员排好序了,这期间做了N-1次比较,但却只交换了1次。
在下一趟排序中所做的事情是一模一样的。只要完全忽略最左边队员的存在,因为他已经排好序了。 因此算法排序从第1个位置开始,而不是从第0个位置开始,没进行完一趟排序,就多了一个有序的队员,并被安排在左边,下次再找新的最小值的时候就可以少考虑一个队员。图3.9显示了这种排序的前三趟过程。
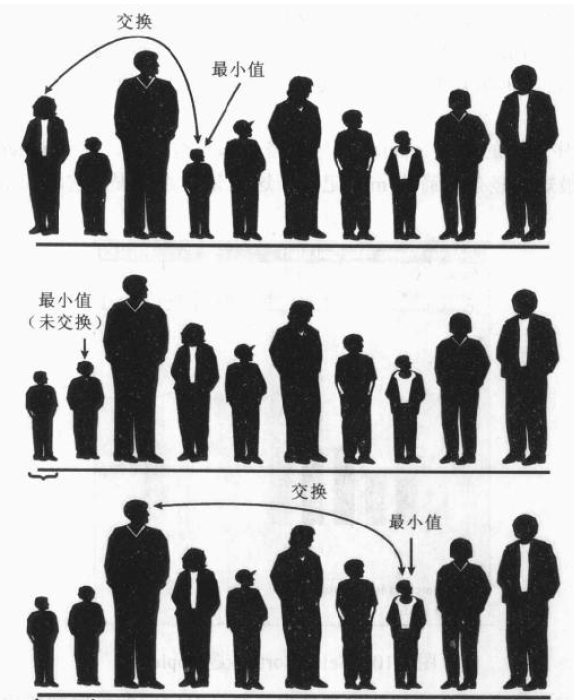

选择排序简单实现如下:
public static void selectSort(int[] a) {
int out;//定义外循环
int in;//定义内循环
int min;//最小值
//这里out<a.length-1是因为如果只剩最后一个元素,那肯定是最大的了 就不需要再来一轮排序了
for(out=0;out<a.length-1;out++) {
min=out; //未排序的左边第一个值赋给最小值(记录本上记录最小值)
for(in=out+1; in<a.length;in++) {
if(a[in]<=a[min])
min=in;
}
int temp=a[out];
a[out]=a[min];
a[min]=temp;
}
}
3. 插入排序
一般情况下插入排序比冒泡排序要快一倍 ,比选择排序还要快一些,尽管它比冒泡排序和选择排序的算法都麻烦一些,但也并不复杂。它经常被用在较复杂排序算法的最后阶段,例如快速排序
用插入排序算法对棒球队员排序:
开始插入排序之前把棒球队员随机排成一列,从排序过程的中间开始,可以更好的理解插入排序,这时,队列已经排好了一半。
局部有序:
此时在队伍中间有一个做为标记的队员(可以把一条红色的运动衫扔到这个队员前面)。在这个标记的运动员左边已经局部有序了,然而这些运动员在队伍的最终位置还没有确定,因为当没有排过顺序的运动员插入到他们中间的时候,他们的位置还要变动。 注意:局部有序再冒泡和选择排序中是不会出现的,因为在这两个算法中一组数据在某个时刻是完全有序的;在插入排序中一组数据仅仅是局部有序。
被标记的队员:
作为标记的队员称为“被标记”的队员 他和他右边所有的队员都是未排过序的。如图3.11.a
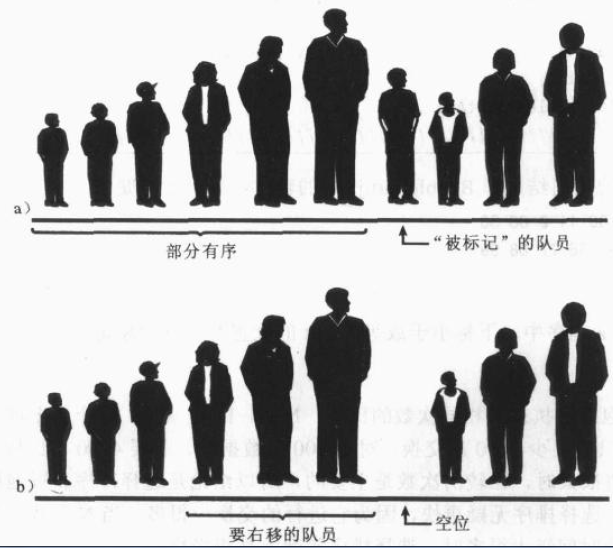
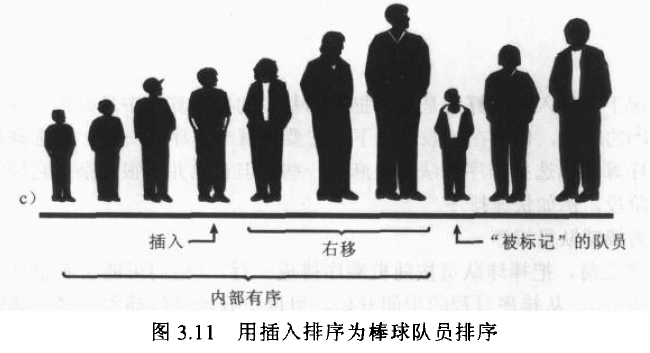
下边要做的是在局部有序中的适当位置插入被标记的棒球队员。 然而要做得到这一点需要把局部有序的球员右移,腾出空间。为了提供移送所需要的空间,可以让被标记的队员出列(在程序中将这个被标记的队员存储在临时变量中),这个步骤如图3.11.b
现在移动已经排过序的队员来腾出空间。将局部有序中的最高队员移动到被标记的位置,次高队员移动到原来最高队员的位置,以此类推。
这个移动过程什么时候结束呢?假设你和被标记的球员一起向球队的左侧移动,在每个位置上,队员都向右移动一位,同时被标记的球员和下一个要移动的球员比较身高。当把最后一个比标记队员还高的队员移动之后,这个移动过程就停止了。最后一次移位后空出来的位置就是这个被标记球员应该插入的位置。这个步骤如图3.11.c
现在局部有序的队员里多了一个队员。而未排序的队员里少了一个队员,作为标记的运动衫向右移动一个位置,它仍然在未排序的部分队员的最左边的队员的前面。 重复这个过程 ,直到所有未排序的队员都插入(这就是插入排序名字的由来)到局部有序队列里。
下面是插入排序简单实现代码:
public static void insertSort(int[] a) {
int out;//定义外循环
int in;//定义内循环
//外循环从1开始是把最左边0位置的元素看成是局部有序的。 1位置为被标记的元素
for(out=1;out<a.length;out++) {
//让被标记位置的元素出列
int temp=a[out];
in=out;//in 相当于红色运动衫
while(in>0&&a[in-1]>=temp) {//循环比较局部有序的队员和出列的队员,直到最后一个比标记队员高的队员移位
a[in]=a[in-1];
in--;
}
a[in]=temp;
}
}
4. 希尔排序
希尔排序是基于插入排序算法的,回想一下在插入排序执行一半的时候,标记符左边这些数据项都是排过序的,而标记右边的数据项都没排过序,这个算法取出标记符所指的数据项,把它存储在一个临时变量里,接着,从刚刚被移除的数据项左边第一个数据项开始,每次把有序的数据项往右移动一个单元,直到被标记的数据项找到合适位置回插。
下面是插入排序带来的问题:
假设一个很小的数据项在很靠近右端的位置上,这里本来应该是值比较大的数据项所在的位置,把这个小数据项移动到左边正确的位置上,所有的中间数据项都必须右移一位。这个步骤对每个数据项都执行了 将近N次的复制。虽然不是所有数据项都必须移动N个位置,但是数据项平均移动了N/2个位置,这就执行了N次N/2个移位,总共是N*N/2次复制,因此插入排序的效率是O(N²)
如果能有某种方式不必一个一个的移动中间数据项,就能把较小的数据项移动到左边,那么这个算法的执行效率就会有很大的改观。
n-增量排序:
希尔排序通过加大插入排序中元素之间的间隔,并在这些有间隔的元素中进行插入排序,从而使得数据项能够大幅度的移动 。这些数据项排过一趟后,希尔排序减小数据项的间隔再进行下一次排序,依此进行下去。进行这些排序时候,数据项之间的间隔称为增量,并且习惯上有字母h表示。图7.1显示了增量为4时对包含10个数据项的数组进行排序的第一个步骤的情况。在0,4,8位置上的数据已经有序了。
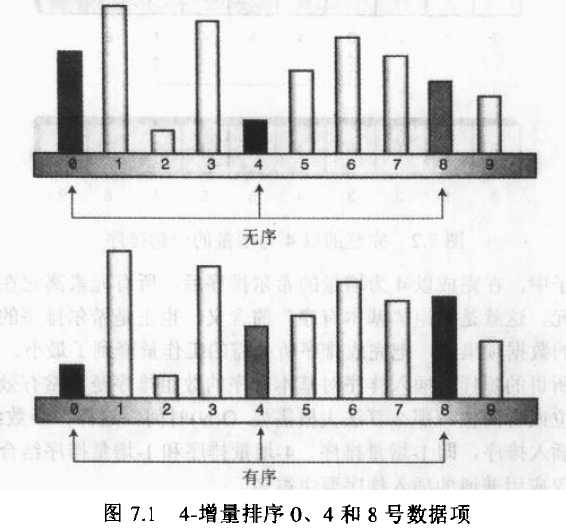
当对0,4,8号数据项完成排序之后,算法向右移动一位,对1,5,9位置排序。这个排序过程持续进行,直到所有的数据项都已完成了4增量排序。 也就是说所有间隔为4的数据项都已经有序了。这个过程如图7.2所示。

在完成以4为增量的希尔排序后,数组可以看出由4个子数组组成(0,4,8),(1,5,9),(2,6),(3,7) 这4个子数组分别是完全有序的。注意现在所有元素距离最终有序序列中的位置相差都不到两个单元。这就是数值基本有序的含义,也正是希尔排序的奥秘所在。通过创建这种交错的内部有序的数据项集合,把完成排序所必需的的工作量降到了最小。
正如插入排序所讲的那样,插入排序对基本很有序的数组排序是非常有效的,如果插入排序只需要把数据项移动1位或者2位,那算法大概需要O(N)的时间,当数组完成4增量排序以后,可以进行普通的插入排序,即1增量排序,4增量排序与1增量排序配合起来使用,效率会高的多。
减小间隔:
上边已经演示了以4为初始间隔对10个数据项进行排序的情况。对于更大的数组,开始间隔也应该更大,最后间隔减小到1 。
举个例子来说,比如有1000个数据项,可能先以364为增量,然后以121为增量,然后40为增量,然后以13为增量,然后4为增量,然后1为增量。 用来形成间隔的数列(在本例中为364,121,40,13,4,1)被称为间隔数列。这里所表示的间隔数列由Knuth提出,此数列是很常用的。数列以逆向形式从1开始,通过递归表达式h=3*h+1 产生。 初始值为1。 表7.1的前两栏显示了这个公式的产生序列。
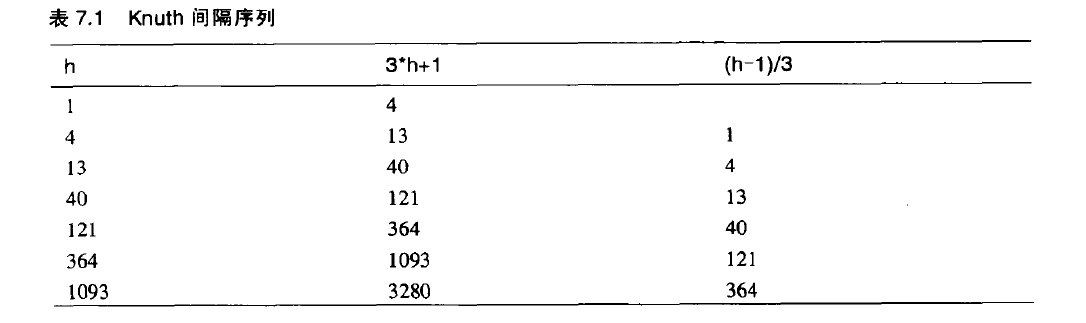
在希尔排序算法代码中 ,首先在一个短小的循环中使用公式生成最初的间距。h值最初被赋为1 ,然后根据公式h=3*h+1生成序列1,4,13,40,121,364 等等,间隔大于这个数组的长度时候这个过程停止。 对于一个含有1000个数据项的数组,序列的第七个数字1093就太大了,因此使用序列的第六个数字来开始这个排序过程,即以364增量排序。然后,没完成一次增量排序的外部循环,用前面提供的此公式的倒推式子(h=(h-1)/3),来减小间距进行下一轮排序,当间距减小到1,数组用1增量排序后,算法结束。
希尔排序算法java简单实现如下:
public static void shellSort(int[] a) {
int out;//定义外循环
int in;//定义内循环
int temp;
int h=1;
//while(h<a.length/3 ) 保证h不超过数组长度
while(h<a.length/3 ) {
h=3*h+1;
}
while(h>0) {
for(out=h;out<a.length;out++) {
temp=a[out];//被标记的数据出列
in=out;
while(in-h>=0 && a[in-h]>=temp) {
a[in]=a[in-h];
in-=h;
}
a[in]=temp;
}
h=(h-1)/3;
}
}
5. 快速排序
毫无疑问,快速排序是最流行的排序算法,大多数情况下,快排都是最快的。 为了理解快速排序,现需要理解一下划分算法。
划分
划分数据就是把数据分为两组,使得所有关键字大于特定值的数据项在一组,所有关键字小于特定值的数据项在另一组。
很容易想象划分数据的情况。比如可以将职员记录分为两组,一组是离家2公里内的,一组是离家2公里外的。
来看下划分算法的一种代码实现:
public static int partition(int[] a) {
int pivot=8;//定义划分值
int leftPre=-1;
int rightPre=a.length;
int temp;
while(true) {
while(leftPre<a.length-1 && a[++leftPre]<pivot) {
;
}
while(rightPre>0 && a[--rightPre]>pivot) {
;
}
if(leftPre>=rightPre)
break;
else {
temp=a[leftPre];
a[leftPre]=a[rightPre];
a[rightPre]=temp;
}
}
return leftPre;
}
划分算法是由两个指针开始工作。两个指针分别指向数组的两头。在左边的指针 leftPre向右移动,而在右边的指针rightPre则向左移动。实际上,leftPre初始化时实在最左边数据的左边一位,rightPre初始化的时候是在最右边数据的右一位,这是因为在他们工作之前,他们都要分别加一减一。
当leftPre遇到比枢纽小的数据项时,它继续忘右移动,因为这个数据项的位置已经处于数组的正取一边了。但是当遇到比枢纽大的数据项时,它就会停下来。类似的 rightPre当遇到比枢纽大的数据项时继续左移,当遇到比枢纽小的数据项时,就会停下来。代码中的两个while循环 控制了这一过程:
while(leftPre<a.length-1 && a[++leftPre]<pivot) {
;
}
while(rightPre>0 && a[--rightPre]>pivot) {
;
}
第一个while循环 发现比枢纽大的数据时候退出。第二个循环发现比枢纽小的数据的时候退出。当两个循环都退出后,leftPre和rightPre,都指着数组错误一方的数据项,所以要交换两个数据项的位置。交换之后继续这个过程,当两个指针相遇的时候 过程结束,退出外部的while 循环。
快速排序:
为了理解快速排序,对于上边所描述的划分算法应该非常熟悉。快速排序算法本质上通过把一个数组划分成两个子数组,然后递归的调用自身为本身的每个子数组进行快速排序来实现的。但是对于这个基本的设计还需要进一步加工。算法还必须选择枢纽 以及对小的划分区域进行排序。下边是主要算法的简化代码, 理解简化代码后还要对其进行精益求精
public static void quickSort(int left,int right) {
if(left-right<=0)
return;
else {
int partition=partition(left,right);
quickSort(left,partition);
quickSort(partition+1,right);
}
}
正如大家看到的,有三个基本步骤:
1. 把数组或子数组划分成左边一组和右边一组
2. 调动自身对左边一组进行排序。
3. 调用自身对右边一组进行排序。
传递给quickSort方法的参数决定了要排序数组(或子数组)左右两端的位置,这个方法首先检查数组是否只包含一个数据项。如果只包含一个数据项,那么就定义数组已经有序了 ,方法立即返回这个是递归过程的终止条件。 如果数组包含两个或者更多的数据项 那就用partition方法对这个数组进行划分。
选择枢纽
那么问题来了, partition方法应该使用什么样的枢纽呢?以下是一些相关的思想:
. 应该选择一个具体的关键字的值作为枢纽,称这个数据项为pivot(枢纽)
. 可以选择任意一个数据项作为枢纽。为了简单,我们假设总是选择待划分的子数组的最右端的数据作为枢纽。
. 划分完之后如果枢纽被插入到左右子数组之间的分界处,那么枢纽就落在排序之后的最终位置了。
图7.9显示了用关键字为36的项作为枢纽的情况
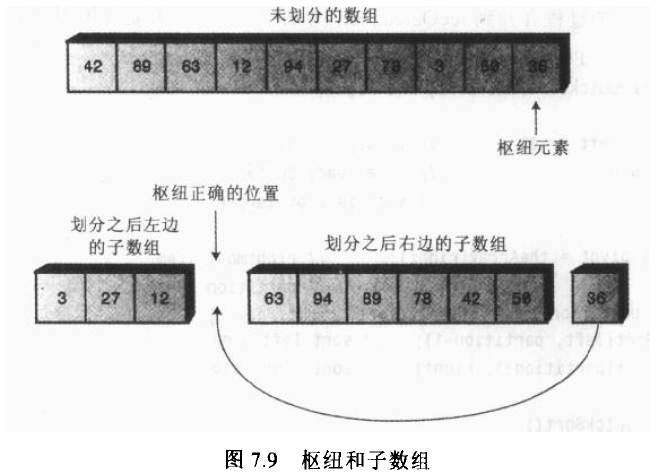
因为不能跟图一样把一个数组分开,所以这个图只是一个想象的情况,那怎么才能把枢纽移动到正确位置上来呢? 可以把右边子数组的所有数据项往右边移动一位,以腾出枢纽位置。但是这么做既低效又不必要。记住尽管右边子数组的数据项都大于枢纽, 但他们都还没有排序,所以他们可以在右边子数组内移动而没有影响。因此,为了简化枢纽插入正确位置的操作,只要交换右边子数组最左端的数据项(目前是63)和枢纽就可以了.。这个交换操作把枢纽放在了它正确的位置上,63调到了最右端,但是它仍然在比枢纽大的右端的子数组内,所以划分并没哟被打乱。如图7.10所示
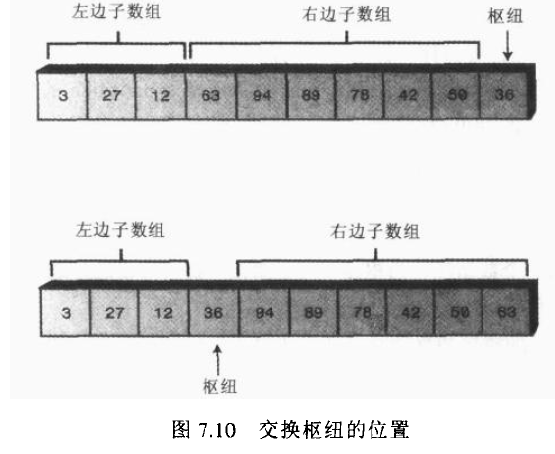
当枢纽被交换到分界的位置后,它落在了它最后应该在的位置。以后所有的操作或者发生在左边,或者发生在右边,枢纽都不需要动了。
为了把选择枢纽的过程合并到quickSort中,用一个明显的语句为枢纽赋值, 并把枢纽的值作为参数传入partition方法中,代码如下:
public static void quickSort(int left,int right) {
if(left-right<=0)
return;
else {
int pivot=a[right]
int partition=partition(left,right,pivot);
quickSort(left,partition);
quickSort(partition+1,right);
}
}
当使用选择数组最右端的数据项作为枢纽的方案时,需要修改partition方法,在划分的过程中,把最右端的数据排除在外,因为最右端的数据在划分过程完成之后应该在什么位置已经很清楚了(应该在分界位置)划分过程完成后还需要把数组最右端元素移动到划分点位置上。partition方法代码如下:
public static int partition(int left,int right,int pivot) {
int leftPre=left-1;
int rightPre=right;
int temp;
int temp1;
while(true) {
while(leftPre<right && a[++leftPre]<pivot) {
;
}
while(rightPre>0 && a[--rightPre]>pivot) {
;
}
if(leftPre>=rightPre) {
break;
}else {
temp=a[leftPre];
a[leftPre]=a[rightPre];
a[rightPre]=temp;
}
}
temp1 =a[leftPre];
a[leftPre]=a[right];
a[right]=temp1;
return leftPre;
}
快速排序整体测试代码如下:
public class Sort {
public static int [] a =new int[] {2,1,9,8,5,8,6};
public static void main(String[] args) {
quickSort();
//partition(0,a.length-1,6);
for(int i=0;i<a.length;i++) {
System.out.println("a["+i+"]="+a[i]);
}
}
public static void quickSort() {
recRuickSort(0,a.length-1);
}
public static void recRuickSort(int left,int right) {
if(right-left<=0)
return;
else {
int pivot=a[right];
int partition=partition(left,right,pivot);
recRuickSort(left,partition-1);
recRuickSort(partition+1,right);
}
}
public static int partition(int left,int right,int pivot) {
int leftPre=left-1;
int rightPre=right;
int temp;
int temp1;
while(true) {
while(leftPre<right && a[++leftPre]<pivot) {
;
}
while(rightPre>0 && a[--rightPre]>pivot) {
;
}
if(leftPre>=rightPre) {
break;
}else {
temp=a[leftPre];
a[leftPre]=a[rightPre];
a[rightPre]=temp;
}
}
temp1 =a[leftPre];
a[leftPre]=a[right];
a[right]=temp1;
return leftPre;
}
}
PS:
本文章参考《Java数据结构和算法(第二版)》 更详细内容请参考此书。谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号